Всегда ли хорош Index Only Scan?
Среди применяемых в PostgreSQL методов доступа к данным Index Only Scan стоит особняком, считаясь у многих разработчиков «волшебной пилюлей» для ускорения работы запроса — мол, «Index Scan — плохо, Index Only Scan — хорошо, как только получим его в плане — все станет замечательно«.
Как минимум, это утверждение неверно. Как максимум, при определенных условиях может вызвать проблемы чуть ли не на ровном месте.
Как PostgreSQL хранит данные
Для начала, вспомним, что в PostgreSQL данные таблицы и индексы для нее лежат одинаково, хотя и в разных файлах. Организация физического хранения данных в PostgreSQL, в предельно упрощенном виде выглядит так:
- каждая таблица или индекс — отдельный файл данных ( pg_class.relfilenode )
- каждый файл делится на физические сегменты, не превышающие 1GB
- каждый сегмент состоит из последовательности страниц данных по (обычно) 8KB
- страница данных содержит непосредственно набор записей
- дополнительно к файлу данных используются два файла с картами: Free Space Map (FSM) и Visibility Map (VM)
Вот как раз с последней и могут возникать проблемы:
Карта может отражать реальные данные с запаздыванием в том смысле, что мы уверены, что в случаях, когда установлен бит, известно, что условие верно, но если бит не установлен, оно может быть верным или неверным. Биты карты видимости устанавливаются только при очистке, а сбрасываются при любых операциях, изменяющих данные на странице.
Как работает Index Scan
Для поиска необходимой записи Index Scan :
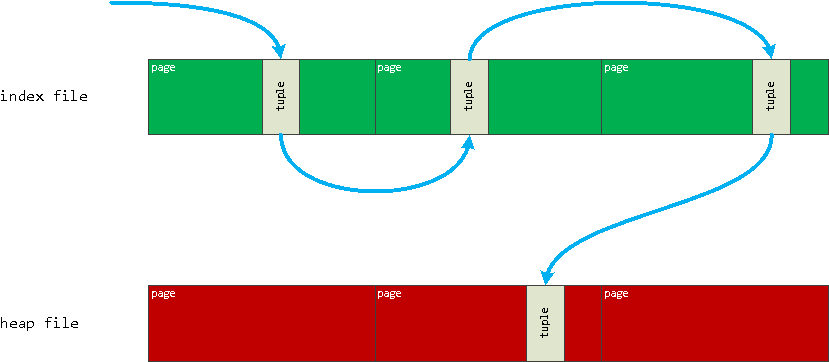
- переходит по записям структуры btree-дерева в файле индекса, пока не дойдет до «листа», указывающего на файл таблицы
- извлекает из файла таблицы необходимую запись, удостоверяясь в ее «видимости» для текущей транзакции (по значениям xmin/xmax )
Как работает Index Only Scan
Index Only Scan может быть выбран в качестве способа извлечения записей в случае чтения запросом только полей, которые присутствуют в самом индексе — его ключах или INCLUDE-списке.
По этой причине использование SELECT * FROM . почти всегда «ломает» возможность использования Index Only Scan .
Для поиска необходимой записи Index Only Scan :
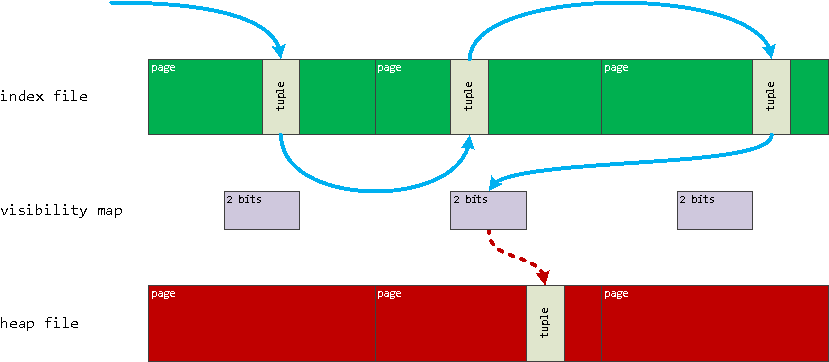
- переходит по записям структуры btree-дерева в файле индекса, пока не дойдет до «листа», указывающего на файл таблицы
- проверяет бит «видимости всех записей» нужной страницы с помощью Visibility Map
- если бит не взведен, ровно как «обычный» Index Scan , извлекает из файла таблицы необходимую запись, удостоверяясь в ее «видимости» для текущей транзакции (по значениям xmin/xmax )
Понятно, что со временем для большинства страниц данных в базе бит полной видимости будет взведен, и «в среднем» проверка одного бита VM существенно дешевле, чем извлечение целой записи из файла таблицы.
Проблемы Index Only Scan
Однако, в силу алгоритма заполнения VM, существуют ситуации, когда Index Only Scan всегда придется извлекать запись из таблицы, постоянно проигрывая «обычному» Index Scan на необходимости проверки данных VM.
Процитирую документацию еще раз:
Биты карты видимости устанавливаются только при очистке, а сбрасываются при любых операциях, изменяющих данные на странице.
Из этого предложения следует ровно два паттерна, когда Index Only Scan будет заведомо неэффективен:
- извлечение «свежевставленных» записей, которые еще не успел пройти [auto]VACUUM
- наличие даже редких UPDATE/DELETE по произвольно разбросанным по страницам записям
Рассмотрим на простом примере «типа-мониторинга», когда у нас есть метрика ( m ) и метка времени ( ts ):
-- создаем исходную таблицу с 1M случайных записей CREATE TABLE ios_orig AS SELECT (random() * 1e3)::integer m -- метрика , now() - (random() * '1 msec'::interval) ts -- метка времени FROM generate_series(1, 1e6); -- копируем данные в тестовую таблицу CREATE TABLE ios_test AS TABLE ios_orig; -- создаем индекс, по которому будем искать CREATE INDEX ON ios_test(m, ts);Попробуем отобрать часть записей по условию, четко ложащемуся на индекс:
EXPLAIN (ANALYZE, BUFFERS, COSTS OFF) SELECT m , ts FROM ios_test WHERE m > 900 ORDER BY m;Heap Fetches как признак беды
. и получаем время выполнения дольше 80ms:
Index Only Scan using ios_test_m_ts_idx on ios_test (actual time=0.032..75.224 rows=99094 loops=1) Index Cond: (m > 900) Heap Fetches: 99094 Buffers: shared hit=99478 Planning Time: 0.084 ms Execution Time: 80.838 msОбратите внимание на строку Heap Fetches — ровно она показывает нам количество записей, которые пришлось «достать» из файла таблицы.
Поскольку в нашем случае записи размазаны «ровным слоем», то пришлось вычитывать по отдельной странице данных для каждой из них.
Index Only Scan vs Index Scan
Давайте попробуем заставить PostgreSQL воспользоваться «обычным» Index Scan :
SET enable_indexonlyscan = FALSE;Index Scan using ios_test_m_ts_idx on ios_test (actual time=0.028..64.810 rows=99094 loops=1) Index Cond: (m > 900) Buffers: shared hit=99478 Planning Time: 0.091 ms Execution Time: 70.010 msМы вычитали ровно столько же данных, но сделали это почти на 15% быстрее! А ведь вся разница — лишь в необходимости проверки VM.
Когда Index Only Scan все-таки выигрывает
Давайте все же приведем Visibility Map в порядок (для для этого нам необходимо прогнать VACUUM ) и сбросим запрет использования Index Only Scan :
VACUUM ios_test; RESET enable_indexonlyscan;Index Only Scan using ios_test_m_ts_idx on ios_test (actual time=0.026..15.500 rows=99094 loops=1) Index Cond: (m > 900) Heap Fetches: 0 Buffers: shared hit=400 Planning Time: 0.080 ms Execution Time: 20.831 msВот теперь все отлично Heap Fetches: 0 , а время выполнения запроса сократилось в 4 раза!
Подведем промежуточные итоги:
Использование INDEX FAST FULL SCAN
Почему в этом запросе используется INDEX RANGE SCAN, а не INDEX FAST FULL SCAN ведь все значения есть в самом к индексе и их можно выбрать оттуда, не обращаясь к таблице?
-- Создание таблицы и построение функционального индекса create table del_nvl_ind as select id, case when val < 1 then null else round(val)*12 end val from ( select level id, level * dbms_random.value val from dual connect by level < 1000000 ); create index del_nvl_idx_nvl on del_nvl_ind (nvl(val,0)); -- Получение плана запроса explain plan for select val from del_nvl_ind where nvl(val,0) = 100; select * from table(dbms_xplan.display); | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 10000 | 107K| 600 (1)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| DEL_NVL_IND | 10000 | 107K| 600 (1)| 00:00:01 | |* 2 | INDEX RANGE SCAN | DEL_NVL_IDX_NVL | 4000 | | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access(NVL("VAL",0)=100) И еще вопрос - как можно изменить запрос, чтобы в плане появился INDEX FAST FULL SCAN?
Отслеживать
51.6k 200 200 золотых знаков 61 61 серебряный знак 243 243 бронзовых знака
задан 22 мар 2019 в 8:40
Анатолий Эрнст Анатолий Эрнст
927 1 1 золотой знак 8 8 серебряных знаков 27 27 бронзовых знаков
ведь все значения есть в самом к индексе Нет. Значение val в индексе отсутствует. Вот было бы select nvl(val,0) from del_nvl_ind where nvl(val,0) = 100; - тогда индекс и правда был бы покрывающий.
22 мар 2019 в 8:43
И index_ffs вы вряд ли получите на таком запросе. Потому что не даром там слово FULL - это полное сканирование индекса, которое медленнее RANGE SCAN. Этот метод применяется только когда искать по самому индексу не представляется возможным (колонки например не в том порядке, который можно использовать или по другим причинам требуется множественная выборка из разных регионов), но данных в индексе достаточно, что бы не обращаться к таблице, размер которой больше индекса (в ней больше разных колонок)
22 мар 2019 в 8:56
INDEX FAST FULL SCAN прочитает вам весь индекс. Но зачем вам это. У вас 1 000 000 , а под условия индекса попадет допустим 100. Прочитать только нужные блоки в индексе будет быстрее
22 мар 2019 в 8:56
Зачем сканировать весь индекс, когда разумнее искать значения от 100 до 100. Т.е. искать верхнюю и нижнюю границы записей с указанным значением.
22 мар 2019 в 8:57
Ааа, тогда понятно. Для индексации null надо просто константу вставить - create index del_nvl_idx_nvl on del_nvl_ind (val, 1) , тогда нет нужды nvl() в листе запрооса.
(Решено) Какого метода доступа не существует?sequential scanindex scanbitmap scansequential index scanindex only scan…
Внимание! Ответы искусственного интеллекта могут быть неточными. Не полагайтесь на них в медицине, юриспруденции, финансах и вопросах безопасности. При принятии важных решений всегда консультируйтесь с профильными специалистами.
Администрация сайта не несет ответственности за любой автоматически созданный контент. Если вы обнаружили ошибки, пожалуйста, сообщите об этом через кнопку "репорт" внизу ответа и мы примем соответствующие меры. Спасибо за вашу помощь в улучшении качества нашего сервиса.
Ответ нейросети:
Существует пять основных методов доступа к данным в базах данных: sequential scan, index scan, bitmap scan, sequential index scan и index only scan. Каждый из них имеет свои сильные и слабые стороны, и используется в зависимости от типа запроса и структуры данных.
Sequential scan (последовательный проход) - это метод доступа, который просто читает строки таблицы по порядку, начиная с первой и заканчивая последней. Этот метод доступа подходит для выборки всех строк из таблицы, так как в этом случае нет необходимости проводить анализ индексов.
Index scan (сканирование индекса) - это метод доступа, который используется для выборки строк из таблицы по заданному условию, используя индекс. Этот метод является одним из самых быстрых, так как он позволяет пропустить строки, которые не соответствуют условию, но требуется время на построение и анализ индексов.
Bitmap scan (сканирование битовой карты) - это метод доступа, который используется для запросов, состоящих из нескольких условий, каждое из которых использует отдельный индекс. Каждый индекс создает битовую карту, которая затем объединяется для получения окончательного результата. Этот метод также требует времени на построение и анализ индексов.
Sequential index scan (последовательное сканирование индекса) - это метод доступа, который используется для запросов, которые требуют чтения значений столбца из таблицы, используя индекс, но без выборки строк. Этот метод часто применяется при выборке большого числа строк или при наличии больших значений в столбце.
Index only scan (сканирование только индекса) - это метод доступа, который используется для запросов, которые могут быть выполнены полностью через индекс, без обращения к таблице. Этот метод обеспечивает высокую производительность для запросов, требующих анализа только некоторых отдельных столбцов.
Нет метода доступа, который не существует из перечисленных выше. Каждый метод доступа имеет свои особенности и применение в различных сценариях запросов к базам данных. Однако, существуют и другие методы доступа, которые могут использоваться в различных СУБД в зависимости от их архитектуры и особенностей. Например, в MongoDB существуют методы доступа, такие как aggregation pipeline и map-reduce, которые предназначены для обработки данных в распределенных системах.
Чтобы оставить комментарий, необходимо авторизоваться.
Задай любой вопрос нейросети!
она справится с любой поставленной задачей быстрее чем поиск в Яндекс.
Для того, чтобы задать вопрос нейросети, необходимо войти на сайт.
Последние вопросы
Последние вопросы:
(c) ChatGPT по русски 2023. Все права защищены. При обнаружении неправомерного контента пишите на [email protected]
Хотите задать любой вопрос нейросети?
Нажимая «Регистрация» или «Войти через Google», вы соглашаетесь с Публичной офертой, даете Согласие на обработку персональных данных, а также подтверждаете что вам есть 18 лет"
Форма репорта неправомерного контента.
Обратная связь с администрацией проекта
Уведомление об использовании cookie файлов
Наш сайт, как и большинство других, использует файлы cookie и другие похожие технологии (пиксельные тэги и т. п.), чтобы предоставлять услуги, наиболее отвечающие Вашим интересам и потребностям, а также собирать статистическую и маркетинговую информацию для анализа и совершенствования наших услуг и сайтов.
При использовании данного сайта, вы подтверждаете свое согласие на использование файлов cookie и других похожих технологий в соответствии с настоящим Уведомлением.
Если Вы не согласны, чтобы мы использовали данный тип файлов, Вы должны соответствующим образом установить настройки Вашего браузера или не использовать наш сайт.
Обращаем Ваше внимание на то, что при блокировании или удалении cookie файлов, мы не можем гарантировать корректную работу нашего сайта в Вашем браузере.
Cookie файлы, которые сохраняются через веб-сайт, не содержат сведений, на основании которых можно Вас идентифицировать.
Что такое файл cookie и другие похожие технологии
Файл cookie представляет собой небольшой текстовый файл, сохраняемый на вашем компьютере, смартфоне или другом устройстве, которое Вы используете для посещения интернет-сайтов.
Некоторые посещаемые Вами страницы могут также собирать информацию, используя пиксельные тэги и веб-маяки, представляющие собой электронные изображения, называемые одно-пиксельными (1×1) или пустыми GIF-изображениями.
Файлы cookie могут размещаться на вашем устройстве нами («собственные» файлы cookie) или другими операторами (файлы cookie «третьих лиц»).
Мы используем два вида файлов cookie на сайте: «cookie сессии» и «постоянные cookie». Cookie сессии — это временные файлы, которые остаются на устройстве пока вы не покинете сайт. Постоянные cookie остаются на устройстве в течение длительного времени или пока вы вручную не удалите их (как долго cookie останется на вашем устройстве будет зависеть от продолжительности или «времени жизни» конкретного файла и настройки вашего браузера).
Cookie файлы бывают различных типов:
Необходимые. Эти файлы нужны для обеспечения правильной работы сайта, использования его функций. Отключение использования таких файлов приведет к падению производительности сайта, невозможности использовать его компоненты и сервисы.
Файлы cookie, относящиеся к производительности, эффективности и аналитике. Данные файлы позволяют анализировать взаимодействие посетителей с сайтом, оптимизировать содержание сайта, измерять эффективность рекламных кампаний, предоставляя информацию о количестве посетителей сайта, времени его использования, возникающих ошибках.
Функциональные файлы cookie запоминают пользователей, которые уже заходили на наш сайт, их индивидуальные параметры (такие как язык и регион, например) и предпочтения, и помогают индивидуализировать содержание сайта.
Рекламные файлы cookie определяют, какие сайты Вы посещали и как часто, какие ссылки Вы выбирали, что позволяет показывать Вам рекламные объявления, которые заинтересуют именно Вас.
Электронная почта. Мы также можем использовать технологии, позволяющие отслеживать, открывали ли вы, прочитали или переадресовывали определенные сообщения, отправленные нами на вашу электронную почту. Это необходимо, чтобы сделать наши средства коммуникации более полезными для пользователя. Если вы не желаете, чтобы мы получали сведения об этом, вам нужно аннулировать подписку посредством ссылки «Отписаться» («Unsubscribe»), находящейся внизу соответствующей электронной рассылки.
Кнопки доступа к социальным сетям. Они используются для того, чтобы пользователи могли поделиться ссылкой на страницу в социальных сетях или сделать электронную закладку. Данные кнопки являются ссылками на веб-сайты социальных сетей, принадлежащих третьим лицам, которые, в свою, очередь могут фиксировать информацию о вашей активности в интернете, в том числе на нашем сайте. Пожалуйста, ознакомьтесь с соответствующими условиями использования и политикой конфиденциальности таких сайтов для понимания того, как они используют ваши данные, и того, как можно отказаться от использования ими ваших данных или удалить их.
Сторонние веб-сервисы. Иногда на данном сайте мы используем сторонние веб-сервисы. Например, для отображения тех или иных элементов (изображения, видео, презентации и т. п.), организации опросов и т. п. Как и в случае с кнопками доступа к социальным сетям, мы не можем препятствовать сбору этими сайтами или внешними доменами информации о том, как вы используете содержание сайта.
Как управлять файлами cookie?
Большинство интернет-браузеров изначально настроены на автоматический прием файлов cookie.
В любое время Вы можете изменить настройки вашего браузера таким образом, чтобы блокировать файлы cookie или предупреждать вас о том, когда они будут отправляться к вам на устройство (обратитесь к руководству использования конкретного браузера). Отключение файлов cookie может повлиять на Вашу работу в интернете.
Если вы используете несколько устройств и (или) браузеров для доступа в интернет, соответствующие настройки должны быть изменены в каждом из них.
Заключительные положения
По собственному усмотрению мы можем периодически изменять настоящее Уведомление.
По возникающим вопросам с нами можно связаться, используя контакты, размещенные на нашем сайте.
Запросы в PostgreSQL: 4. Индексное сканирование
Я уже рассказал об этапах выполнения запросов и о статистике и перешел к способам доступа к данным. В прошлый раз темой статьи было последовательное сканирование, а сегодня поговорим о сканировании индексном.
Прежде чем погружаться в детали индексного доступа, надо было бы рассказать про интерфейс индексных методов. Но я это уже делал в статье про индексы, и, хотя та серия несколько устарела, повторяться не буду. Если слова «класс операторов» и «свойства методов доступа» не находят отклика в душе, статью лучше перечитать.
Простое индексное сканирование
Существует два базовых варианта работы с идентификаторами версий строк, поставляемыми индексом. Первый из них — индексное сканирование. Большинство индексных методов (но не все) обладают свойством INDEX SCAN и поддерживают этот способ.
Операция представляется в плане запроса узлом Index Scan:
EXPLAIN SELECT * FROM bookings WHERE book_ref = '9AC0C6' AND total_amount = 48500.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Scan using bookings_pkey on bookings (cost=0.43..8.45 rows=1 width=21) Index Cond: (book_ref = '9AC0C6'::bpchar) Filter: (total_amount = 48500.00) (4 rows)
При индексном сканировании метод доступа возвращает идентификаторы версий строк по одному за раз. Механизм индексирования получает очередной идентификатор, обращается к табличной странице, на которую он указывает, получает версию строки и, если она удовлетворяет правилам видимости, возвращает необходимый набор полей. Процесс продолжается, пока у метода доступа не закончатся подходящие под условия запроса идентификаторы.
В строке Index Cond плана указываются только те условия, которые могут быть проверены с помощью индекса. Дополнительные условия, которые можно проверить только по таблице, отображаются в отдельной строке Filter.
Таким образом, обращения к индексу и к таблице не выделены в два отдельных узла плана, а выполняются в общем узле Index Scan. Хотя и существует специальный узел Tid Scan, читающий из таблицы версии строк по известным идентификаторам:
EXPLAIN SELECT * FROM bookings WHERE ctid = '(0,1)'::tid; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Tid Scan on bookings (cost=0.00..4.01 rows=1 width=21) TID Cond: (ctid = '(0,1)'::tid) (2 rows)
Оценка стоимости
Оценка индексного сканирования складывается из оценки доступа к индексу и оценки чтения табличных страниц.
Очевидно, что индексная часть оценки полностью зависит от конкретного метода доступа. В случае B-дерева основные расходы приходятся на чтение индексных страниц и обработку строк в этих страницах. Сколько именно страниц и строк будет прочитано, можно определить, зная общий объем данных и селективность условий. Доступ к индексной странице носит случайный характер (страницы, соседствующие друг с другом логически, физически как правило расположены непредсказуемым образом) и поэтому оценивается значением параметра random_page_cost. К оценкам также добавляются ресурсы процессора на спуск от корня до листовой страницы и на вычисление необходимых выражений.
Для табличной части стоимости оценка процессорного времени учитывает обработку каждой строки, которая оценивается значением параметра cpu_tuple_cost.
Табличная часть оценки ввода-вывода зависит не только от селективности индексного доступа, но и от корреляции физического расположения версий строк на диске с тем порядком, в котором метод доступа выдает идентификаторы версий строк.
Хороший случай — высокая корреляция
Если физический порядок версий строк на диске идеально коррелирует с логическим порядком идентификаторов в индексе, то, читая версии строк одну за другой, узел Index Scan будет последовательно переходить от страницы к странице, и обратится к каждой из них только один раз.

Информация о корреляции собирается как часть статистики:
SELECT attname, correlation FROM pg_stats WHERE tablename = 'bookings' ORDER BY abs(correlation) DESC; attname | correlation −−−−−−−−−−−−−−+−−−−−−−−−−−−−− book_ref | 1 total_amount | 0.0026738467 book_date | 8.02188e−05 (3 rows)
Значения, близкие по модулю к единице, говорят о высокой упорядоченности (как для столбца book_ref ), а близкие к нулю — наоборот, о хаотичном распределении.
Вот пример индексного сканирования большого количества строк:
EXPLAIN SELECT * FROM bookings WHERE book_ref < '100000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Scan using bookings_pkey on bookings (cost=0.43..4638.91 rows=132999 width=21) Index Cond: (book_ref < '100000'::bpchar) (3 rows)
Оценка полной стоимости составляет примерно 4639.
Селективность условия по оценке планировщика составляет:
SELECT round(132999::numeric/reltuples::numeric, 4) FROM pg_class WHERE relname = 'bookings'; round −−−−−−−− 0.0630 (1 row)
Это близко к оценке 1/16, которую можно дать из общих соображений, зная диапазон значений book_ref от 000000 до FFFFFF.
Индексная часть оценки ввода-вывода для B-дерева складывается из стоимости чтения необходимого количества страниц. Индексные строки, соответствующие любому условию, которое поддерживается B-деревом, упорядочены и находятся в логически связанных листовых страницах, поэтому количество прочитанных индексных страниц оценивается произведением размера индекса на селективность. Но физически эти страницы не упорядочены, поэтому чтение носит случайный характер.
Оценка ресурсов процессора включает обработку каждой из прочитанных индексных строк (обработка одной строки оценивается значением параметра cpu_index_tuple_cost) и вычисление условия для каждой из этих строк (в данном случае условие содержит один оператор, что оценивается значением параметра cpu_operator_cost).
Табличная часть оценки ввода-вывода складывается из оценки последовательного чтения необходимого количества страниц. При идеальной корреляции табличные версии строк будут физически соседствовать друг с другом, поэтому количество страниц оценивается произведением размера таблицы на селективность.
К оценке ввода-вывода добавляется стоимость обработки каждой прочитанной версии табличных строк; обработка одной версии оценивается значением параметра cpu_tuple_cost.
WITH costs(idx_cost, tbl_cost) AS ( SELECT ( SELECT round( current_setting('random_page_cost')::real * pages + current_setting('cpu_index_tuple_cost')::real * tuples + current_setting('cpu_operator_cost')::real * tuples ) FROM ( SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples FROM pg_class WHERE relname = 'bookings_pkey' ) c ), ( SELECT round( current_setting('seq_page_cost')::real * pages + current_setting('cpu_tuple_cost')::real * tuples ) FROM ( SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples FROM pg_class WHERE relname = 'bookings' ) c ) ) SELECT idx_cost, tbl_cost, idx_cost + tbl_cost AS total FROM costs; idx_cost | tbl_cost | total −−−−−−−−−−+−−−−−−−−−−+−−−−−−− 2457 | 2177 | 4634 (1 row)
Формула показывает логику вычисления стоимости, и результат хорошо соответствует оценке планировщика, хотя и не является точным. Получение точного значения потребовало бы учета деталей, на которых я не буду останавливаться.
Плохой случай — низкая корреляция
Ситуация с доступом к таблице меняется, когда корреляция оказывается низкой. Создадим индекс по столбцу book_date , имеющему практически нулевую корреляцию с индексом, и посмотрим на запрос, выбирающий приблизительно ту же долю строк, что и в предыдущем примере. Индексный доступ оказывается настолько дорогим (56957 против 4639 в хорошем случае), что планировщик выбирает его, только если запретить ему все альтернативы:
CREATE INDEX ON bookings(book_date); SET enable_seqscan = off; SET enable_bitmapscan = off; EXPLAIN SELECT * FROM bookings WHERE book_date < '2016-08-23 12:00:00+03'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Scan using bookings_book_date_idx on bookings (cost=0.43..56957.48 rows=132403 width=21) Index Cond: (book_date < '2016−08−23 12:00:00+03'::timestamp w. (3 rows)
Дело в том, что чем ниже корреляция, тем выше вероятность того, что следующая версия табличной строки, идентификатор которой выдает метод доступа, окажется на другой странице. Поэтому вместо последовательного чтения узел Index Scan «скачет» со страницы на страницу, а количество обращений к страницам в предельном случае может достигать количества выбираемых версий строк.
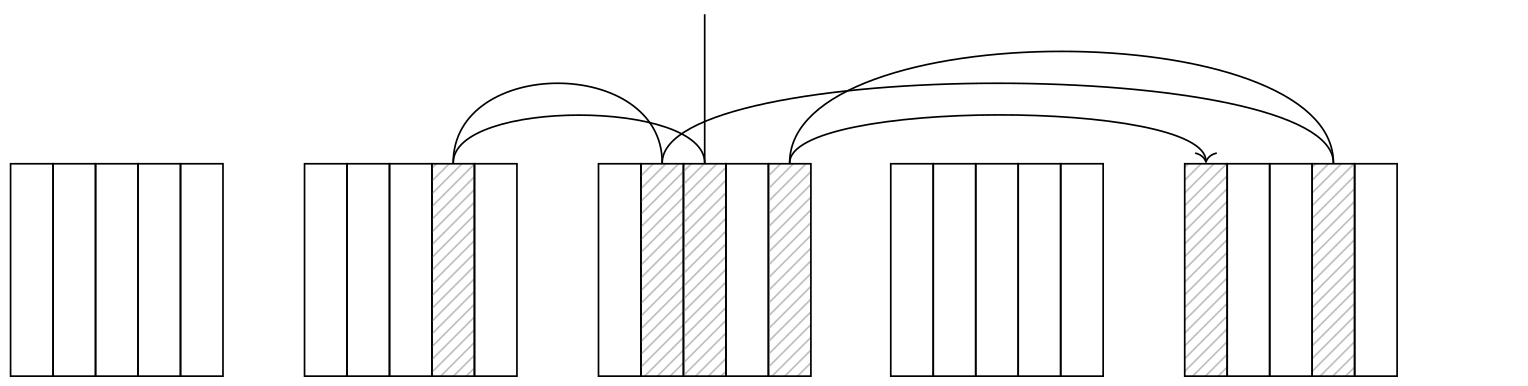
Однако было бы некорректным просто заменить в приведенной выше формуле seq_page_cost на random_page_cost и relpages на reltuples : мы получили бы оценку 535787, что на порядок превышает стоимость, которую мы видим в плане.
Дело в том, что модель дополнительно учитывает эффект кеширования. Поскольку часто используемые страницы остаются в буферном кеше (как и в кеше операционной системы), то чем больше кеш, тем больше вероятность найти нужную страницу в нем и избежать дисковой операции. Для целей планирования размер кеша определяется настройкой параметра effective_cache_size (значение по умолчанию — 4GB). Чем меньше это значение, тем выше оценка количества страниц, которые придется прочитать. Формулу я приводить не буду (ее можно найти в функции index_pages_fetched в backend/optimizer/path/costsize.c), но вот график, который показывает зависимость оценки количества прочитанных страниц от размера таблицы (для селективности 1/2 и случая, когда на странице помещается десять строк):
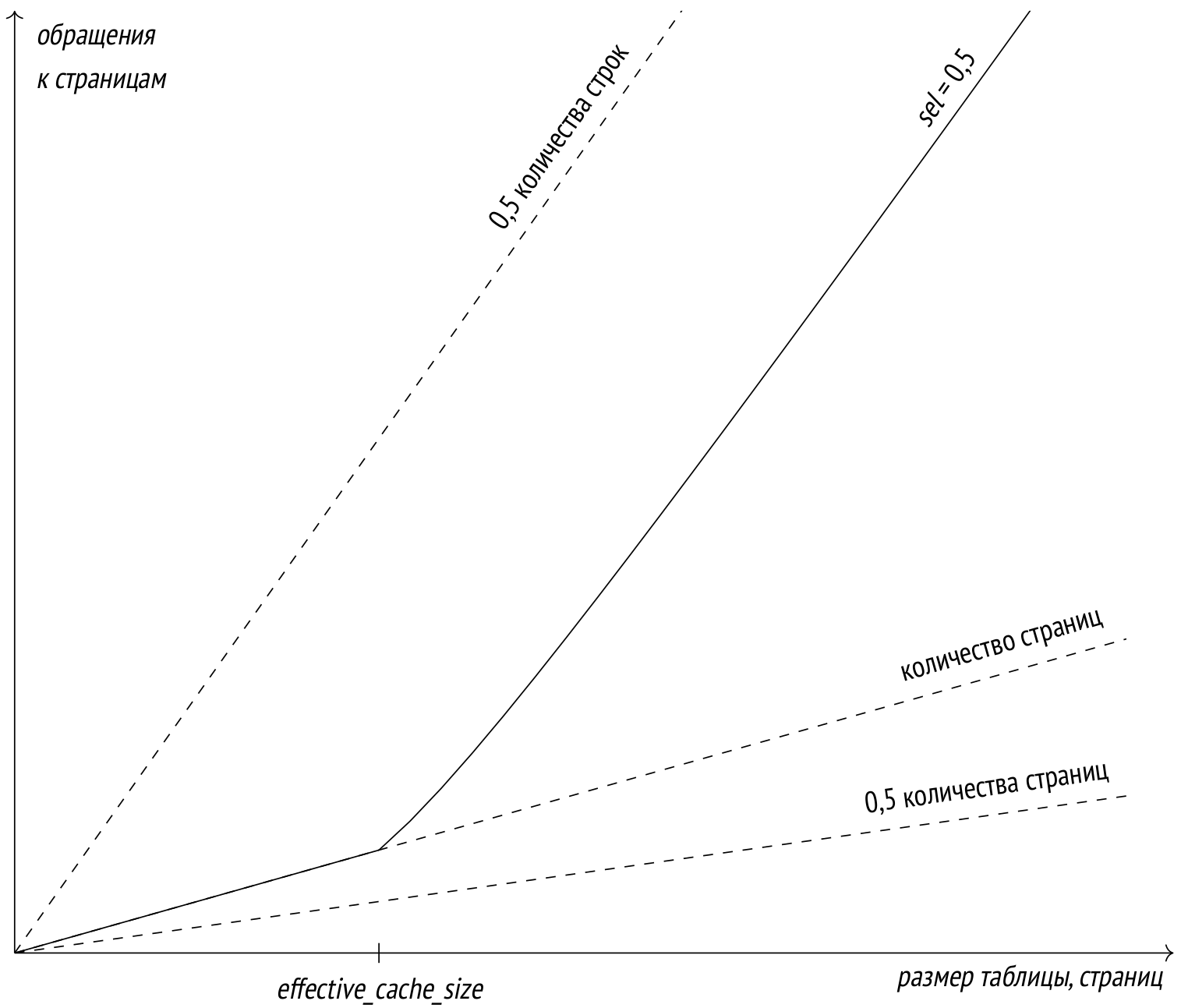
Пунктиром на графике показано количество обращений, равное половине количества страниц (лучший теоретически возможный случай при идеальной корреляции) и половине количества строк (худший случай при нулевой корреляции и отсутствии кеша).
Предполагается, что значение параметра effective_cache_size должно соответствовать общему объему памяти, доступному для кеширования (включая и буферный кеш PostgreSQL, и кеш ОС). Но, поскольку параметр служит только для оценки и не приводит к реальному выделению памяти, при необходимости его можно изменять и без оглядки на реальные цифры.
Установив минимальное значение параметра, получим оценку плана, близкую к наихудшему значению, вычисленному выше без учета эффекта кеширования:
SET effective_cache_size = '8kB'; EXPLAIN SELECT * FROM bookings WHERE book_date < '2016-08-23 12:00:00+03'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Scan using bookings_book_date_idx on bookings (cost=0.43..532745.48 rows=132403 width=21) Index Cond: (book_date < '2016−08−23 12:00:00+03'::timestamp w. (3 rows)
RESET effective_cache_size; RESET enable_seqscan; RESET enable_bitmapscan;Стоимость табличного ввода-вывода вычисляется для двух рассмотренных случаев — хорошего и плохого, — а затем берется промежуточное значение в зависимости от реальной корреляции.
Итак, индексное сканирование эффективно, когда требуется прочитать некоторую часть строк таблицы. Если версии строк в таблице коррелированы с порядком, в котором метод доступа выдает идентификаторы, то доля строк может быть весьма существенной. Если же корреляция слабая, то с уменьшением селективности индексный доступ очень быстро становится неэффективен.
Сканирование только индекса
Индекс, содержащий все данные из таблицы, необходимые для выполнения запроса, называется покрывающим (covering) для данного запроса. При наличии такого индекса можно избежать лишних обращений к таблице, получая от метода доступа не идентификаторы версий строк, а сами данные. Такая вариация индексного сканирования называется сканированием только индекса. Она доступна для методов доступа, которые поддерживают свойство RETURNABLE.
Операция представляется в плане запроса узлом Index Only Scan:
EXPLAIN SELECT book_ref FROM bookings WHERE book_ref < '100000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Only Scan using bookings_pkey on bookings (cost=0.43..3791.91 rows=132999 width=7) Index Cond: (book_ref < '100000'::bpchar) (3 rows)
Название может навести на мысль, что узел Index Only Scan никогда не обращается к таблице, но это не так. Индексы в PostgreSQL не содержат информации, позволяющей судить о видимости строк, поэтому метод доступа возвращает данные из всех версий строк, попадающих под условие поиска, независимо от того, видны они текущей транзакции или нет. Видимость затем проверяется механизмом индексирования.
Но если бы приходилось каждый раз заглядывать в таблицу для определения видимости, этот метод сканирования ничем не отличался бы от обычного индексного сканирования. Проблема решается тем, что PostgreSQL поддерживает для таблиц карту видимости, в которой процесс очистки отмечает страницы, содержащие только такие версии строк, которые видны всем транзакциям, независимо от их снимков. Если идентификатор версии строки, возвращенный индексным методом, относится к такой странице, то видимость версии можно не проверять.
На оценку сканирования только индекса влияет доля табличных страниц, отмеченных в карте видимости. Эта информация входит в собираемую статистику:
SELECT relpages, relallvisible FROM pg_class WHERE relname = 'bookings'; relpages | relallvisible −−−−−−−−−−+−−−−−−−−−−−−−−− 13447 | 13446 (1 row)
Оценка стоимости сканирования только индекса отличается от оценки обычного индексного сканирования тем, что стоимость ввода-вывода, связанная с доступом к таблице, берется пропорционально доле страниц, не включенных в карту видимости. (Стоимость обработки версий строк процессором остается без изменений.)
Поскольку в данном примере все версии строк на всех страницах видны всем транзакциям, фактически из оценки стоимости полностью исключается стоимость табличного ввода-вывода:
WITH costs(idx_cost, tbl_cost) AS ( SELECT ( SELECT round( current_setting('random_page_cost')::real * pages + current_setting('cpu_index_tuple_cost')::real * tuples + current_setting('cpu_operator_cost')::real * tuples ) FROM ( SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples FROM pg_class WHERE relname = 'bookings_pkey' ) c ) AS idx_cost, ( SELECT round( (1 - frac_visible) * -- доля страниц вне карты видимости current_setting('seq_page_cost')::real * pages + current_setting('cpu_tuple_cost')::real * tuples ) FROM ( SELECT relpages * 0.0630 AS pages, reltuples * 0.0630 AS tuples, relallvisible::real/relpages::real AS frac_visible FROM pg_class WHERE relname = 'bookings' ) c ) AS tbl_cost ) SELECT idx_cost, tbl_cost, idx_cost + tbl_cost AS total FROM costs; idx_cost | tbl_cost | total −−−−−−−−−−+−−−−−−−−−−+−−−−−−− 2457 | 1330 | 3787 (1 row)
Наличие изменений, еще не попавших за горизонт базы данных и не обработанных очисткой, увеличивает оценку стоимости плана (и, соответственно, уменьшает привлекательность плана для оптимизатора). Реальное количество вынужденных обращений к таблице можно узнать, используя команду EXPLAIN ANALYZE :
CREATE TEMP TABLE bookings_tmp WITH (autovacuum_enabled = off) AS SELECT * FROM bookings ORDER BY book_ref; ALTER TABLE bookings_tmp ADD PRIMARY KEY(book_ref); ANALYZE bookings_tmp; EXPLAIN (analyze, timing off, summary off) SELECT book_ref FROM bookings_tmp WHERE book_ref < '100000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Only Scan using bookings_tmp_pkey on bookings_tmp (cost=0.43..4712.86 rows=135110 width=7) (actual rows=132109 l. Index Cond: (book_ref < '100000'::bpchar) Heap Fetches: 132109 (4 rows)
Здесь, поскольку очистка не выполнялась, проверяется видимость всех строк (Heap Fetches). После очистки в проверке нет необходимости:
VACUUM bookings_tmp; EXPLAIN (analyze, timing off, summary off) SELECT book_ref FROM bookings_tmp WHERE book_ref < '100000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Only Scan using bookings_tmp_pkey on bookings_tmp (cost=0.43..3848.86 rows=135110 width=7) (actual rows=132109 l. Index Cond: (book_ref < '100000'::bpchar) Heap Fetches: 0 (4 rows)
Include-индексы
Может получиться так, что в индексе не хватает некоторых столбцов, необходимых для запроса, но расширить индекс невозможно:
- для уникального индекса добавление столбца не будет гарантировать уникальность исходных столбцов;
- тип данных дополнительного столбца может не иметь класса операторов для данного индексного метода доступа.
В этом случае начиная с версии PostgreSQL 11 можно добавить к индексу столбцы, не являющиеся частью индексного ключа. Поиск по дополнительным столбцам, конечно, будет невозможен, но индекс сможет работать как покрывающий для запросов, включающих эти столбцы.
Очень часто покрывающими называют именно такие include-индексы, но это неверно. Индекс является покрывающим, если его набор столбцов покрывает столбцы, необходимые для конкретного запроса. Используются ли при этом ключевые поля, или поля, добавленные с помощью предложения INCLUDE — не играет никакой роли. Более того, один и тот же индекс может быть покрывающим для одного запроса и не быть таковым для другого.
Пример показывает замену автоматически созданного для поддержки первичного ключа индекса на другой с дополнительным столбцом:
CREATE UNIQUE INDEX ON bookings(book_ref) INCLUDE (book_date); BEGIN; ALTER TABLE bookings DROP CONSTRAINT bookings_pkey CASCADE;NOTICE: drop cascades to constraint tickets_book_ref_fkey on table tickets ALTER TABLEALTER TABLE bookings ADD CONSTRAINT bookings_pkey PRIMARY KEY USING INDEX bookings_book_ref_book_date_idx; -- новый индексNOTICE: ALTER TABLE / ADD CONSTRAINT USING INDEX will rename index "bookings_book_ref_book_date_idx" to "bookings_pkey" ALTER TABLEALTER TABLE tickets ADD FOREIGN KEY (book_ref) REFERENCES bookings(book_ref); COMMIT; EXPLAIN SELECT book_ref, book_date FROM bookings WHERE book_ref < '100000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Index Only Scan using bookings_pkey on bookings (cost=0.43..437. Index Cond: (book_ref < '100000'::bpchar) (2 rows)
Сканирование по битовой карте
Ограничение индексного сканирования связано с увеличением количества обращений к страницам и изменением характера чтений с последовательного на случайное при уменьшении корреляции. Ограничение можно преодолеть, получив перед обращением к таблице все идентификаторы и расположив их в порядке возрастания номеров страниц. Именно так устроен второй базовый способ работы с идентификаторами — сканирование по битовой карте, — которым обладают методы доступа со свойством BITMAP SCAN.
Операция представляется в плане запроса двумя узлами:
CREATE INDEX ON bookings(total_amount); EXPLAIN SELECT * FROM bookings WHERE total_amount = 48500.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings (cost=54.63..7040.42 rows=2865 wid. Recheck Cond: (total_amount = 48500.00) −> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00..53.92 rows=2865 width=0) Index Cond: (total_amount = 48500.00) (5 rows)
В отличие от обычного индексного сканирования, план представлен двумя узлами. Узел Bitmap Index Scan обращается к методу доступа за битовой картой всех идентификаторов версий строк.
Битовая карта состоит из фрагментов, каждый из которых соответствует одной табличной странице. Количество версий строк в странице ограничено из-за достаточно крупного заголовка версии (не больше 256 версий для страницы стандартного размера); для каждого фрагмента хранится битовая карта одинакового размера, такого, чтобы гарантированно охватить все возможные версии (32 байта для стандартной страницы).
Узел Bitmap Heap Scan затем просматривает битовую карту фрагмент за фрагментом, читает соответствующую очередному фрагменту страницу и проверяет на этой странице все версии строк, отмеченные в битовой карте. Таким образом, страницы читаются в порядке возрастания номеров и каждая страница читается только один раз.
Но характер чтения отличается от последовательного, поскольку в большинстве случаев страницы не располагаются подряд друг за другом. Обычная предвыборка операционной системы в этом случае не помогает, и поэтому узел Bitmap Heap Scan — единственный из всех узлов — реализует собственную предвыборку, асинхронно читая effective_io_concurrency страниц. Работа этого механизма зависит от реализации операционной системой функции posix_fadvise ; если эта функция поддерживается, стоит настроить параметр в соответствии с возможностями аппаратуры на уровне табличных пространств.
Точность карты
Чем больше страниц охвачено версиями строк, соответствующих условию запроса, тем больше места занимает битовая карта. Она строится в локальной памяти обслуживающего процесса и ограничена размером, указанным в параметре work_mem. Если при построении карты размер достигает предельного значения, некоторые фрагменты карты «загрубляются» таким образом, чтобы каждый бит фрагмента соответствовал целой странице, а сам фрагмент охватывал не одну страницу, а диапазон. Это позволяет уменьшить размер битовой карты, пожертвовав при этом точностью. Команда EXPLAIN ANALYZE показывает точность построенной карты:
EXPLAIN (analyze, costs off, timing off) SELECT * FROM bookings WHERE total_amount > 150000.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings (actual rows=242691 loops=1) Recheck Cond: (total_amount > 150000.00) Heap Blocks: exact=13447 −> Bitmap Index Scan on bookings_total_amount_idx (actual rows. Index Cond: (total_amount > 150000.00) (5 rows)
В этом случае объема памяти хватило для точной (exact) битовой карты. Если уменьшить значение work_mem, часть фрагментов карты будет храниться с потерей точности (lossy):
SET work_mem = '512kB'; EXPLAIN (analyze, costs off, timing off) SELECT * FROM bookings WHERE total_amount > 150000.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings (actual rows=242691 loops=1) Recheck Cond: (total_amount > 150000.00) Rows Removed by Index Recheck: 1145721 Heap Blocks: exact=5178 lossy=8269 −> Bitmap Index Scan on bookings_total_amount_idx (actual rows. Index Cond: (total_amount > 150000.00) (6 rows)
При чтении табличной страницы, соответствующей грубому фрагменту битовой карты, необходимо перепроверять условия выборки для каждой версии строки на странице. Условие перепроверки всегда отображается в плане как Recheck Cond независимо от того, выполняется ли перепроверка на самом деле. А количество версий строк, отфильтрованных перепроверкой, показывается отдельно (Rows Removed by Index Recheck).
При очень большой выборке может получиться, что битовая карта, даже целиком состоящая из грубых фрагментов, все равно не помещается в память размером work_mem. В этом случае ограничение не соблюдается и карта занимает столько места, сколько необходимо. Никакого дополнительного уменьшения точности или сброса части фрагментов на диск не предусмотрено.
Действия с битовыми картами
Если в запросе условия наложены на несколько полей таблицы, и для этих полей созданы разные индексы, сканирование битовой карты позволяет использовать несколько индексов одновременно. Для каждого из индексов строятся битовые карты версий строк, которые затем побитово логически умножаются (если выражения соединены условием AND), либо логически складываются (если выражения соединены условием OR). Например:
EXPLAIN (costs off) SELECT * FROM bookings WHERE book_date < '2016-08-28' AND total_amount >250000; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings Recheck Cond: ((total_amount > '250000'::numeric) AND (book_da. −> BitmapAnd −> Bitmap Index Scan on bookings_total_amount_idx Index Cond: (total_amount > '250000'::numeric) −> Bitmap Index Scan on bookings_book_date_idx Index Cond: (book_date < '2016−08−28 00:00:00+03'::tim. (7 rows)
Здесь узел BitmapAnd объединяет две битовые карты с помощью битовой операции «и».
При объединении двух битовых карт в одну точные фрагменты остаются точными (если для новой карты хватает места work_mem в памяти), но если хотя бы один из фрагментов грубый, то и результирующий фрагмент тоже будет иметь низкую точность.
Оценка стоимости
Возьмем пример запроса со сканированием по битовой карте:
EXPLAIN SELECT * FROM bookings WHERE total_amount = 28000.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Bitmap Heap Scan on bookings (cost=599.48..14444.96 rows=31878 . Recheck Cond: (total_amount = 28000.00) −> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00..591.51 rows=31878 width=0) Index Cond: (total_amount = 28000.00) (5 rows)
Здесь селективность условия по оценке планировщика равна примерно:
SELECT round(31878::numeric/reltuples::numeric, 4) FROM pg_class WHERE relname = 'bookings'; round −−−−−−−− 0.0151 (1 row)
Оценка полной стоимости узла Bitmap Index Scan вычисляется так же, как стоимость обычного индексного доступа без учета обращений к таблице:
SELECT round( current_setting('random_page_cost')::real * pages + current_setting('cpu_index_tuple_cost')::real * tuples + current_setting('cpu_operator_cost')::real * tuples ) FROM ( SELECT relpages * 0.0151 AS pages, reltuples * 0.0151 AS tuples FROM pg_class WHERE relname = 'bookings_total_amount_idx' ) c; round −−−−−−− 589 (1 row)
В случае объединения нескольких битовых карт оценки доступа к отдельным индексам складываются и к ним добавляется (небольшая) стоимость объединения.
Для узла Bitmap Heap Scan оценка ввода-вывода отличается от аналогичной оценки в случае простого индексного сканирования при идеальной корреляции. Битовая карта позволяет читать табличные страницы в порядке возрастания номеров и без повторных обращений, но версии строк, соответствующие условию, больше не располагаются по соседству друг с другом. То есть вместо строго последовательного компактного диапазона скорее всего потребуется прочитать намного больше страниц.
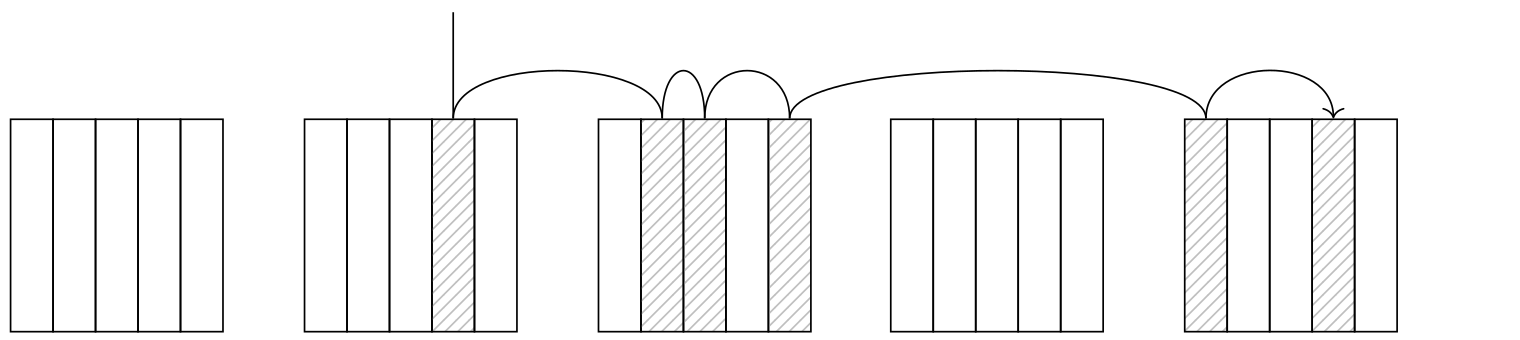
Количество прочитанных страниц оценивается формулой:
А оценка стоимости чтения одной страницы оценивается значением от seq_page_cost до random_page_cost в зависимости от доли прочитанных страниц по отношению к общему количеству страниц в таблице.
WITH t AS ( SELECT relpages, least( (2 * relpages * reltuples * 0.0151) / (2 * relpages + reltuples * 0.0151), relpages ) AS pages_fetched, round(reltuples * 0.0151) AS tuples_fetched, current_setting('random_page_cost')::real AS rnd_cost, current_setting('seq_page_cost')::real AS seq_cost FROM pg_class WHERE relname = 'bookings' ) SELECT pages_fetched, rnd_cost - (rnd_cost - seq_cost) * sqrt(pages_fetched / relpages) AS cost_per_page, tuples_fetched FROM t; pages_fetched | cost_per_page | tuples_fetched −−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−+−−−−−−−−−−−−−−−− 13447 | 1 | 31878 (1 row)
Как обычно, к оценке ввода-вывода добавляется оценка обработки каждой прочитанной версии строки. При точной битовой карте количество строк оценивается произведением общего количества строк в таблице на селективность условий. Но когда некоторые фрагменты битовой карты неточны, приходится проверять все версии строк на соответствующих страницах:
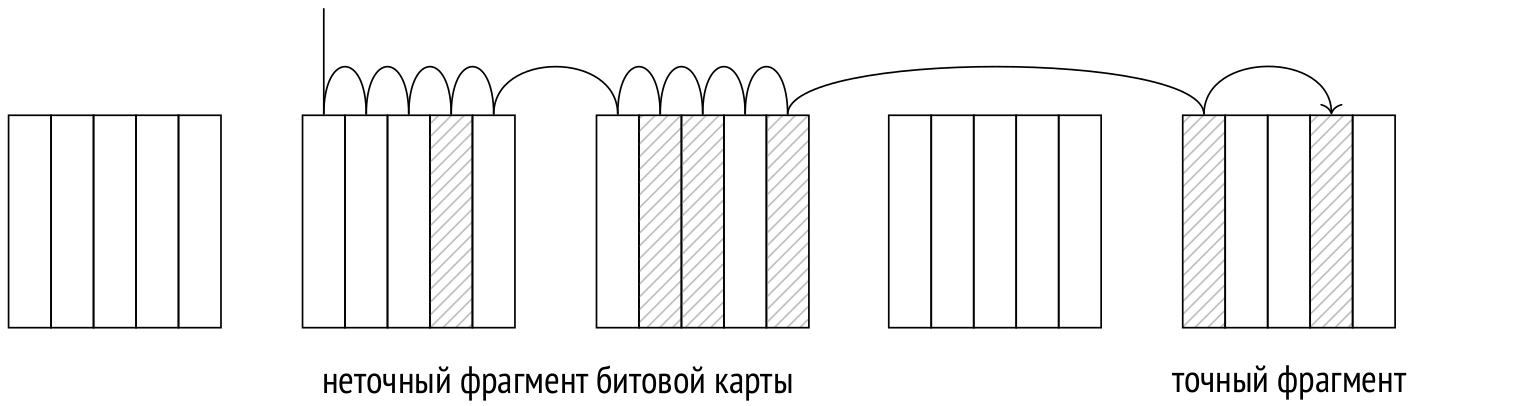
Поэтому (начиная с версии PostgreSQL 11) в оценке учитывается предполагаемая доля неточных фрагментов битовой карты (которую можно посчитать, зная общее количество строк в выборке и ограничение на размер битовой карты work_mem).
К оценке также добавляется полная стоимость перепроверки условий (независимо от точности битовой карты).
Оценка начальной стоимости узла Bitmap Heap Scan немного отличается от оценки полной стоимости узла Bitmap Index Scan: добавляется стоимость работы с битовыми картами.
В нашем примере битовая карта полностью точна и оценка вычисляется примерно следующим образом:
WITH t AS ( SELECT 1 AS cost_per_page, 13447 AS pages_fetched, 31878 AS tuples_fetched ), costs(startup_cost, run_cost) AS ( SELECT ( SELECT round( 589 /* оценка нижележащего узла */ + 0.1 * current_setting('cpu_operator_cost')::real * reltuples * 0.0151 ) FROM pg_class WHERE relname = 'bookings_total_amount_idx' ), ( SELECT round( cost_per_page * pages_fetched + current_setting('cpu_tuple_cost')::real * tuples_fetched + current_setting('cpu_operator_cost')::real * tuples_fetched ) FROM t ) ) SELECT startup_cost, run_cost, startup_cost + run_cost AS total_cost FROM costs; startup_cost | run_cost | total_cost −−−−−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−− 597 | 13845 | 14442 (1 row)
Параллельные версии индексного сканирования
Все способы индексного сканирования — обычное, сканирование только индекса, сканирование по битовой карте — имеют версии для параллельных планов.
Стоимость параллельного выполнения оценивается аналогично последовательному, но (как и в случае параллельного последовательного сканирования) ресурсы процессора распределяются между всеми параллельными процессами, уменьшая итоговую стоимость. Составляющая ввода-вывода не распределяется, поскольку чтение страниц синхронизируется между процессами и происходит последовательно. Поэтому я просто покажу примеры параллельных планов без разбора оценок стоимости.
Параллельное индексное сканирование Parallel Index Scan:
EXPLAIN SELECT sum(total_amount) FROM bookings WHERE book_ref < '400000'; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (cost=19192.81..19192.82 rows=1 width=32) −> Gather (cost=19192.59..19192.80 rows=2 width=32) Workers Planned: 2 −> Partial Aggregate (cost=18192.59..18192.60 rows=1 widt. −> Parallel Index Scan using bookings_pkey on bookings (cost=0.43..17642.82 rows=219907 width=6) Index Cond: (book_ref < '400000'::bpchar) (7 rows)
Параллельное сканирование только индекса Parallel Index Only Scan:
EXPLAIN SELECT sum(total_amount) FROM bookings WHERE total_amount < 50000.00; QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (cost=23370.60..23370.61 rows=1 width=32) −> Gather (cost=23370.38..23370.59 rows=2 width=32) Workers Planned: 2 −> Partial Aggregate (cost=22370.38..22370.39 rows=1 widt. −> Parallel Index Only Scan using bookings_total_amoun. (cost=0.43..21387.27 rows=393244 width=6) Index Cond: (total_amount < 50000.00) (7 rows)
При сканировании по битовой карте построение карты в узле Bitmap Index Scan всегда выполняется одним процессом. Когда битовая карта готова, сканирование таблицы выполняется параллельно в узле Parallel Bitmap Heap Scan:
EXPLAIN SELECT sum(total_amount) FROM bookings WHERE book_date < '2016-10-01';QUERY PLAN −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− Finalize Aggregate (cost=21492.21..21492.22 rows=1 width=32) −> Gather (cost=21491.99..21492.20 rows=2 width=32) Workers Planned: 2 −> Partial Aggregate (cost=20491.99..20492.00 rows=1 widt. −> Parallel Bitmap Heap Scan on bookings (cost=4891.17..20133.01 rows=143588 width=6) Recheck Cond: (book_date < '2016−10−01 00:00:00+03. −>Bitmap Index Scan on bookings_book_date_idx (cost=0.00..4805.01 rows=344611 width=0) Index Cond: (book_date < '2016−10−01 00:00:00+. (10 rows)Сравнение методов доступа
Зависимость стоимости различных методов доступа от селективности условий можно представить следующим образом:
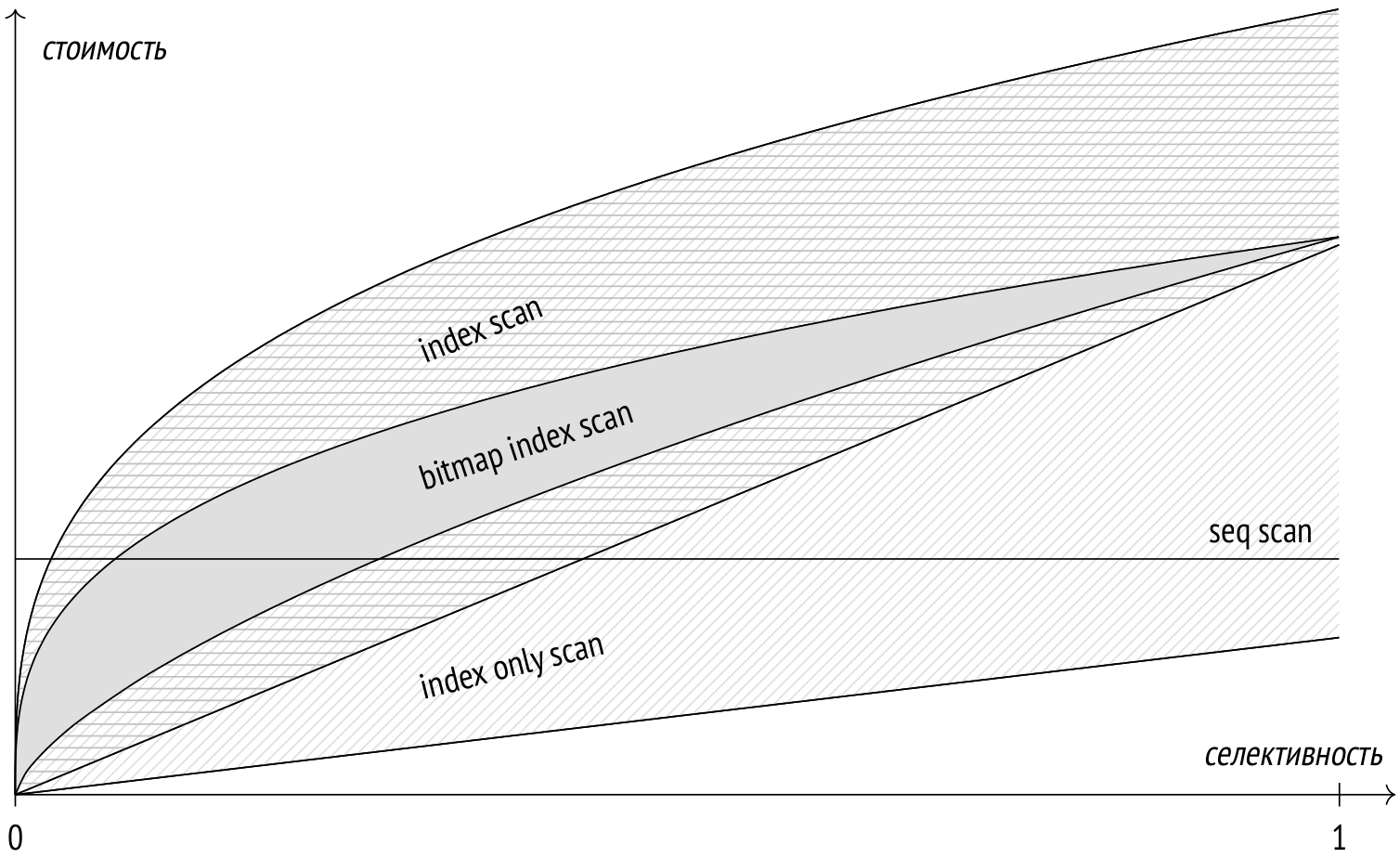
Этот график имеет качественный характер; конкретные числа, разумеется, будут зависеть от таблицы и от параметров сервера.
Последовательное сканирование не зависит от селективности и, начиная с некоторой доли выбираемых строк, обычно работает лучше остальных методов.
Стоимость индексного сканирования сильно зависит от корреляции между физическим расположением версий строк и порядком, в котором индексный метод доступа выдает идентификаторы. При идеальной корреляции индексное сканирование эффективно даже при довольной большой доле выбираемых строк. Но при слабой корреляции (что чаще встречается в реальности) стоимость высока и очень быстро начинает превышать даже стоимость последовательного сканирования. При всем этом индексное сканирование — безусловный лидер в очень важном случае, когда индекс (часто уникальный) используется для выборки единственной строки.
Сканирование только индекса (если оно применимо) может давать прекрасные результаты и выигрывать у последовательного сканирования даже при выборке всех строк. Его производительность, однако, очень сильно зависит от карты видимости, и в худшем случае сканирование только индекса деградирует до обычного индексного сканирования.
Стоимость сканирования по битовой карте хоть и зависит от объема памяти для построения карты, но в целом гораздо более стабильна, чем стоимость индексного сканирования. Этот метод хоть и уступает индексному сканированию в условиях идеальной корреляции, но при слабой корреляции существенно превосходит его.
Каждый из методов доступа превосходит остальные в определенных ситуациях; нет такого метода, который всегда уступал бы другим. Планировщик выполняет серьезную работу по оценке эффективности каждого из методов в каждом конкретном случае. Чтобы эти оценки были близки к реальности, очень важна актуальная статистика.
- оптимизация
- планирование
- индексный доступ
- доступ к данным
- индексы
- новый редактор никуда не годится