1) Один символ текста занимает объём 2 байта. На диске выделено 1024 бит.
Сколько символов можно записать на диск?
Ответ:

Можете сделать пожалуйста, в вордовском файле, буду благодарен. ПРАКТИЧЕСКАЯ РАБОТА Nº1 Создание, общее форматирование, сохранение документа MS Wor … d Цель работы — изучение функциональных возможностей текстового процессора Word 2007 и приобретение навыков практической работы по созданию и редактированию тек- стовых документов. Задание Nº 1 Для вновь созданного документа, используя вкладку Разметка страницы, установи- те следующие параметры: 1. Поля — Настраиваемые поля — поле слева: 2,5 см, поле справа: 1,5 см, поле сверху: 1,5 см, поле снизу: 2 см, колонтитул сверху 1 см, колонтитул снизу: 1,2 см; Размер — размер бумаги: А4, 21 х 29,7 см; Ориентация — ориентация листа: книжная; 2. Расстановка переносов — установить автоматический перенос слов. Задание Nº 2 Наберите фрагмент текста Hososenexen docnamono Hasame e20 nevamame Ha krasuanype компьютера Вводимые символы появляются в том месте экрана, где находится курсор, который сдвигается вправо, оставляя за собой цепочку символов. При оостижени и правого поля страницы курсор автоматически перемещается в следующую строку: Этот процесс называется перетеканием текста, а нажатие на клавши Enter соз-оает новый абзац, а не новую строкі: Текст, который отображается в окне документа, хранится в оперативной памяти компьютера. Его можно отредактировать и напечатать, но при завершении работы с Hord он будет утерян. Поэтом: чтобы сохранить ввеоенный текст. нужно записать документ в файл на жесткий оиск колтьютера. Тогда его можно отдет открыть позже и продолжить работу: Hocoanoone socnorartmec xonaHoouf orpanume xhonku Ouc. При первом сохранении документа откроется оиалоговое окно Сохранение докт-мента, позволяющее казать имя файла и его положение (папку). Файлы, относящиеся к одному проекту или объединенные по каколу-либо иному принципу, реко-мендуется хранить в одной папке. Это позволяет упорядочить информацию и упростить по иск данных. Все последующие версии документа будут сохраняться в том же файле. причем новая версия документа замещает предыотирю. Ести требуется сохранить обе версии оохумента (стоонію и содержащую постеоние изменения,, воспользуйтесь команоой Сохранить, зказав иля и положение нового файла. Докрмент можно сохранить в той же папке, открыть оругую панку или создать новую. Задание Nº 3 Перед каждым абзацем набранного Вами текста вставьте разрывы (Вставка — Разрыв страницы), так, что бы каждый абзац начинался с новой страницы.
Червона куля має радіус r1, а жовта — r2. Роз- робіть програму з використанням принципу наслідування, за допомогою якої визначається різниця об’ємів м … іж червоною і жовтою кулею. З’ясуйте, які обласні центри України розташо- вані на широтах між 49° і 48°. Розробіть про- граму визначення різниці в широтах між ними і Києвом. Для обчислення й виведення різниці використайте суперклас, підклас і конструктор. Розробіть програму з суперкласом і підкласом. У суперкласі за допомогою одного методу об- числюється сума значень трьох параметрів методу, а за допомогою другого — їх добуток. У підкласі від суми значень перших двох пара- метрів віднімається значення третього. Звернення до всіх методів виконується з одного об’єкта з трьома аргументами. Розробіть програму без конструктора, у якій один клас наслідує атрибути іншого. У супер- класі два числа множаться, а в підкласі виво- диться результат множення. Обчисліть площі двох прямокутних трикутни- ків із відомими значеннями катетів із викори- станням суперкласу, підкласу та конструктора. У суперкласі обчислюються площі трикутників, а в підкласі — виведення значень обчислених їх площ.
Зачем нам нужно уметь моделировать интерьер жилого помещения и нежилого помещения?
Накреслити блок-схему алгоритму рішення завдання:Знайти суму елементів одновимірного масиву A розміром N. Поділити кожний елемент вихідного масиву на … отримане значення. Результат отримати в тому самому масиві.
Сколько символов в одном байте?
В одном байте восемь битов.
В ряде систем кодирования используется представление один символ — один байт. В системе кодирования Unicod символ — два байта.
Есть семибитные системы кодирования, пятибитные, с переменным размером кода — азбука Морзе, например, и т. д.
Есть наборы символов (японские или китайские иероглифы, к примеру) , для кодирования которых одним байтом не обойтись.
Корректнее спросить, сколько байтов потребуется для кодирования символов из какого-то набора.
Остальные ответы
255 и один ноль
или в чём вопрос?
Сколько знаков?
1 символ = 8 бит, 1 байт.
Значит, один
В зависимости от кодировки =)
в одном байте 8 бит.
если символ однобайтовый, то один.
если двухбайтовый (Юникод, например) , то половина (точнее нет символа в одном байте).
1 байт = 8 бит.
бит может принимать значение 0 или 1.
Таким образом 1 байт может принимать 256 (2 в степени 8) значений.
Не совсем понятно, про какие символы ты говоришь, но обычно 1 символ занимает 1 байт.
Хотя в юникоде, например, 1 символ занимает 2 байта.
4.3. Кодирование символов. Байт.
На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N =2 7 =128 различных комбинаций из нулей и единиц, т.е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ски], по-русски произносится [а́ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы.
Биты, байты, кодировки
В числе прочих забавных случаев: для выбора десяти случайных чисел из бд, соискатели десять раз делают запрос; для открытия файла на чтение используют в PHP флаг ‘a+’; не умеют работать со строками, кодировками и указателями. Написать функцию, которая возвращает строку задом наперёд, не используя переменную-буфер — вообще непосильная задача.
В этой статье, я хочу коснуться проблемы заблуждений с битами и байтами, и написать свою методику обучения этим фундаментальным знаниям.
Итак… сперва я хочу написать определения из википедии методичек, которые являются догмой в умах профессоров из мин.образования.
- Бит — это двоичный логарифм вероятности равновероятных событий или сумма произведений вероятности на двоичный логарифм вероятности при равновероятных событиях; (или другими словами) бит — это единица информации, равная результату эксперимента, имеющему два исхода
- Бит — минимальная единица информации.
- Байт — минимальная адресуемая единица информации.
Из-за этих определений, в умах будущих программистов ЭВМ, больше каши, чем из-за каких-либо других определений! Они совершенно истинны, но совершенно бесполезны для обучения. Я превращаюсь в Халка, когда слышу их.
Про биты
Итак, дети, садитесь, урок первый, представьте себе выключатель. Нет, не двоичный логарифм вероятности… А обычный такой выключатель, тумблер, рычажок, что угодно, включающее например лампочку, когда находится в одном положении и выключающее в другом. На некоторых рычажках даже подписывают буковки I/O, как указатели положений ручки. Нет, выключатель не несёт в себе информацию. Он выключает свет.
У выключателя есть два положения — вкл/выкл. Если мы поставим рядом два выключателя, то количество комбинаций позиций, которое могут занимать их ручки — четыре. (Когда оба выключены, когда оба включены, и две комбинации когда включен только один из них). Если мы возьмём систему из трёх выключателей — они смогут занимать восемь комбинаций. И так далее, N выключателей имеют 2^N комбинаций. Выключатель который имеет только два положения (вкл/выкл) мы можем назвать битом. Если мы представим, что положениям вкл/выкл соответствуют числа 1 и 0, то можно легко записать какое-нибудь целое число в двоичной системе счисления, используя только последовательный набор выключателей, так чтобы каждый выключатель отвечал за свой двоичный разряд.
Безусловно выключатели мы можем применить к магнитной дорожке, или оптическому диску, так, чтобы при помощи специального устройства можно было «включать» или «выключать» их маленькие участки. Теперь мы наконец подошли к тому, что все компьютерные запоминающие устройства состоят из «ноликов и единичек».
Однако, в этих ноликах и единичках нам надо хранить информацию. Какую же информацию нам можно хранить? Давайте рассмотрим один бит. Мы можем условно договориться, что он может хранить информацию, и два его состояния вкл/выкл содержат значения «баклажан» и «не баклажан» соответственно. Это отлично подходит, когда нам надо произвести учёт баклажанов! Однако в реальном мире компьютеры, которые умеют только считать баклажаны — не пользуются спросом. Выходит выключатель (бит) не может нести в себе информацию. Чтобы записывать ноликами и единичками какую-то информацию, было решено группировать их по несколько штук, и такую группу называть байтом.
Байт
На заре компьютеров байты составляли 4, потом 5, потом 6 бит… Группа из 6 бит может принимать целых 64 значений. Вполне неплохо, так как можно создать некую таблицу соответствий этих значений определённым символам — кодировку. Такая кодировка уже может содержать цифры и заглавные буквы латинского алфавита, а также некоторые арифметические знаки. «Шестибитные-кодировки» — применялись на компьютерах в 1950-х — 1960-х годах.
Для человека который только начинает изучать информатику, будет понятно и легко запомнить что байт — является минимальной единицей информации. В байт можно записать какое-нибудь число, либо например какой-нибудь символ из таблицы символов (англ. charset, буквально «набор символов») — кодировки (codepage, encoding).
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.
Кодировки
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.

Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
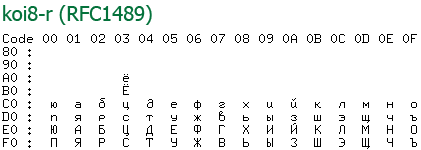
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.

Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.

Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.
Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 2 16 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Символы с кодами 0×0000.0xD7FF и 0xE000.0xFFFF представляются одним 16-битным словом, а символы с кодами 0×10000–0×10FFFF — в виде последовательности двух 16-битных слов. Количество символов, представляемых двумя 16-битными словами равно (2 20 ). Для представления символов с кодами 0×10000–0×10FFFF используется матрица перекодировки. Первое слово из двух переданных лежит в диапазоне 0xD800-0xDBFF, а второе — 0xDC00-0xDFFF. Именно этот диапазон значений не может встречаться среди символов, передаваемых с помощью одного 16-битного слова, так что расшифровка кодировки всегда однозначна. Ясно, что имеется как раз 2 10 * 2 10 = 2 20 таких комбинаций.
Википедия — UTS-2
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| 0×00000000 — 0×0000007F | 0xxxxxxx | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
| 0×00000080 — 0×000007FF | 110xxxxx 10xxxxxx | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания |
| 0×00000800 — 0×0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
| 0×00010000 — 0×001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше 0×10ffff , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Заключение
Вот собственно и всё что я хотела рассказать. Я считаю что очень интересно разбираться в том как работает компьютер, знать как хранятся в нём символы которые я набираю на клавиатуре, представлять насколько однобайтная кодировка например win-1251 (или utf-32 с фикс. длиной) работает быстрее со строковыми функциями и почему и т. п. Надеюсь статья вам понравилась.
Большое спасибо Википедии за возможность скопировать цитаты и таблицы, а то бы писала статью ещё месяц.
Все кто хочет узнать больше, также могут почитать про то в каком порядке записываются байты в кодировках UTF-16 и UTF-32 — в википедии тут и тут. А также что такое порядок байтов тут: Порядок_байтов. Также интересна будет статья Юникод в операционных системах Microsoft.
Прокоментируй статью, хотя бы пару слов!
Комментарии:
#1 @ (Дмитрий Липин) 12.10.2011 17:46:55
Мм.
Я — Дмитрий Липин. Круто )
#2 Елена Лунная 13.10.2011 02:21:16
Рада что вам понравилось, Дмитрий. =)
#3 SelenIT 27.01.2012 04:48:19
И тут позволю себе немножко потроллить (конечно, не со злобой, а любя;):
я слышала такие забавные заблуждения, относительно фундаментальных основ, как:
.
в байте 8 бит потому что 8 — степень двойки
и чуть дальше
вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум
;)? А 32-битные процессоры/ОС точно ни при чем? 😉 И, на мой взгляд, небольшой, но всё же фактический ляпчик:
Вторая версия Юникода (UCS-2), стала называться UTF-16
Насколько я в курсе: во-первых, UTF-16 — это расширение бывшего UCS-2, той самой «первой двухбайтной кодовой таблицы на 65k символов», относившейся к Юникоду 1.1 и ниже — именно за счет добавления «суррогатных символов» и еще двух опциональных байт. А во-вторых, что UCS, что UTF («унив. набор символов» и «формат преобразования Юникода» соотв-но) — не сам Юникод, а лишь конкретные формы его представления. А вообще статья увлекательная, спасибо!
#4 Елена Лунная 27.01.2012 05:42:39
8=2^3 не очень поняла троллинг.
Разрядность процессора возможно влияет, но позвольте, а как быть с 16 битными процессорами или 64х битными? =) http://www.ixbt.com/cpu/cpu-bitness.shtml
Как туда запихнуть 32 битный символ? Будет ли влиять порядок байтов? Как это зависит от Ось или файловой системы? =) Я лично склоняюсь что 4 байта вместо трёх только из-за проблемм кратности (в секторах и т.п.).
Насчёт уникода даже не знаю что поправить, во многом руководствовалась английской википедией, где основная статья была UCS-2, а сейчас UTF-16, (так же стало и в русской). В русской вики сейчас указаны некоторые различия между ними. Крайне рекомендую всем кому интересно.
Рада что понравилось.
#5 SelenIT 27.01.2012 12:44:31
Троллинг был в «магических» свойствах двойки :). Насчет разрядности — отталкивался в основном от той же википедии (напр. здесь абзац про юникс-подобные системы). Да и просто, на мой взгляд, логично это. С 64-битными системами никаких проблем не вижу (работают же на таких процессорах 32-битные ОС и 80% нынешнего софта:), а 16-битным, боюсь, просто не дано (на то и есть другие представления, влезающие в меньшую разрядность). А переименование статей, как я понял, связано с тем, что термин UCS-2 признан устаревшим, сыгравшим свою роль в появлении UTF-16, но не больше того.
#6 Елена Лунная 27.01.2012 21:25:48
Ну как не дано-то 16-битным системам работать с 32 битными знаками? А если сделать кодировку 64 битную, с ней 32 битный процессор не справится? Пруф в студию, всем будет интересно =).
Вы утверждаете если бы кодировка была 24-битной она бы не работала на 32битном процессоре? В чём отличие от работы с 24 битным цветом? А с 48 восьми битным изображением как 32 битные процессоры работают?
В абзаце про unix-подобные системы написано только то, что utf8 в них популярней чем utf16 например. До какого-то момента на koi8 работали, и ничего.
Говоря о том что компьютеры работают быстрее с блоками памяти кратными двум я имела ввиду, что если в секторе N на диске (или в буфере памяти) вам надо прочитать Z-й символ, вам нужно умножать это количество на 3, а это работает в 2 раза медленнее чем умножение на 4 при должной оптимизации. Т.е. вместо 1 побитового сдвига у вас будет сдвиг + сложение.
Говоря о преимуществе того что в сектор диска попадает кратное количество символов — я имею ввиду то что для чтения одного символа гарантированно нужно прочитать один сектор диска (на 128 или 512 байт, это задаётся в фс), не больше. Нет ситуации когда символ лежит на стыке секторов, а при фрагментации в разных частях диска.
#7 SelenIT 27.01.2012 22:07:43
Согласен, про «невозможность» работы с 32-битными символами из-под меньшей разрядности я жестоко «прогнал» :). Но согласитесь, что возможность оперировать каждым символом как целым машинным словом (т.е., например, перекинуть его из одного регистра памяти в другой целиком за один такт процессора) намного удобнее, чем собирать его по частям в каком-то временном буфере, да еще постоянно перепроверяя, целый символ туда попал или только одна-две трети. Я имел в виду вот эту фразу из того абзаца:
Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Что же до удобств хранения/адресации в памяти, то, на мой взгляд, ваш же пример с 24-битным цветом этой версии слегка противоречит, ведь принципиальную разницу действительно сложно уловить. Так что, когда дорого место, можно, вроде, и дополнительную операцию себе позволить (правда, с цветом всё-таки есть нюанс — эти 24 бита на самом деле 3 однобайтных компонента, к которым часто приходится обращаться по отдельности). Так что при близком рассмотрении «магические свойства» у двойки в компьютерном мире всё-таки есть, и, возможно, 8-битные байты выжили в конкурентной борьбе с «менее круглыми» двоичными значениями не так уж случайно. кто знает? 😉
#8 Елена Лунная 27.01.2012 22:30:38
Подождите, вы меня уже путаете (равно как с вопросом о таблицах, на который я щас пытаюсь сделать testcase). Я в статье сказала — что для быстродействия многие текстовые редакторы оперируют с текстом в кодировке utf32 (ucs-4). Согласны?
wikipedia.org/wiki/Машинное_слово Размер машинного слова в AMD64 — 64 бита, согласны?
При показе символов на экран процессору вообще всё равно сколько в символе байт, так же как с цветом, согласны?
При операциях по конвертации из одной кодировки в другую процессор оперирует кусками по 8 бит, а не с 32битным числом, которое кстати зависит от порядка байтов (big-endian , little-endian), согласны?
В utf8 — трёхбайтные часто встречаются например для китайского алфавита, согласны?
Так при чём тут вообще регистры процессора и количество байт в символе utf?
#9 SelenIT 27.01.2012 22:49:00
Я имел в виду именно удобство внутреннего представления в программе: 1 такт — 1 маш. слово — 1. ну или 2 (в AMD64:) символа Юникода в UCS-4, и никаких хлопот с поиском границ между символами :). Насчет вывода на экран, обмена данными и вообще абсолютной нерелевантности процессора, кластеров на диске и прочих низкоуровневых тонкостей к количеству байт произвольного UTF (формата представления) — согласен полностью. Но изначально вопрос был про то, «откуда пошли именно 32 бита». И вот что пишет англ. википедия:
The original ISO 10646 standard defines a 31-bit encoding form called UCS-4, in which each encoded character in the Universal Character Set (UCS) is represented by a 32-bit friendly code value in the code space of integers between 0 and hexadecimal 7FFFFFFF. Because only 17 planes are actually in use, all current code points are between 0 and 0x10FFFF. UTF-32 is a subset of UCS-4 that uses only this range.
В общем, чем дальше — тем только запутаннее, страньше и чудесатее! Правда, всецело полагаться на википедию тоже нельзя — сам не так давно убирал из русской версии утверждение, что «в HTML теги могут частично перекрываться». )
#10 notisster 17.02.2012 16:29:21
задом намерёд
Исправьте пожалуйста.
#11 Елена Лунная 18.02.2012 01:53:37
#12 гость 19.05.2012 20:02:45
я ничего не понял =)
#13 26.02.2013 16:47:07
биты. байты. главное — хвост! (с)
#14 Юлия 23.05.2013 15:42:33
Гениально!
Спасибо Вам — за введение и лаконичный набор ссылок.
#15 Елена Лунная 23.05.2013 21:08:51
Рада что вам понравилось.
#16 10.06.2013 20:28:23
Извините но никак не могу понят почему только 8 бит в байте.
#17 Елена Лунная 11.06.2013 00:06:44
Ввиду обратной совместимости, в байте именно 8 бит. Ведь гораздо проще группировать байты, если хочется получить сущность большего порядка. чем делать байт размером в 9 бит допустим. Причём потребность в этих сущностях была уже давно, поэтому рассматривая многие языки программирования (хоть тот же паскаль или си) — можно заметить тип переменной равный двум байтам — «машинное слово» (word), или «двойное слово» — (double word, dword) равное 4-м байтам. Именно на алгоритмах группировки байт в сущность и работают т.н. «многобайтные кодировки», которые я рассмотрела в статье. (Ваш Кэп).
#18 аноним 23.08.2013 22:40:59
В байте 1024 бита. Дальше не читал. В большинстве вычислительных архитектур байт — это минимальный независимо адресуемый набор данных. В байтах может быть разное количество битов. В истории компьютерной техники существовали решения с иными размерами байта (например, 6, 32 или 36 битов). А вот в килобайте — 1024 байта. В мегабайте — 1024 килобайта. В гигабайте — 1024 мегабайта. В терабайте — 1024 гигабайта. И так далее.
#19 Елена Лунная 23.08.2013 22:50:26
to аноним:
Ахахаха. Я не читала весь ваш комментарий, но не согласна с ним! =)
Нет, серьёзно, это самый бесполезный комментарий этого блога.
#20 дизойнёр 17.01.2014 15:59:56
хотел написать мол это дико что у нас нынешнее образование наитупейшее, что это дико когда на отделениях информатики народу забивают голову литературой или историей или еще чем то не профильным, а на отделениях физики и математики людей пичкают биологией и угрожают непроставлением зачета если люди не сдадут бег,отжимания и волейбол на физкультуре. И я более чем уверен что это делается спецом и по сговору, что бы у нас в итоге было мало хорошо проф. образованных людей. По другому объяснение таких тупостей еще более несуразно и тупо выглядит чем сговор, потому что по другому это объясняется крайней идиотичностью и тупостью самих преподов и тех кто составлял такие требования, а думать что все эти люди идиоты это глупо. И тут прочитал камент 18 и ответ автора 19.
Вопрос к автору, мадама, у вас с головой все в порядке? Вы тут просвещаете людей по теме битов байтов и таблиц кодировок и тут же пишете что не согласны с элементарщиной типа что килобайт это 1024 байта и тп. Так же вы пишите На заре компьютеров байты составляли 4, потом 5, потом 6 бит… Группа из 6 бит может принимать целых 64 значений. Вполне неплохо Вы пишите так, как будто составные значения байта как будто бы типа путем прогресса и эволюции вырастали, сначала 4, потом 5, ЧТО В КОРНЕ НЕ ВЕРНО и может привести людей в заблуждение и навести их на такие мысли, что с таким раскладом значения байта могли бы расти до тех самых 1024 байтов в бите ( с чем вы вроде как не согласны , судя по описаниям наблюдаемых вами несуразностей ) и выше, 10001024 байтов в бите например.
В реальности , как и писали вам кстате в каменте 18, с которым вы почему то не согласны и более того считаете его безполезным, значения битов в байте были разными и задумывались, появлялись и проставлялись в соответствии с принятой кодировкой систем эвм. Про то, как байт дорос до восьми составных битов и что там мало » эволюционного роста с значениями » а лишь только поиск наиболее оптимального кодирования, есть несколько версий и про них вы можете почитать даже в википузии http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B9%D1%82 .
#21 Елена Лунная 17.01.2014 16:37:36
Уважаемый дизойнёр,
Разумеется я-то прочитала комментарий 18, и мой ответ как бы сарказмом пародирует его часть. Не думала что это нужно кому-то объяснять.
Цитирую начало статьи:
. я слышала такие забавные заблуждения, относительно фундаментальных основ, как:
в байте 1024 бита
Именно к этой фразе уважаемый аноним придрался, не прочитав дальше вообще статью, и начал меня же учить сколько бит в байте, сколько байт в килобайте и т.п. =) Т.е. его комментарий выглядит как «Статью не читал, но осуждаю». И я ещё раз могу повторить что это был самый бесполезный комментарий моего блога. И поэтому если человек не прочитал мою статью как я могу с ним разговаривать. Что касается значений байта, то они вырастали из 4,5,6 бит именно путём прогресса и эволюции в том числе для удовлетворения кодировок эвм, которые и являются одним из видов прогресса и эволюции =). Пожалуйста прочтите мои объяснения до конца прежде чем не согласиться.
Геном человека состоит из 23 пар хромосом, ввиду эволюции и прогресса, и система такова, что 24-я пара человеку не нужна. Аналогично с битами, Байт состоит из 8 бит — потому что сейчас для программистов это удобно, и 1024 бита в байте не нужно никому — это лишь в несколько раз уменьшит дисковое пространство и вычислительную мощность компьютеров (объяснить почему?). В случаях когда программисту необходимо оперировать группами бит большего размера, например для хранения RSA ключей — 1024,2048 или 4096 бит — программист просто оперирует последовательностью байт нужного размера. Именно поэтому во многих языках есть такие типы данных как Слово (word) или двойное слово (dword) , а такие типы как integer вообще не влезают в пределы одного байта. P.S. Ну, и возвращаясь к комментарию анонима, я специально ничего не писала про количество байт в килобайте, т.к. это не влияет на образование. Цель статьи — объяснить разницу между битом и байтом, а также рассказать почему это так на примере кодировок. Количество же байт в килобайте для меня например 1024, а для производителей дисков 1000. Вот Тёма писал в 84 параграфе ру.ководства. Современные SSD например вообще не умеют писать с точностью адресации в один байт — перезаписывают сразу блок.
P.P.S. Эволюция и прогресс вообще не однозначные понятия, в русском языке 33 буквы, а в китайском 414 слогов (а каждый слог ещё и несколькими иероглифами можно записать) такие дела =).
#22 да так заглянул 10.04.2014 21:13:39
молодца, мне понравилось)))
Чтобы оставить комментарий нужно войти или зарегистрироваться (Регистрируйтесь за 5 секунд, без подтверждения email и т.п.).
Либо волшебно используйте ваш логин в Google, Яндекс, рамблер или ЖЖ чтобы войти через Open_ID