Элемент дерева на который не ссылаются другие называется
По книге Laszlo
«Вычислительная геометрия и компьютерная графика на С++»
Двоичные деревья представляют эффективный способ поиска. Двоичное дерево представляет собой структурированную коллекцию узлов. Коллекция может быть пустой и в этом случае мы имеем пустое двоичное дерево. Если коллекция непуста, то она подразделяется на три раздельных семейства узлов: корневой узел n (или просто корень), двоичное дерево, называемое левым поддеревом для n, и двоичное дерево, называемое правым поддеревом для n. На рис. 1а узел, обозначенный буквой А, является корневым, узел В называется левым потомком А и является корнем левого поддерева А, узел С называется правым потомком А и является корнем правого поддерева А.
Рис. 1: Двоичное дерево с показанными внешними узллами (а) и без них (б)
Двоичное дерево на рис. 1а состоит из четырех внутренних узлов (обозначенных на рис. кружками) и пяти внешних (конечных) узлов (обозначены квадратами). Размер двоичного дерева определяется числом содержащихся в нем внутренних узлов. Внешние узлы соответствуют пустым двоичным деревьям. Например, левый потомок узла В — непустой (содержит узел D), тогда как правый потомок узла В — пустое дерево. В некоторых случаях внешние узлы обозначаются каким-либо образом, в других — на них совсем не ссылаются и они считаются пустыми двоичными деревьями (на рис. 16 внешние узлы не показаны).
Основанная на генеалогии метафора дает удобный способ обозначения узлов внутри двоичного дерева. Узел р является родителем (или предком) узла n, если n — потомок узла р. Два узла являются братьями, если они принадлежат одному и тому же родителю. Для двух заданных узлов n1 и nk таких, что узел nk принадлежит поддереву с корнем в узле n1, говорят, что узел nk является потомком узла n1, а узел n1 — предком узла nk. Существует уникальный путь от узла n1 вниз к каждому из потомков nk, a именно: последовательность узлов n1 и n2. nk такая, что узел ni является родителем узла ni+1 для i = 1, 2. k-1. Длина пути равна числу ребер (k-1), содержащихся в нем. Например, на рис. 1а уникальный путь от узла А к узлу D состоит из последовательности А, В, D и имеет длину 2.
Глубина узла n определяется рекурсивно:
| < 0 | если n — корневой узел |
| глубина (n) = | |
| < 1 + глубина (родителя (n)) | в противном случае |
Глубина узла равна длине уникального пути от корня к узлу. На рис. 1а узел А имеет глубину 0, а узел D имеет глубину, равную 2.
Высота узла n также определяется рекурсивно:
| < 0 | если n — внешний узел |
| высота (n) = | |
| < 1 + max( высота(лев(n)), высота(прав(n)) ) | в противном случае |
где через лев(n) обозначен левый потомок узла n и через прав(n) — правый потомок узла n. Высота узла n равна длине самого длинного пути от узла n вниз до внешнего узла поддерева n. Высота двоичного дерева определяется как высота его корневого узла. Например, двоичное дерево на рис. 1а имеет высоту 3, а узел D имеет высоту 1.
При реализации двоичных деревьев, основанной на точечном представлении, узлы являются объектами класса TreeNode.
template class TreeNode < protected: TreeNode *_lchild; TreeNode *_rchild; Т val; public: TreeNode(T); virtual ~TreeNode(void); friend class SearchTree; // возможные пополнения friend class BraidedSearchTree; // структуры >;
Элементы данных _lchild и _rchild обозначают связи текущего узла с левым и правым потомками соответственно, а элемент данных val содержит сам элемент.
Конструктор класса формирует двоичное дерево единичного размера — единственный внутренний узел имеет два пустых потомка, каждое из которых представлено нулем NULL:
template TreeNode::TreeNode(T v) : val(v), _lchild(NULL), _rchild (NULL)
Деструктор ~TreeNode рекурсивно удаляет оба потомка текущего узла (если они существуют) перед уничтожением самого текущего узла:
template TreeNode::~TreeNode(void)
Основное назначение двоичных деревьев заключается в повышении эффективности поиска. При поиске выполняются такие операции, как нахождение заданного элемента из набора различных элементов, определение наибольшего или наименьшего элемента в наборе, фиксация факта, что набор содержит заданный элемент. Для эффективного поиска внутри двоичного дерева его элементы должны быть организованы соответствующим образом. Например, двоичное дерево будет называться двоичным деревом поиска, если его элементы расположены так, что для каждого элемента n все элементы в левом поддереве n будут меньше, чем n, а все элементы в правом поддереве — будут больше, чем n. На рис. 2 изображены три двоичных дерева поиска, каждое из которых содержит один и тот же набор целочисленных элементов.
Рис. 2: Три двоичных дерева поиска с одним и тем же набором элементов
В общем случае существует огромное число двоичных деревьев поиска (различной формы) для любого заданного набора элементов.
Предполагается, что элементы располагаются в линейном порядке и, следовательно, любые два элемента можно сравнить между собой. Примерами линейного порядка могут служить ряды целых или вещественных чисел в порядке возрастания, а также слов или строк символов, расположенных в лексикографическом (алфавитном, или словарном) порядке. Поиск осуществляется путем обращения к функции сравнения для сопоставления любых двух элементов относительно их линейного порядка. В нашей версии деревьев поиска действие функции сравнения ограничено только явно определенными объектами деревьев поиска.
Также очень полезны функции для обращения к элементам дерева поиска и воздействия на них. Такие функции обращения могут быть полезны для вывода на печать, редактирования и доступа к элементу или воздействия на него каким-либо иным образом. Функции обращения не принадлежат деревьям поиска, к элементам одного и того же дерева поиска могут быть применены различные функции обращения.
Определим шаблон нового класса SearchTree для представления двоичного дерева поиска. Класс содержит элемент данных root, который указывает на корень двоичного дерева поиска (объект класса TreeNode) и элемент данных cmp, который указывает на функцию сравнения.
template class SearchTree < private: TreeNode *root; int (*) (T,T) cmp; TreeNode*_findMin(TreeNode *); void _remove(T, TreeNode * &); void _inorder(TreeNode *, void (*) (T) ); public: SearchTree (int(*) (Т, Т) ); ~SearchTree (void); int isEmpty (void); Т find(T); Т findMin(void); void inorder (void(*) (T) ); void insert(T); void remove(T); T removeMin (void); >;
Для упрощения реализации предположим, что элементами в дереве поиска являются указатели на объект заданного типа, когда шаблон класса SearchTree используется для создания действительного класса. Параметр Т передается в виде типа указателя.
Конструкторы и деструкторы
Конструктор SearchTree инициализирует элементы данных cmp для функции сравнения и root для пустого дерева поиска:
template SearchTree::SearchTree (int (*с) (Т, Т) ) : cmp(с), root (NULL)
Дерево поиска пусто только, если в элементе данных root содержится нуль (NULL) вместо разрешенного указателя:
template int SearchTree::isEmpty (void)
Деструктор удаляет все дерево путем обращения к деструктору корня:
template SearchTree::~SearchTree (void)
Поиск
Чтобы найти заданный элемент val, мы начинаем с корня и затем следуем вдоль ломаной линии уникального пути вниз до узла, содержащего val. В каждом узле n вдоль этого пути используем функцию сравнения для данного дерева на предмет сравнения val с элементом n->val, записанном в n. Если val меньше, чем n->val, то поиск продолжается, начиная с левого потомка узла n, если val больше, чем n->val, то поиск продолжается, начиная с правого потомка n, в противном случае возвращается значение n->val (и задача решена). Путь от корневого узла вниз до val называется путем поиска для val.
Этот алгоритм поиска реализуется в компонентной функции find, которая возвращает обнаруженный ею указатель на элемент или NULL, если такой элемент не существует в дереве поиска.
template T SearchTree::find (T val) < TreeNode *n = root; while (n) < int result = (*cmp) (val, n->val); if (result < 0) n = n->_lchild; else if (result > 0) n = n->_rchild; else return n->val; > return NULL; >
Этот алгоритм поиска можно сравнить с турниром, в котором участвуют некоторые кандидаты. В начале, когда мы начинаем с корня, в состав кандидатов входят все элементы в дереве поиска. В общем случае для каждого узла n в состав кандидатов входят все потомки n. На каждом этапе производится сравнение val с n->val. Если val меньше, чем n->val, то состав кандидатов сужается до элементов, находящихся в левом поддереве, а элементы в правом поддереве n, как и сам элемент n->val, исключаются из соревнования. Аналогичным образом, если val больше, чем n->val, то состав кандидатов сужается до правого поддерева n. Процесс продолжается до тех пор, пока не будет обнаружен элемент val или не останется ни одного кандидата, что означает, что элемент val не существует в дереве поиска.
Для нахождения наименьшего элемента мы начинаем с корня и прослеживаем связи с левым потомком до тех пор, пока не достигнем узла n, левый потомок которого пуст — это означает, что в узле n содержится наименьший элемент. Этот процесс также можно уподобить турниру. Для каждого узла n состав кандидатов определяется потомками узла n. На каждом шаге из состава кандидатов удаляются те элементы, которые больше или равны n->val и левый потомок n будет теперь выступать в качестве нового n. Процесс продолжается до тех пор, пока не будет достигнут некоторый узел n с пустым левым потомком и, полагая, что не осталось кандидатов меньше, чем n->val, и будет возвращено значение n->val.
Компонентная функция findMin возвращает наименьший элемент в данном дереве поиска, в ней происходит обращение к компонентной функции _findMin, которая реализует описанный ранее алгоритм поиска, начиная с узла n :
template T SearchTree::findMin (void) < TreeNode*n = _findMin (root); return (n ? n->val : NULL); > template TreeNode *SearchTree::_findMin (TreeNode *n) < if (n == NULL) return NULL; while (n->_lchild) n = n->_lchild; return n; >
Наибольший элемент в дереве поиска может быть найден аналогично, только отслеживаются связи с правым потомком вместо левого.
Симметричный обход
Обход двоичного дерева — это процесс, при котором каждый узел посещается точно только один раз. Компонентная функция inorder выполняет специальную форму обхода, известную как симметричный обход. Стратегия заключается сначала в симметричном обходе левого поддерева, затем посещения корня и потом в симметричном обходе правого поддерева. Узел посещается путем применения функции обращения к элементу, записанному в узле.
Компонентная функция inorder служит в качестве ведущей функции. Она обращается к собственной компонентной функции _inorder, которая выполняет симметричный обход от узла n и применяет функцию visit к каждому достигнутому узлу.
template void SearchTree::inorder (void (*visit) (Т) ) < _inorder (root, visit); >template void SearchTree::inorder (TreeNode *n, void(*visit) (T) < if (n) < _inorder (n->_lchild, visit); (*visit) (n->val); _inorder (n->_rchild, visit); > >
При симметричном обходе каждого из двоичных деревьев поиска, показанных на рис. 2, узлы посещаются в возрастающем порядке: 2, 3, 5, 7, 8. Конечно, при симметричном обходе любого двоичного дерева поиска все его элементы посещаются в возрастающем порядке. Чтобы выяснить, почему это так, заметим, что при выполнении симметричного обхода в некотором узле n элементы меньше, чем n->val посещаются до n, поскольку они принадлежат к левому поддереву n, а элементы больше, чем n->val посещаются после n, поскольку они принадлежат правому поддереву n. Следовательно, узел n посещается в правильной последовательности. Поскольку n — произвольный узел, то это же правило соблюдается для каждого узла.
Компонентная функция inorder обеспечивает способ перечисления элементов двоичного дерева поиска в отсортированном порядке. Например, если а является деревом поиска SearchTree для строк, то эти строки можем напечатать в лексикографическом порядке одной командой а.inorder(printstring). Для этого функция обращения printstring может быть определена как:
void printstring(char *s)
При симметричном обходе двоичного дерева узел, посещаемый после некоторого узла n, называется последователем узла n, а узел, посещаемый непосредственно перед n, называется предшественником узла n. Не существует никакого предшественника для первого посещаемого узла и никакого последователя для последнего посещаемого узла (в двоичном дереве поиска эти узлы содержат наименьший и наибольший элемент соответственно).
Включение элементов
Для включения нового элемента в двоичное дерево поиска вначале нужно определить его точное положение — а именно внешний узел, который должен быть заменен путем отслеживания пути поиска элемента, начиная с корня. Кроме сохранения указателя n на текущий узел мы будем хранить указатель р на предка узла n. Таким образом, когда n достигнет некоторого внешнего узла, р будет указывать на узел, который должен стать предком нового узла. Для осуществления включения узла мы создадим новый узел, содержащий новый элемент, и затем свяжем предок р с этим новым узлом (рис. 3).
Компонентная функция insert включает элемент val в это двоичное дерево поиска:
Рис. 3: Включение элемента в двоичное дерево поиска
template void SearchTree::insert(T val) < if (root == NULL) < root = new TreeNode(val); return; > else < int result; TreeNode*p, *n = root; while (n) < p = n; result = (*cmp) (val, p->val); if (result < 0) n = p->_lchild; else if (result > 0) n = p->_rchild; else return; > if (result < 0) p->_lchild = new TreeNode(val); else p-> rchild = new TreeNode(val); > >
Удаление элементов
Удаление элемента из двоичного дерева поиска гораздо сложнее, чем включение, поскольку может быть значительно изменена форма дерева. Удаение узла, у которого есть не более чем один непустой потомок, является равнительно простой задачей — устанавливается ссылка от предка узла на потомок. Однако ситуация становится гораздо сложнее, если у подлежащего удалению узла есть два непустых потомка: предок узла может быть связан с одним из потомков, а что делать с другим? Решение может заключаться не в удалении узла из дерева, а скорее в замене элемента, содержащегося в нем, на последователя этого элемента, а затем в удалении узла, содержащего этот последователь.
Рис. 4: Три ситуации, возникающие при удалении элемента из двоичного дерева поиска
Чтобы удалить элемент из дерева поиска, вначале мы отслеживаем путь поиска элемента, начиная с корня и вниз до узла n, содержащего элемент. В этот момент могут возникнуть три ситуации, показанные на рис. 4:
- Узел n имеет пустой левый потомок. В этом случае ссылка на n (записанная в предке n, если он есть) заменяется на ссылку на правого потомка n.
- У узла n есть непустой левый потомок, но правый потомок пустой. В этом случае ссылка вниз на n заменяется ссылкой на левый потомок узла n.
- Узел n имеет два непустых потомка. Найдем последователя для n (назовем его m), скопируем данные, хранящиеся в m, в узел n и затем рекурсивно удалим узел m из дерева поиска.
Очень важно проследить, как будет выглядеть результирующее двоичное дерево поиска в каждом случае. Рассмотрим случай 1. Если подлежащий удалению узел n, является левым потомком, то элементы, относящиеся к правому поддереву n будут меньше, чем у узла р, предка узла n. При удалении узла n его правое поддерево связывается с узлом р и элементы, хранящиеся в новом левом поддереве узла р конечно остаются меньше элемента в узле р. Поскольку никакие другие ссылки не изменяются, то дерево остается двоичным деревом поиска. Аргументы остаются подобными, если узел n является правым потомком, и они тривиальны, если n — корневой узел. Случай 2 объясняется аналогично. В случае 3 элемент v, записанный в узле n, перекрывается следующим большим элементом, хранящимся в узле m (назовем его w), после чего элемент w удаляется из дерева. В получающемся после этого двоичном дереве значения в левом поддереве узла n будут меньше w, поскольку они меньше v. Более того, элементы в правом поддереве узла n больше, чем w, поскольку (1) они больше, чем v, (2) нет ни одного элемента двоичного дерева поиска, лежащего между v и w и (3) из них элемент w был удален.
Заметим, что в случае 3 узел m должен обязательно существовать, поскольку правое поддерево узла n непустое. Более того, рекурсивный вызов для удаления m не может привести к срыву рекурсивного вызова, поскольку если узел m не имел бы левого потомка, то был бы применен случай 1, когда его нужно было бы удалить.
На рис. 5 показана последовательность операций удаления, при которой возникают все три ситуации. Напомним, что симметричный обход каждого дерева в этой последовательности проходит все узлы в возрастающем порядке, проверяя, что в каждом случае это двоичные деревья поиска.
Компонентная функция remove является общедоступной компонентной функцией для удаления узла, содержащего заданный элемент. Она обращается к собственной компонентной функции _remove, которая выполняет фактическую работу:
Рис. 5: Последовательность операций удаления элемента: (а) и (б) — Случай 1: удаление из двоичного дерева элемента 8; (б) и (в) — Случай 2: удаление элемента 5; (в) и (г) — Случай 3: удаление элемента 3
template void SearchTree::remove(Т val) < _remove(val, root); >template void SearchTree::_remove(Т val, TreeNode * &n) < if (n == NULL) return; int result = (*cmp) (val, n->val); if (result < 0) _remove(val, n->_lchild); else if (result > 0) _remove (val, n->_rchild); else < // случай 1 if (n->_lchild == NULL) < TreeNode*old = n; n = old->_rchild; delete old; > else if (n->_rchild == NULL < // случай 2 TreeNode *old = n; n = old->_lchild; delete old; > else < // случай 3 TreeNode *m = _findMin(n->_rchild); n->val = m->val; remove(m->val, n->_rchild); > > >
Параметр n (типа ссылки) служит в качестве псевдонима для поля ссылки, которое содержит ссылку вниз на текущий узел. При достижении узла, подлежащего удалению (old), n обозначает поле ссылки (в предке узла old), содержащее ссылку вниз на old. Следовательно команда n=old->_rchild заменяет ссылку на old ссылкой на правого потомка узла old.
Компонентная функция removeMin удаляет из дерева поиска наименьший элемент и возвращает его:
template Т SearchTree::removeMin (void)
Древовидная сортировка — способ сортировки массива элементов — реализуется в виде простой программы, использующей деревья поиска. Идея заключается в занесении всех элементов в дерево поиска и затем в интерактивном удалении наименьшего элемента до тех пор, пока не будут удалены все элементы. Программа heapSort(пирамидальная сортировка) сортирует массив s из n элементов, используя функцию сравнения cmp:
template void heapSort (T s[], int n, int(*cmp) (T,T) ) < SearchTreet(cmp); for (int i = 0; i
Также доступна реализация двоичного дерева на Си с базовыми функциями. Операторы typedef T и compGT следует изменить так, чтобы они соответствовали данным, хранимым в дереве. Каждый узел Node содержит указатели left, right на левого и правого потомков, а также указатель parent на предка. Собственно данные хранятся в поле data. Адрес узла, являющегося корнем дерева хранится в укзателе root, значение которого в самом начале, естественно, NULL. Функция insertNode запрашивает память под новый узел и вставляет узел в дерево, т.е. устанавливает нужные значения нужных указателей. Функция deleteNode, напротив, удаляет узел из дерева (т.е. устанавливает нужные значения нужных указателей), а затем освобождает память, которую занимал узел. Функция findNode ищет в дереве узел, содержащий заданное значение.
Обход дерева — JS: Деревья
Пошаговый перебор элементов дерева по связям между узлами-предками и узлами-потомками называется обходом дерева. Подразумевается, что в процессе обхода каждый узел будет затронут только один раз. По большому счёту, всё так же, как и в обходе любой коллекции, используя цикл или рекурсию. Только в случае деревьев способов обхода больше, чем просто слева направо и справа налево.
В данном курсе используется один порядок обхода — обход в глубину, так как он естественным образом получается при рекурсивном обходе. Об остальных способах можно прочитать в Википедии либо в рекомендуемых Хекслетом книгах.
Обход в глубину (Depth-first search)
Один из методов обхода дерева (графа в общем случае). Стратегия этого поиска состоит в том, чтобы идти вглубь одного поддерева настолько, насколько это возможно. Этот алгоритм естественным образом ложится на рекурсивное решение и получается сам собой.
Рассмотрим данный алгоритм на примере следующего дерева:
// * A // / | \ // B * C * D // /| |\ // E F G J Каждая нелистовая вершина обозначена звёздочкой. Обход начинается с корневого узла.
- Проверяем, есть ли у вершины A дети. Если есть, то запускаем обход рекурсивно для каждого ребёнка независимо;
- Внутри первого рекурсивного вызова оказывается следующее поддерево:
// B * // /| // E F Повторяем логику первого шага. Проваливаемся на уровень ниже.
- Внутри оказывается листовой элемент E . Функция убеждается, что у узла нет дочерних элементов, выполняет необходимую работу и возвращает результат наверх.
- Снова оказываемся в ситуации:
// B * // /| // E F В этом месте, как мы помним, рекурсивный вызов запускался на каждом из детей. Так как первый ребёнок уже был посещен, второй рекурсивный вызов заходит в узел F и выполняет там свою работу. После этого происходит возврат выше, и всё повторяется до тех пор, пока не дойдёт до корня.
const tree = mkdir('/', [ mkdir('etc', [ mkfile('bashrc'), mkfile('consul.cfg'), ]), mkfile('hexletrc'), mkdir('bin', [ mkfile('ls'), mkfile('cat'), ]), ]); const dfs = (tree) => // Распечатываем содержимое узла console.log(getName(tree)); // Если это файл, то возвращаем управление if (isFile(tree)) return; > // Получаем детей const children = getChildren(tree); // Применяем функцию dfs ко всем дочерним элементам // Множество рекурсивных вызовов в рамках одного вызова функции // называется древовидной рекурсией children.forEach(dfs); >; dfs(tree); // => / // => etc // => bashrc // => consul.cfg // => hexletrc // => bin // => ls // => cat Печать на экран в примере выше это лишь демонстрация. В реальности же нас интересует либо изменение дерева, либо агрегация данных по нему. Агрегацию данных рассмотрим позже, а сейчас разберём изменение.
Допустим, мы хотим реализовать функцию, которая меняет владельца для всего дерева, то есть всех директорий и файлов. Для этого нам придётся соединить две вещи: рекурсию, разобранную выше, и код обновления узлов, который изучался в прошлом уроке.
const changeOwner = (tree, owner) => const name = getName(tree); const newMeta = _.cloneDeep(getMeta(tree)); newMeta.owner = owner; if (isFile(tree)) // Возвращаем обновлённый файл return mkfile(name, newMeta); > // Дальше идет работа, если директория const children = getChildren(tree); // Ключевая строчка // Вызываем рекурсивное обновление каждого ребёнка const newChildren = children.map((child) => changeOwner(child, owner)); const newTree = mkdir(name, newChildren, newMeta); // Возвращаем обновлённую директорию return newTree; >; // Эту функцию можно обобщить до map (отображения), работающего с деревьями Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Динамические структуры данных

Тест. ПРименялся в МОУ СОШ №13 на уроке основы программирования.
Просмотр содержимого документа
«Динамические структуры данных»
Контрольная работа «Динамические структуры данных»
ЭЛЕМЕНТ ДЕРЕВА, КОТОРЫЙ ИМЕЕТ ПРЕДКА И ПОТОМКОВ, НАЗЫВАЕТСЯ
корнем
листом
узлом
промежуточным
СТРУКТУРА ДАННЫХ ПРЕДСТАВЛЯЕТ СОБОЙ
a) набор правил и ограничений, определяющих связи между отдельными элементами и группами данных
b) набор правил и ограничений, определяющих связи между отдельными элементами данных
c) набор правил и ограничений, определяющих связи между отдельными группами данных
d) некоторую иерархию данных
ПУТЬ(ЦИКЛ), КОТОРЫЙ СОДЕРЖИТ ВСЕ РЕБРА ГРАФА ТОЛЬКО ОДИН РАЗ, НАЗЫВАЕТСЯ
Эйлеровым
Гамильтоновым
декартовым
замкнутым
КАК НАЗЫВАЮТСЯ ПРЕДКИ УЗЛА, ИМЕЮЩИЕ УРОВЕНЬ НА ЕДИНИЦУ МЕНЬШЕ УРОВНЯ САМОГО УЗЛА
детьми
родителями
братьями
ЭЛЕМЕНТ ДЕРЕВА, НА КОТОРЫЙ НЕ ССЫЛАЮТСЯ ДРУГИЕ, НАЗЫВАЕТСЯ
корнем
листом
узлом
промежуточным
ГРАФ, СОДЕРЖАЩИЙ ДУГИ И РЕБРА, НАЗЫВАЕТСЯ.
ориентированным
неориентированным
простым
смешанным
С ПОМОЩЬЮ КАКОЙ СТРУКТУРЫ ДАННЫХ НАИБОЛЕЕ РАЦИОНАЛЬНО РЕАЛИЗОВАТЬ ОЧЕРЕДЬ ?
Стек
Список
Дек
ЭЛЕМЕНТT, НА КОТОРЫЙ НЕТ ССЫЛОК НАЗЫВАЕТСЯ:
корнем
промежуточным
терминальным (лист)
СТРУКТУРА ДАННЫХ РАБОТА С ЭЛЕМЕНТАМИ КОТОРОЙ ОРГАНИЗОВАНА ПО ПРИНЦИПУ FIFO (ПЕРВЫЙ ПРИШЕЛ — ПЕРВЫЙ УШЕЛ) ЭТО –
стек
дек
очередь
список
ЛИНЕЙНЫЙ СПИСОК, В КОТОРОМ ДОСТУПЕН ТОЛЬКО ПОСЛЕДНИЙ ЭЛЕМЕНТ, НАЗЫВАЕТСЯ
стеком
очередью
деком
массивом
кольцом
КАКИМ ОБРАЗОМ ОСУЩЕСТВЛЯЕТСЯ АЛГОРИТМ НАХОЖДЕНИЯ КРАТЧАЙШЕГО ПУТИ ОТ ВЕ
ШИНЫ S ДО ВЕРШИНЫ T
нахождение пути от вершины s до всех вершин графа
нахождение пути от вершины s до заданной вершины графа
нахождение кратчайших путей от вершины s до всех вершин графа
нахождение кратчайшего пути от вершины s до вершины t графа
нахождение всех путей от каждой вершины до всех вершин графа
ЛИНЕЙНЫЙ ПОСЛЕДОВАТЕЛЬНЫЙ СПИСОК, В КОТОРОМ ВКЛЮЧЕНИЕ ИСКЛЮЧЕНИЕ ЭЛЕМЕНТОВ ВОЗМОЖНО С ОБОИХ КОНЦОВ, НАЗЫВАЕТСЯ
стеком
очередью
деком
кольцевой очередью
в ЧЁМ ОТЛИЧИТЕЛЬНАЯ ОСОБЕННОСТЬ ДИНАМИЧЕСКИХ ОБЪЕКТОВ ?
порождаются непосредственно перед выполнением программы;
возникают уже в процессе выполнения программы;
задаются в процессе выполнения программы.
КАК РАССОРТИРОВАТЬ МАССИВ БЫСТРЕЕ, ПОЛЬЗУЯСЬ ПУЗЫРЬКОВЫМ МЕТОДОМ?
одинаково;
по возрачстанию элементов;
по убыванию элементов.
Нелинейная структура данных, реализующая отношение «многие ко многим»;
Линейная структура данных, реализующая отношение «многие ко многим»;
Нелинейная структура данных, реализующая отношение «многие к одному»;
Нелинейная структура данных, реализующая отношение «один ко многим»;
Линейная структура данных, реализующая отношение «один ко многим».
ЧЕМ ОТЛИЧАЕТСЯ КОЛЬЦЕВОЙ СПИСОК ОТ ЛИНЕЙНОГО ?
в кольцевом списке последний элемент является одновременно и первым;
в кольцевом списке указатель последнего элемента пустой;
в кольцевых списках последнего элемента нет ;
в кольцевом списке указатель последнего элемента не пустой.
КАКОВО ПРАВИЛО ВЫБОРКИ ЭЛЕМЕНТА ИЗ СТЕКА ?
первый элемент;
последний элемент;
любой элемент.
В ЧЁМ ОСОБЕННОСТИ ОЧЕРЕДИ ?
открыта с обеих сторон ;
открыта с одной стороны на вставку и удаление;
доступен любой элемент.
КАКИЕ ОПЕРАЦИИ ХАРАКТЕРНЫ ПРИ ИСПОЛЬЗОВАНИИ ОЧЕРЕДИ
добавление элемента в конец очереди
удаление элемента из начала очереди
добавление элемента в любое место очереди
удаление любого элемента из очереди
ЕСЛИ ДЕРЕВО СОДЕРЖИТ 1 МИЛЛИОН ВЕРШИН, ТО СКОЛЬКО СРАВНЕНИЙ В САМОМ ПЛОХОМ СЛУЧАЕ ПОТРЕБУЕТСЯ ДЛЯ ПОИСКА ВЕРШИНЫ
Элемент дерева на который не ссылаются другие называется
Теоретические сведения: Нелинейные связные структуры






Односвязный список всегда линейный. Двусвязный список может и не быть линейным, если второй указатель каждого элемента списка задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому первым указателем элемента. В еще более общем случае каждый элемент связного списка может содержать произвольное конечное число связок, одинаковое или разное в различных элементах. В результате такого обобщения получается многосвязный список, каждый элемент которого входит одновременно во столько разных односвязных списков, сколько имеется связок в соответствующем элементе. При этом не обязательно чтобы каждый элемент непременно входил во все односвязные списки. Такой многосвязный список как бы прошит в разных направлениях многими связками. Поэтому многосвязные списки иногда называют прошитыми списками. Используется также еще одно название многосвязных списков — плексы.
Наиболее общий вид многосвязной структуры — многосвязная структура, которая характеризуется следующими свойствами:
1. Каждый элемент структуры содержит произвольное число направленных связок с другими элементами (или ссылок на другие элементы).
2. С каждым элементом может связываться произвольное число других элементов (т.е. каждый элемент может быть объектом ссылки произвольного числа других элементов).
3. Каждая связка в структуре имеет не только направление, но и вес.
Такую многосвязную структуру называют сетевой структурой или сетью. Логически сеть эквивалентна взвешенному ориентированному графу общего вида, и поэтому вместо термина “сеть” часто употребляется термин ”графовая структура” или просто “граф”, а вместо термина “элемент” термин “узел”.
Сетевые структуры широко применяются при организации банков данных, систем управления базами данных, в системах программ имитационного моделирования сложных комплексов и т.д.
Сетевые структуры — весьма общий и гибкий класс связных списков. Рассмотрим частные случаи многосвязных списков — древовидные структуры или просто деревья.
Деревом называется сетевая структура, которая характеризуется следующими свойствами:
1. Существует единственный элемент, или узел, на который не ссылается никакой другой элемент и который называется корнем.
2. Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
3. На каждый элемент, кроме корня, имеется единственная ссылка, т.е. каждый элемент адресуется единственным указателем.
Определенная таким образом структура называется также корневым деревом. Название “дерево” проистекает из логической эквивалентности древовидной структуры абстрактному дереву в теории графов. Линия связи между парой узлов дерева называется ветвью. Те узлы, которые не ссылаются ни на какие другие узлы дерева, называются листьями. Узел, ни являющийся листом или корнем, считается промежуточным, или узлом ветвления. Если в дереве узел X ссылается на узел Y, то X называется ”родителем”, а Y — его “сыном ”. Все узлы с общим родителем являются “братьями”. Число сыновей у родителя X — степень исхода узла X. При графическом представлении дерева упорядоченность сыновей любого родителя обычно задается изображением узлов — сыновей в порядке убывания их старшинства слева направо.
Если число сыновей у каждого родителя не больше m — для каждого узла, то соответствующее дерево называется m-арным деревом. Если степень исхода равна m или нулю для каждого узла, то дерево называется полным m-арным деревом. Обычно дерево представляется в машинной памяти в форме многосвязного списка, в котором каждый указатель соответствует дуге. Это представление называется естественным представлением дерева. В одной из наиболее общих разновидностей представления каждому узлу дерева ставится в соответствие элемент многосвязного списка, причем в каждом элементе отводятся поля: поле данных, поле степени исхода, поле указателей, число которых равно степени исхода.
Частный случай дерева — бинарное дерево. Бинарным деревом называется дерево с m = 2. любое m-арное дерево может быть преобразовано в эквивалентное ему бинарное дерево, которое проще исходного с точки зрения изучения, представления в памяти и обработке. Для этого сначала в каждом узле исходного дерева вычеркиваем все ветви, кроме самой левой, которая соответствует ссылке на старшего сына, после этого соединяем горизонтальными ветвями те узлы одного уровня, которые братьями в исходном дереве.
Важнейшие операции над бинарными деревьями: добавление и исключение некоторого поддерева, обход узлов. Обход осуществляется: обходом сверху (шаги выполняются в порядке 1, 2, 3), обход слева направо (2, 1, 3) и обход снизу (2, 3, 1). Можно существенно ускорить операцию обхода, используя прошивки. Это позволит обойтись без стека, требуемого при обходе непрошитого дерева. Вместо пустых указателей можно поместить вспомогательные связки, которые называются прошивками.
В отличие от основных структурных связок, каждая прошивка адресует предшествующий или последующий узел дерева в выбранной схеме обхода.
Если прошивка находится в поле левого указателя, то она адресует предыдущий узел дерева, а прошивка в поле правого указателя адресует следующий узел в выбранной схеме обхода.
При исключении элемента проблема возврата элементов многосвязной списковой структуры в свободный список может решаться разными методами. Наиболее известны: метод счетчика (после каждый операции исключения элемента делается проверка, остался ли этот элемент хотя бы в каком-нибудь одном функциональном списке, и в случае отрицательного ответа элемент присоединяется к свободному списку), метод сборки мусора (освободившийся элемент как бы “повисает ”до тех пор, пока не будет исчерпан свободный список. После этого запускается процедура сборки мусора, которая отыскивает все освободившиеся к этому времени элементы и включает их в свободный список).
Структурная организация данных
Информация, представленная в формализованном виде, пригодном для автоматизированной ее обработки, хранения и передачи, называются данными. С точки зрения программиста данные — это часть программы совокупность значений определенных ячеек памяти преобразование которых осуществляет код. С точки зрения компилятора процессора операционной системы это совокупность ячеек памяти, обладающих определёнными свойствами.
Как правило, данные имеют форму чисел, литер, текстов, символов и более сложных структур типа последовательностей, списков и деревьев и др.
Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. Структура данных — организационная схема записи или массива, в соответствии с которой упорядочены данные, с тем чтобы их можно было интерпретировать и выполнять над ними определенные операции.
Структура данных — это исполнитель, который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск и т.д. Структура данных поддерживает определенный порядок доступа к ним. Структуру данных можно рассматривать как своего рода склад или библиотеку. При описании структуры данных нужно перечислить набор действий, которые возможны для нее, и четко описать результат каждого действия.
Структура данных определяет их семантику, а также способы организации и управления ими. Структура данных и алгоритмы служат тем материалом, из которого строятся программы.
Понятие «физическая структура данных” отражает способ физического представления данных в памяти машины. Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или логической структурой. Различаются простые (базовые, примитивные) структуры (типы) данных и интегрированные (структурированные, композитные). Простыми называются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. Для физической структуры можно заранее сказать, каков будет размер данного простого типа и какова структура его размещения в памяти. С логической точки зрения простые данные являются неделимыми единицами.
Интегрированными называются такие структуры данных, составными частями которых являются другие структуры данных — простые или в свою очередь интегрированные. Интегрированные структуры данных конструируются программистом с использованием средств интеграции данных, предоставляемых языками программирования.
В зависимости от отсутствия или наличия явно заданных связей между элементами данных следует различать несвязныеструктуры (векторы, массивы, строки, стеки, очереди) и связныеструктуры (связные списки).
Классификация структур данных по признаку изменчивости. Важный признак структуры данных — ее изменчивость, т.е. изменение числа элементов и (или) связей между элементами структуры. В определении изменчивости структуры не отражен факт изменения значений элементов данных, поскольку в этом случае все структуры
данных имели бы свойство изменчивости. По признаку изменчивости различают структуры статические, полустатические, динамические и файловые. Классификация структур данных по признаку изменчивости приведена на рис. 1.

Рис. 1 Классификация структур данных
Базовые структуры данных, статические, полустатические и динамические характерны для оперативной памяти и часто называются оперативными структурами. Файловые структуры соответствуют структурам данных для внешней памяти.
Простые структуры данных называют также примитивными или базовыми структурами. Эти структуры служат основой для построения более сложных структур. В языках программирования простые структуры описываются простыми (базовыми) типами. К таким типам относятся: числовые, битовые, логические, символьные, перечисляемые, интервальные, указатели.
Приведем определения статических структур. В этих структурах количество элементов строго фиксировано.
Вектор (одномерный массив) — структура данных с фиксированным числом элементов одного и того же типа. Каждый элемент вектора имеет уникальный в рамках заданного вектора номер. Обращение к элементу вектора выполняется по имени вектора и номеру требуемого элемента.
Массив — такая структура данных, которая характеризуется:
· фиксированным набором элементов одного и того же типа;
· каждый элемент имеет уникальный набор значений индексов;
· количество индексов определяют мерность массива, например, два индекса — двумерный массив, три индекса — трехмерный массив, один индекс — одномерный массив или вектор;
· обращение к элементу массива выполняется по имени массива и значениям индексов для данного элемента.
Множество — структура данных, которая представляет собой набор неповторяющихся данных одного и того же типа. Множество может принимать все значения базового типа. Базовый тип не должен превышать 256 возможных значений.
Запись — конечное упорядоченное множество полей, характеризующихся различным типом данных.
Таблица — последовательность записей, которые имеют одну и ту же организацию. С физической точки зрения таблица представляет собой вектор, элементами которого являются записи. Характерной логической особенностью таблиц является то, что доступ к элементам таблицы производится не по номеру (индексу), а по ключу — по значению одного из свойств объекта, описываемого записью-элементом таблицы. Ключ — это свойство, идентифицирующее данную запись во множестве однотипных записей. Как правило, к ключу предъявляется требование уникальности в данной таблице.
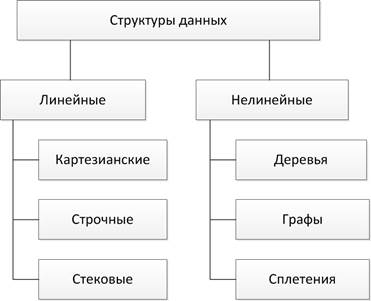
Рис 2. Структура данных по признаку упорядоченности
Важный признак структуры данных — характер упорядоченности ее элементов. По этому признаку структуры можно делить на линейные и нелинейные структуры (см. рис.2). В линейных структурах связи между элементами не зависят от какого-либо условия. В нелинейных структурах связи между элементами зависят от выполнения определенного условия.
Картезианские (прямоугольные) структуры включают в себя множество, матрицу, вектор, структуру, имеющую вид прямоугольных таблиц.
Строчные структуры (типа ряда) — одномерные, динамически изменяемые структуры данных, различающиеся способами включения и исключения элементов. К ним относятся: стек, дек, очередь, строка.
Стек — такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека — магазин и очередь, функционирующая по принципу LIFO (Last — In — First- Out — «последним пришел — первым исключается»).
ОчередьюFIFO (First — In — First- Out — «первым пришел — первым исключается») называется такой последовательный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение — с другой стороны (называемой началом или головой очереди). Основные операции над очередью — те же, что и над стеком — включение, исключение, определение размера, очистка, неразрушающее чтение.
Дек — особый вид очереди. Дек (от англ. deq — double ended queue,T.e очередь с
двумя концами) — это такой последовательный список, в котором как включение, так и исключение элементов может осуществляться с любого из двух концов списка. Применительно к деку целесообразно говорить не о начале и конце, а о левом и правом конце.
Строка — это линейно упорядоченная последовательность символов, принадлежащих конечному множеству символов, называемому алфавитом.
Строки обладают следующими важными свойствами:
· их длина, как правило, переменна, хотя алфавит фиксирован;
· обычно обращение к символам строки идет с какого-нибудь одного конца
последовательности, т.е важна упорядоченность этой последовательности, а не ее индексация; в связи с этим свойством строки часто называют также цепочками;
· чаще всего целью доступа к строке является не отдельный ее элемент (хотя это тоже не исключается), а некоторая цепочка символов в строке.
Говоря о строках, обычно имеют в виду текстовые строки — строки, состоящие из
символов, входящих в алфавит какого-либо выбранного языка, цифр, знаков
препинания и других служебных символов. Базовыми операциями над строками
являются: определение длины строки; присваивание строк; конкатенация (сцепление) строк; выделение подстроки; поиск вхождения.
К нелинейным структурам относятся: деревья, графы, сплетения.
Дерево — это граф, который характеризуется следующими свойствами:
Существует единственный элемент (узел или вершина), на который не ссылается никакой другой элемент — и который называется корнем
Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
На каждый элемент, кроме корня, имеется единственная ссылка, т.е. каждый элемент адресуется единственным указателем.
Название «дерево» проистекает из логической эквивалентности древовидной структуры абстрактному дереву в теории графов. Линия связи между парой узлов дерева называется обычно ветвью. Те узлы, которые не ссылаются ни на какие другие узлы дерева, называются листьями (или терминальными вершинами). Узел, не являющийся листом или корнем, считается промежуточным или узлом ветвления (нетерминальной или внутренней вершиной).
Граф — это сложная нелинейная многосвязная динамическая структура, отображающая свойства и связи сложного объекта.
Многосвязная структура обладает следующими свойствами:
1. на каждый элемент (узел, вершину) может быть произвольное количество ссылок;
2. каждый элемент может иметь связь с любым количеством других элементов;
3. каждая связка (ребро, дуга) может иметь направление и вес.
В узлах графа содержится информация об элементах объекта. Связи между узлами задаются ребрами графа. Ребра графа могут иметь направленность, показываемую стрелками, тогда они называются ориентированными, ребра без стрелок — неориентированные.
Сплетение (многосвязанный список, плекс) — это нелинейная структура данных, объединяющая такие понятия, КПК дерево, граф и списковые структуры. У каждого элемента имеется несколько полей с указателями на другие элементы того же сплетения.
В зависимости от характера взаимного расположения элементов в памяти линейные структуры можно разделить на структуры с последовательным распределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с произвольным связным распределением элементов в памяти (односвязные, двусвязные списки). Пример нелинейных структур — многосвязные списки, деревья, графы.
В языках программирования понятие «структуры данных” тесно связано с понятием «типы данных». Любые данные, т.е. константы, переменные, значения функций или выражения, характеризуются своими типами.
Информация по каждому типу однозначно определяет:
1. структуру хранения данных указанного типа, т.е. выделение памяти и представление данных в ней, с одной стороны, и интерпретирование двоичного представления, с другой;
2. множество допустимых значений, которые может иметь тот или иной объект описываемого типа;
3. множество допустимых операций, которые применимы к объекту описываемого типа.
Концепция типа данных появилась в языках программирования высокого уровня как естественное отражение того факта, что обрабатываемые программой данные могут иметь различные множества допустимых значений, храниться в памяти компьютера различным образом, занимать различные объёмы памяти и обрабатываться с помощью различных команд процессора.
Над любыми структурами данных могут выполняться четыре общие операции: создание, уничтожение, выбор (доступ), обновление.
Операции с массивами. Типичными операциями при работе с массивами являются:
· поиск максимального или минимального элемента массива;
· поиск заданного элемента массива;
Ввод массива. Чтобы заполнить массив данными, существует несколько способов:
· непосредственное присваивание значений элементам;
· генерация и присваивание значений с помощью функции random;
· ввод значений элементов с клавиатуры;
Вывод массива. Под выводом массива понимается вывод на экран монитора (в диалоговое окно) значений элементов массива.
Алгоритмы сортировки одномерных массивов и поиска элементовСуществует большое количество алгоритмов сортировки массивов, но все они базируются на трех основных: сортировка обменом; сортировка выбором; сортировка вставкой.
1. Сортировка методом «пузырька».
В основе алгоритма лежит обмен соседних элементов массива. Каждый элемент массива, начиная с первого, сравнивается со следующим, и если он больше следующего, то элементы меняются местами. Таким образом, элементы с меньшим значением продвигаются к началу массива (всплывают), а элементы с большим значением — к концу массива (тонут). Поэтому данный метод сортировки обменом иногда называют методом «пузырька». Этот процесс повторяется столько раз, сколько элементов в массиве, минус единица.
Иллюстрированный самоучитель по задачам и примерам Assembler
То, что неясно, следует выяснить.
То, что трудно творить, следует делать с великой настойчивостью.
Конфуций
Деревом называется сетевая структура, обладающая следующими свойствами:
- среди всех узлов существует один, который не имеет ребер, входящих от других узлов, – этот узел называется корнем;
- все узлы, за исключением корня, имеют одно и только одно входящее ребро;
- ко всем узлам дерева имеется путь, начало которого лежит в корне дерева.
Графически дерево изображают так, как показано на рис. 2.18.
Рис. 2.18. Изображение дерева и соответствующего ему связного списка
Следуя терминологии дерева, можно ввести некоторые определения, касающиеся его структуры. Ребра, соединяющие смежные узлы дерева, называются ветвями. Оконечные узлы дерева, которые не ссылаются на другие узлы, называются листьями. Другие узлы дерева, за исключением корня, называются узлами ветвления. Две смежные вершины дерева состоят в «родственных» отношениях. Вершина X, находящаяся на более высоком уровне дерева по отношению к вершине Y, называется отцом. Соответственно, вершина Y по отношению к X называется сыном. Если вершина X имеет несколько сыновей, то по отношению друг к другу последних называются братьями. В принципе, вместо этих терминов можно использовать следующие: родитель, потомок и т. п. Классификация деревьев производится по степени исхода ветвей из узлов деревьев. Дерево называется m-арным, если степень исхода его узлов не превышает значения m.
В практических приложениях широко используется специальный класс деревьев – бинарные деревья. Бинарное дерево – m-арное дерево при m = 2. Это означает, что степень исхода его вершин не превышает 2. В случае когда m равно 0 или 2, имеет место полное бинарное дерево. Важно то, что любое m-арное дерево можно преобразовать в эквивалентное ему бинарное дерево. В свою очередь, в силу ограничений по степени исхода вершин бинарное дерево легче представлять в памяти и обрабатывать. По этой причине мы основное внимание уделим работе с бинарными деревьями.
Динамические структуры данных

Тест. ПРименялся в МОУ СОШ №13 на уроке основы программирования.
Просмотр содержимого документа
«Динамические структуры данных»
Контрольная работа «Динамические структуры данных»
ЭЛЕМЕНТ ДЕРЕВА, КОТОРЫЙ ИМЕЕТ ПРЕДКА И ПОТОМКОВ, НАЗЫВАЕТСЯ
корнем
листом
узлом
промежуточным
СТРУКТУРА ДАННЫХ ПРЕДСТАВЛЯЕТ СОБОЙ
a) набор правил и ограничений, определяющих связи между отдельными элементами и группами данных
b) набор правил и ограничений, определяющих связи между отдельными элементами данных
c) набор правил и ограничений, определяющих связи между отдельными группами данных
d) некоторую иерархию данных
ПУТЬ(ЦИКЛ), КОТОРЫЙ СОДЕРЖИТ ВСЕ РЕБРА ГРАФА ТОЛЬКО ОДИН РАЗ, НАЗЫВАЕТСЯ
Эйлеровым
Гамильтоновым
декартовым
замкнутым
КАК НАЗЫВАЮТСЯ ПРЕДКИ УЗЛА, ИМЕЮЩИЕ УРОВЕНЬ НА ЕДИНИЦУ МЕНЬШЕ УРОВНЯ САМОГО УЗЛА
детьми
родителями
братьями
ЭЛЕМЕНТ ДЕРЕВА, НА КОТОРЫЙ НЕ ССЫЛАЮТСЯ ДРУГИЕ, НАЗЫВАЕТСЯ
корнем
листом
узлом
промежуточным
ГРАФ, СОДЕРЖАЩИЙ ДУГИ И РЕБРА, НАЗЫВАЕТСЯ.
ориентированным
неориентированным
простым
смешанным
С ПОМОЩЬЮ КАКОЙ СТРУКТУРЫ ДАННЫХ НАИБОЛЕЕ РАЦИОНАЛЬНО РЕАЛИЗОВАТЬ ОЧЕРЕДЬ ?
Стек
Список
Дек
ЭЛЕМЕНТT, НА КОТОРЫЙ НЕТ ССЫЛОК НАЗЫВАЕТСЯ:
корнем
промежуточным
терминальным (лист)
СТРУКТУРА ДАННЫХ РАБОТА С ЭЛЕМЕНТАМИ КОТОРОЙ ОРГАНИЗОВАНА ПО ПРИНЦИПУ FIFO (ПЕРВЫЙ ПРИШЕЛ — ПЕРВЫЙ УШЕЛ) ЭТО –
стек
дек
очередь
список
ЛИНЕЙНЫЙ СПИСОК, В КОТОРОМ ДОСТУПЕН ТОЛЬКО ПОСЛЕДНИЙ ЭЛЕМЕНТ, НАЗЫВАЕТСЯ
стеком
очередью
деком
массивом
кольцом
КАКИМ ОБРАЗОМ ОСУЩЕСТВЛЯЕТСЯ АЛГОРИТМ НАХОЖДЕНИЯ КРАТЧАЙШЕГО ПУТИ ОТ ВЕ
ШИНЫ S ДО ВЕРШИНЫ T
нахождение пути от вершины s до всех вершин графа
нахождение пути от вершины s до заданной вершины графа
нахождение кратчайших путей от вершины s до всех вершин графа
нахождение кратчайшего пути от вершины s до вершины t графа
нахождение всех путей от каждой вершины до всех вершин графа
ЛИНЕЙНЫЙ ПОСЛЕДОВАТЕЛЬНЫЙ СПИСОК, В КОТОРОМ ВКЛЮЧЕНИЕ ИСКЛЮЧЕНИЕ ЭЛЕМЕНТОВ ВОЗМОЖНО С ОБОИХ КОНЦОВ, НАЗЫВАЕТСЯ
стеком
очередью
деком
кольцевой очередью
в ЧЁМ ОТЛИЧИТЕЛЬНАЯ ОСОБЕННОСТЬ ДИНАМИЧЕСКИХ ОБЪЕКТОВ ?
порождаются непосредственно перед выполнением программы;
возникают уже в процессе выполнения программы;
задаются в процессе выполнения программы.
КАК РАССОРТИРОВАТЬ МАССИВ БЫСТРЕЕ, ПОЛЬЗУЯСЬ ПУЗЫРЬКОВЫМ МЕТОДОМ?
одинаково;
по возрачстанию элементов;
по убыванию элементов.
Нелинейная структура данных, реализующая отношение «многие ко многим»;
Линейная структура данных, реализующая отношение «многие ко многим»;
Нелинейная структура данных, реализующая отношение «многие к одному»;
Нелинейная структура данных, реализующая отношение «один ко многим»;
Линейная структура данных, реализующая отношение «один ко многим».
ЧЕМ ОТЛИЧАЕТСЯ КОЛЬЦЕВОЙ СПИСОК ОТ ЛИНЕЙНОГО ?
в кольцевом списке последний элемент является одновременно и первым;
в кольцевом списке указатель последнего элемента пустой;
в кольцевых списках последнего элемента нет ;
в кольцевом списке указатель последнего элемента не пустой.
КАКОВО ПРАВИЛО ВЫБОРКИ ЭЛЕМЕНТА ИЗ СТЕКА ?
первый элемент;
последний элемент;
любой элемент.
В ЧЁМ ОСОБЕННОСТИ ОЧЕРЕДИ ?
открыта с обеих сторон ;
открыта с одной стороны на вставку и удаление;
доступен любой элемент.
КАКИЕ ОПЕРАЦИИ ХАРАКТЕРНЫ ПРИ ИСПОЛЬЗОВАНИИ ОЧЕРЕДИ
добавление элемента в конец очереди
удаление элемента из начала очереди
добавление элемента в любое место очереди
удаление любого элемента из очереди
ЕСЛИ ДЕРЕВО СОДЕРЖИТ 1 МИЛЛИОН ВЕРШИН, ТО СКОЛЬКО СРАВНЕНИЙ В САМОМ ПЛОХОМ СЛУЧАЕ ПОТРЕБУЕТСЯ ДЛЯ ПОИСКА ВЕРШИНЫ
Похожие публикации:
- Файл gpx чем открыть онлайн
- Чем erp отличается от упп
- Что включает в себя постановка задачи и предпроектные исследования
- Что такое упд на вайлдберриз