OSD Timeout на мониторе — что это?

OSD Timeout на мониторе — настройка, которая определяет сколько меню монитора будет отображаться на экране после бездействия пользователя.
Скажите, бывало ли такое, что вам нужно отрегулировать яркость монитора.. контрастность его.. а еще монитор может быть со звуком, можно регулировать громкость. И вообще, почему бы монитор не настроить? Что мы делаем? Мы нажимаем примерно такие кнопки:

После на мониторе отображается меню, например такое:


Кстати здесь видим настройку OSD Timeout))) Но суть не в этом. Данное меню позволяет настроить монитор. Но если мы ничего в меню нажимать не будем — оно исчезнет. Но через сколько времени? Вот именно это всем и задается параметром OSD Timeout.
Например указали в OSD Timeout — 30 секунд. Это означает что открыли меню, и если ничего в течении 30 сек не делали — оно само закроется. Вот только кроме меню, эти 30 сек могут распространяться и на … индикатор громкости, яркости, контрастности, еще какие-то менюшки которые может показать монитор, все они тоже могут исчезать через 30 секунд.. вот например индикатор яркости, сделали ярче, больше ничего не делали. Тогда через 30 сек индикатор исчезнет. Но также не исключено что OSD Timeout влияет только на основное меню монитора, а на все остальные менюшки — может быть другая настройка.
Кстати такое меню содержат конечно и телевизоры, да и ноутбуки тоже.
Надеюсь данная информация оказалась полезной. Удачи и добра, до новых встреч друзья!
Osd timeout (время отображения экранного меню), Setting (настройка), Информация о продукте – Инструкция по эксплуатации Acer DW271HL

и нажмите кнопку Enter (Ввод) для
отображения меню основных настроек.
Для настройки параметра повторно
нажмите кнопку Enter (Ввод).
отрегулируйте время на шкале настройки.
Setting (Настройка)
и нажмите кнопку Enter (Ввод) для
отображения меню основных настроек.
Для настройки параметра повторно
нажмите кнопку Enter (Ввод).
параметр на шкале настройки.
Информация о продукте
для отображения информации о
продукте.
Возможно, Вы имели в виду „ old timeout “ ?
Sierra Leone Police in creating a modern and operationally independent police force that serves the people of Sierra Leone.
daccess-ods.un.org
Расширенный, хорошо вооруженный и, как
[. ] сообщается, этнически несбалансированный ООС может подорвать те [. ]
успехи, которые уже достигнуты
полицией Сьерра-Леоне в создании современных и независимых с оперативной точки зрения полицейских сил, служащих интересам народа Сьерра-Леоне.
daccess-ods.un.org
Clicking on the Clear button will empty the list in the main window; however, your current settings such as
starting and ending IP addresses, the number of
[. ] simultaneous connections and connection timeout settings will be preserved.
Для очистки списка в главном окне модуля нажмите Очистить; однако
ваши настройки, включая начальный и
[. ] конечный IP-адреса, количество одновременных подключений и таймаут будут [. ]
Therefor a timeout has to be defined by all participating carriers, after which the transmission should fail.
Следовательно, участвующим сторонам следует определить временной срок ожидания, по истечении которого передача ответственности считается не удавшейся.
Your web server can have other timeout configurations that may also [. ]
interrupt PHP execution.
php.mirror.range-id.it
Web-серверы
[. ] обычно имеют свои настройки таймаута, по истечении которого сами [. ]
завершают выполнение PHP скрипта.
php.mirror.range-id.it
In collaboration with the Legal office, OSD will organize video conferences with the concerned FAO Representatives to provide further guidance on how to undertake the negotiations with the host Government.
В сотрудничестве с Управлением по правовым вопросам Управление поддержки децентрализации организует видеоконференции с соответствующими представителями ФАО с тем, чтобы дать им дальнейшие рекомендации в отношении проведения переговоров с правительством страны пребывания.
Timeout active If the inverter is controlled via a communication interface (fieldbus, RS485 or SBus) and the power was switched off and back on again or a fault reset was performed, then the enable remains ineffective until the inverter once again receives valid data via the interface, which is monitored with a timeout.
download.sew-eurodrive.com
Если управление преобразователем производится через порт передачи данных (сетевая шина, RS 485 или SBus), и было выполнено выключение и повторное включение питания от электросети или сброс из-за ошибки, то функция разрешения не будет активной до тех пор, пока преобразователь не получит необходимые данные через порт, контролируемый с помощью тайм-аута.
download.sew-eurodrive.com
When you see three asterisks in a row, it usually means that the device that is being pinged on at hop has its firewall configured to
reject ICMP packets this will
[. ] cause each of the timers to timeout, and the final column will [. ]
simply display the words Request Timed Out.
redline-software.com
Когда вы видите три звездочки подряд, это обычно означает, что устройство, которое опрашивается во время прыжка, имеет
файервол, настроенный на блокирование
[. ] ICMP пакетов, что вызывает таймаут таймеров, а в последнем [. ]
столбце будет надпись «Превышен
интервал ожидания для запроса».
redline-software.com
Against that backdrop, reports that the Government imported assault weapons worth millions of dollars in January to
equip a recently enlarged paramilitary wing of its police, the Operational
[. ] Services Division (OSD), are of great concern.
daccess-ods.un.org
На этом фоне большую тревогу вызывают сообщения о том, что в январе правительство импортировало боевое оружие на
миллионы долларов для оснащения недавно расширенного военизированного крыла
[. ] своей полиции — отдела оперативной службы [. ]
daccess-ods.un.org
Once an OSD menu is active, return to the View Control [. ]
tab to move through the menu and to make selections.
resource.boschsecurity.com
Как только экранное меню станет активным, вернитесь на [. ]
вкладку Виз. контроль для перехода по меню и выбора.
resource.boschsecurity.com
With the transfer of responsibility for DO Network budgetary and staffing matters and management support to the Regional Offices completed, OSD will have about half the number of staff as the present OCD by the end of the biennium.
После завершения передачи сети ДО ответственности за бюджетные и кадровые вопросы, а также за оказание управленческой поддержки региональным отделениям, к концу упомянутого двухгодичного периода штатное расписание Управления сократится наполовину по сравнению с тем, которое существует в настоящее время.
Эксплуатация Ceph: флаги для управления естественными состояниями OSD
Этой статьёй мы начинаем серию материалов об эксплуатации Ceph и проблемах, которые могут возникать в процессе. Сегодня расскажем о флагах, с помощью которых можно контролировать состояние кластера: noup, nodown, noin, noout. Объясним, что такое «флаппинг OSD» и как его можно остановить.
Статья подготовлена на основе лекции Александра Руденко, ведущего инженера в группе разработки «Облака КРОК». Лекция доступна в рамках курса по Ceph в «Слёрме».
Естественные состояния OSD в Ceph
Для начала разберём, какие состояния OSD есть в Ceph.
Посмотрим на примере нашего стенда.

Глобальная строка состояния OSD разделена на две части. В первой части отражено состояние процессов OSD, во второй — состояние данных на OSD.
Процессы могут быть в состоянии up или down. Данные — в состоянии in или out.
up и down — это два базовых естественных состояния процессов OSD. OSD запускается и переходит в up, выключается — переходит в down.
in и out — это состояние данных на OSD, а точнее, отношение кластера или других участников кластера к данным на этой OSD. При включении OSD входит в состояние in, при выключении и долгом отсутствии — выходит в out.
Важно понять разницу между состояниями up/down и in/out.
Если OSD в состоянии up, это не означает, что кластер использует её данные. И наоборот, если OSD в состоянии down, кластер всё ещё может полагаться на эти данные.
Если OSD в состоянии in, это значит, что она «в обойме»: на неё реплицируются данные, для некоторых данных она является первичной OSD и т. д. То есть она включена в процесс обмена данными.
Если OSD в состоянии out — данные с неё выводятся.
Посмотрим на примере. В нашем кластере 9 OSD — все up, все in.
Останавливаем OSD 0.
systemctl stop ceph-osd@0
В состоянии up находится 8 OSD, но в состоянии in по-прежнему 9.
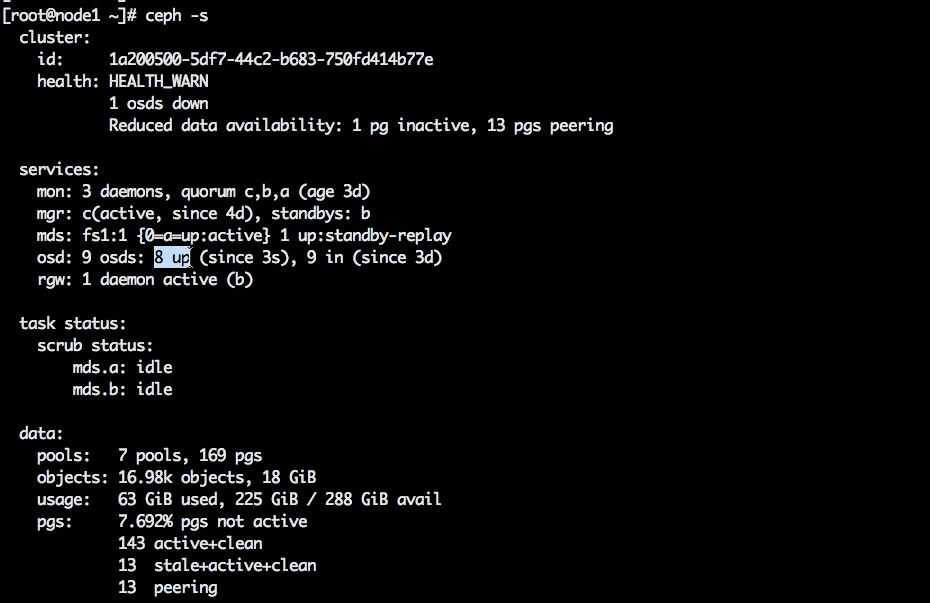
Посмотрим все OSD в состоянии down.
ceph osd tree down
В состоянии down находится одна OSD.

То есть состояние процесса перешло в down, но у кластера есть уверенность, что данные в ближайшее время подъедут, поэтому он оставляет OSD в статусе in.
Дефолтный таймаут — 20 минут. В течение этого времени placement groups с ушедшей в down OSD находятся в состоянии degraded, так как у них не хватает одной копии. Но пока кластер считает её in, он не начинает процесс восстановления. Через 20 минут кластер автоматически переведёт данные OSD в состояние out.
Надеемся, теперь разница между состояниями up/down и in/out понятна.
Флаги-блокаторы естественных состояний
up, down, in, out — это ручки, которые Ceph крутит сам. Но у администратора кластера есть возможность вклиниваться в процесс.
Если вы считаете, что нужно скорректировать естественное поведение кластера (например, заблокировать выключение OSD), то вы можете воспользоваться блокаторами естественных состояний.
Блокаторы естественных состояний OSD — это флаги noup/nodown и noin/noout.
Команда установки флага:
Команда снятия флага:
Теперь рассмотрим работу каждого флага на примере нашего стенда.
Флаг noup
Ранее мы перевели OSD в down.
Установим флаг noup — он не позволит OSD перейти в состояние up (будьте осторожны, применение флага вне эксперимента может быть опасным).
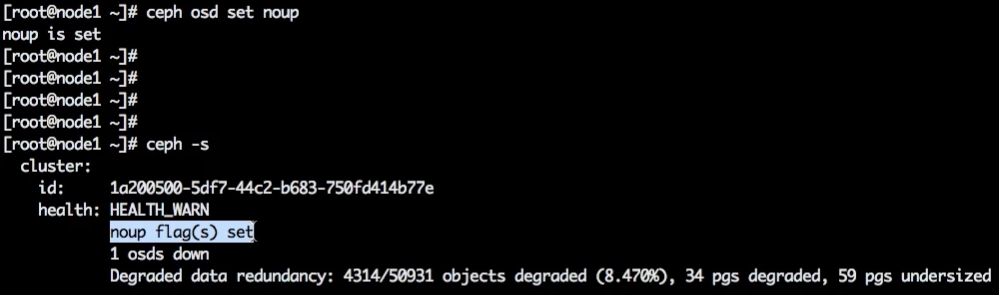
Пробуем запустить OSD.

Из-за установленного флага OSD не может перейти в состояние up. И это при том, что она запущена и работает.
Что происходит: когда OSD джойнится в кластер, она получает карту OSD, где видит, что ей сказали «noup». OSD запускается, но не может перейти в первое инфраструктурное состояние, в состояние up.
Флаг опасен, потому что если произойдёт сбой, при котором OSD кратковременно уйдут в down или кто-то рестартанёт OSD, то они не смогут подключиться и перейти в состояние up, а значит, не смогут в свои данные вернуть кластер.
На самом деле сложно представить, когда может понадобиться флаг noup. Ведь если вы не хотите, чтобы данные конкретных OSD включались в кластер, вы можете поставить noin (о нём ниже). Процессы OSD запустятся (они сами по себе безвредны), но данные с этих OSD использоваться не будут. Впрочем, во время обучения главное понять, как что работает, а кейсы, возможно, появятся.
Вернёмся к стенду.
Сейчас у нас есть OSD в состоянии down.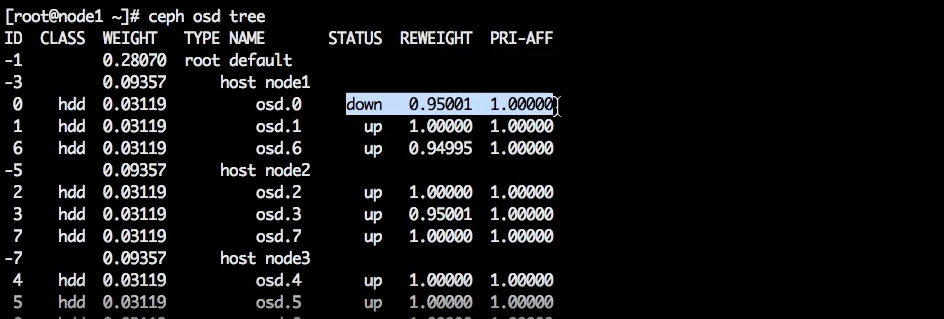
Но по-прежнему 9 OSD в состоянии in.
Приведём эту OSD в состояние out командой:

В результате на одну in стало меньше:
Это произошло бы автоматически, если бы Ceph выждал 20 минут.

Теперь Ceph относится к этим данным как к потерянным. Запустилось recovery io — placement groups восстанавливаются на других OSD.
Снимем флаг noup.
Все OSD в состоянии up.

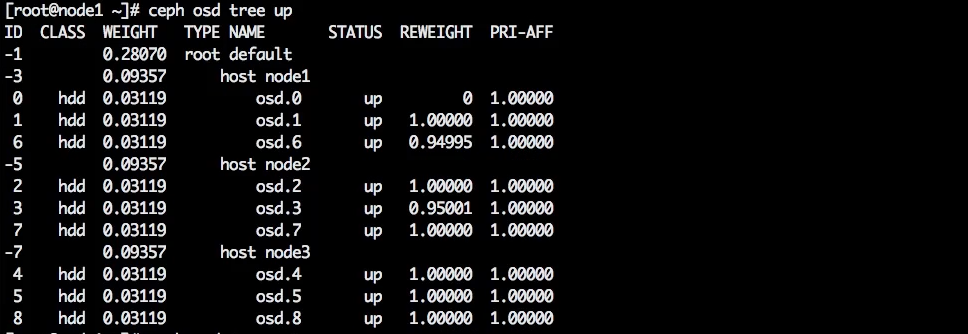
При этом одна OSD в состоянии out.

Мы поменяли ситуацию: все OSD находятся в состоянии up, но одна находится в состоянии out. То есть на её данные мы больше не полагаемся.
Остановим её ещё раз.

Теперь применим принудительное in, которое говорит кластеру: «Всё-таки считай, что эти данные доступны, что они скоро подъедут».
Мы смоделировали ситуацию, когда OSD выключилась (например, из-за проблем с питанием), но кластер всё ещё полагается на эти данные.

Перейдём к следующему флагу.
Флаг noin
Предположим, из-за каких-то проблем OSD перешла в down (для эксперимента мы остановим её принудительно).
Спустя время Ceph отправил её в out (опять же, мы сделаем это сами).
В результате получаем кластер, в котором 8 up, 8 in.

Данные, которые были на проблемных OSD, находятся в состоянии degraded, так как одна из их копий недоступна.
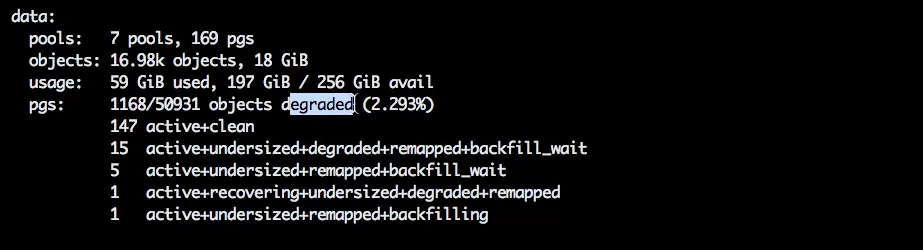
Мы предполагаем, что не будем использовать проблемные диски, но нам хотелось бы их поднять и применить для восстановления кластера.
Иными словами, нам нужно, чтобы проблемная OSD участвовала в процессе бакфиллинга (backfilling) и восстановления placement group.
В такой ситуации можно поставить флаг noin и после запустить OSD. Тем самым мы оставим OSD в out, то есть не будем доверять её данным, но при этом задействуем в процессе восстановления.
Ситуация радикально поменялась.
Напомним, пока OSD была выключена и пребывала в состоянии out, placement groups были в состоянии degraded. То есть количества копий одной placement group было недостаточно и новые placement groups создавались из оставшихся копий.
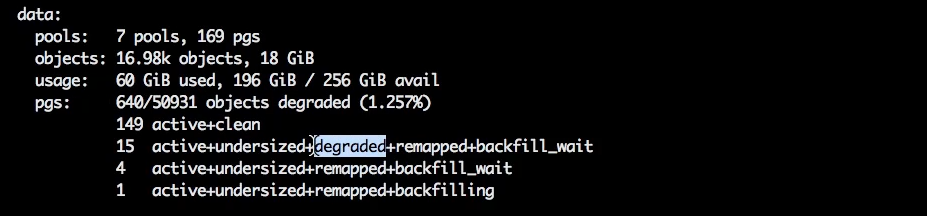
Как только мы её подняли, но при этом оставили в состоянии out, данные стали перемещаться — перешли в состояние misplaced.
Мы вернули количество копий, которые были в кластере изначально, поэтому теперь нет ни одной placement group в состоянии degraded.
Снимем флаг noin:
Важно!
После того, как мы вернули OSD, но оставили её в out, её можно вернуть в состояние in командой:
В отличие от состояния in, команды для принудительного возврата в состояние up нет.
Мы не можем заставить OSD перейти в up, потому что это состояние, в которое она переходит естественным образом при включении.
Флаг noout
С флагом noout всё проще.
Он нужен, когда вы на длительное время выключаете OSD и не хотите, чтобы Ceph отрешался от этих данных и запускал rebalancing, а хотите, чтобы он просто ждал, пока OSD вернутся. По сути это то же самое, что maintenance.
Ставится и снимается так же, как все другие флаги.
Флаг nodown и флаппинг OSD
Флаг nodown блокирует переход OSD в состояние down. Он принудительно держит OSD во всех картах в состоянии up, навязывая участникам кластера продолжать попытки с ней взаимодействовать: «да, OSD недоступна, но подождём».
Просто так делать nodown нет смысла. Если вы выключаете сервер на обслуживание, то правильно разрешать сервисам OSD переходить в down, потому что это их естественное состояние. Поэтому для обслуживания этот флаг практически не применим, хотя его нередко прописывают в регламентных операциях (обоснование для этого найти сложно).
Но есть одна ситуация, когда использование флага nodown оправдано. Она называется «флаппинг OSD» (flapping OSD’s).
Прежде чем перейти к описанию флаппинга, надо сказать, как OSD переходит в down. Есть два варианта: OSD сама сообщает о переходе в down или другие участники кластера говорят, что какая-то OSD долго не отвечает, а значит, перешла в down.
В первом случае при выключении OSD вы можете увидеть в логе монитора, как он пишет, что OSD сама себя пометила как down. Это нормальный процесс завершения, монитор помечает OSD как down и всем рассылает эту информацию с помощью апдейта карты OSD.
Во втором случае о недоступности процессов OSD сообщают другие OSD. Надо понимать, что все OSD мониторят друг друга. Каждая OSD условно пингует другую и тем самым мониторит её доступность. Когда монитор получает два репорта (или больше — параметр настраивается) о том, что некая OSD недоступна, он помечает её как down. После этого все участники сети считают, что OSD down, и кластер начинает перестраиваться.
Здесь и кроется проблема.
Из-за архитектурных особенностей Ceph одна OSD может получить большую нагрузку, чем соседняя. Поэтому возможны ситуации, когда одна или несколько OSD не успевают ответить тем OSD, которые её пингуют. Это может быть из-за высокой нагрузки, из-за того, что OSD ротирует свою RocksDB большого размера, из-за то, что прилетело много реквестов или на ответ банально не хватает CPU.
Монитор получает сообщения, что OSD недоступна, и помечает её как недоступную — можно сказать, помечает ложно, ведь по сути OSD работает. После этого кластер начинает перестраиваться, нагрузка перераспределяются на другие OSD, выбирается другая primary OSD.
На выбранной взамен ложно упавшей OSD начинается похожий процесс: она тоже не отвечает, тоже помечается как down — и так далее. В случае высокой нагрузки или больших проблем с железом всё может начать рушиться как карточный домик. Одна OSD перешла в фейковый down, вторая, третья… Первая ещё не успела восстановиться, а тут ещё парочка перешла.
Этот процесс в Ceph-комьюнити и называют «флаппинг». В результате флаппинга кластер может просто развалиться. Чтобы это предотвратить, можно воспользоваться флагом down.
После установки флага кластер не будет перестраиваться на каждый репорт от других OSD и по идее это должно сохранить его стабильность.
Конечно, производительность в таком кластере будет очень низкой, потому что если OSD «залипает» и не может ответить на heart beat, какая бы причина у неё не была, запросы пользователей будут страдать.
Запомните: nodown не поможет выровнять производительность кластера, не спасёт ситуацию и не сделает всех счастливыми, но по крайней мере кластер не будет закапывать сам себя.
В следующей статье поговорим о глобальных флагах для управления Ceph: nobackfill, norecover, norebalance и pause.