Объяснение P-значений и статистической значимости
В статистике p-значения обычно используются при проверке гипотез для t-тестов, тестов хи-квадрат, регрессионного анализа, дисперсионного анализа и множества других статистических методов.
Несмотря на то, что это так распространено, люди часто неправильно интерпретируют p-значения, что может привести к ошибкам при интерпретации результатов анализа или исследования.
В этом посте объясняется, как понять и интерпретировать p-значения понятным и практичным способом.
Проверка гипотезы
Чтобы понять p-значения, нам сначала нужно понять концепцию проверки гипотез .
Проверка гипотезы — это формальный статистический тест, который мы используем, чтобы отвергнуть или не отвергнуть какую-либо гипотезу. Например, мы можем предположить, что новое лекарство, метод или процедура дает некоторые преимущества по сравнению с текущим лекарством, методом или процедурой.
Чтобы проверить это, мы можем провести проверку гипотезы, в которой мы используем нулевую и альтернативную гипотезы:
Нулевая гипотеза.Между новым и старым методом нет никакого эффекта или разницы.
Альтернативная гипотеза.Между новым и старым методом существует некоторый эффект или разница.
Значение p показывает, насколько правдоподобна нулевая гипотеза с учетом данных выборки. В частности, если предположить, что нулевая гипотеза верна, p-значение говорит нам о вероятности получения эффекта, по крайней мере, такого же большого, как тот, который мы фактически наблюдали в выборке данных.
Если p-значение проверки гипотезы достаточно низкое, мы можем отклонить нулевую гипотезу. В частности, когда мы проводим проверку гипотезы, мы должны с самого начала выбрать уровень значимости. Обычный выбор уровней значимости: 0,01, 0,05 и 0,10.
Если p-значения меньше нашего уровня значимости, мы можем отклонить нулевую гипотезу.
В противном случае, если p-значение равно или превышает наш уровень значимости, мы не можем отвергнуть нулевую гипотезу.
Как интерпретировать P-значение
Определение p-значения в учебнике:
P-значение — это вероятность наблюдения выборочной статистики, которая по крайней мере столь же экстремальна, как и ваша выборочная статистика, при условии, что нулевая гипотеза верна.
Например, предположим, что завод заявляет, что производит шины, средний вес которых составляет 200 фунтов. Аудитор выдвигает гипотезу о том, что истинный средний вес шин, произведенных на этом заводе, отличается от 200 фунтов, поэтому он проводит проверку гипотезы и обнаруживает, что p-значение теста равно 0,04. Вот как интерпретировать это p-значение:
Если фабрика действительно производит шины со средним весом 200 фунтов, то 4% всех аудитов получат эффект, наблюдаемый в выборке, или больше из-за случайной ошибки выборки. Это говорит нам о том, что получение выборочных данных, которые сделал аудитор, было бы довольно редким, если бы завод действительно производил шины, средний вес которых составлял 200 фунтов.
В зависимости от уровня значимости, используемого в этой проверке гипотезы, аудитор, скорее всего, отклонит нулевую гипотезу о том, что истинный средний вес шин, произведенных на этом заводе, действительно составляет 200 фунтов. Выборочные данные, полученные им в ходе аудита, не очень согласуются с нулевой гипотезой.
Как не следует интерпретировать P-значение
Самое большое заблуждение относительно p-значений состоит в том, что они эквивалентны вероятности совершить ошибку, отклонив истинную нулевую гипотезу (известную как ошибка типа I).
Есть две основные причины, по которым p-значения не могут быть частотой ошибок:
1. P-значения рассчитываются на основе предположения, что нулевая гипотеза верна и что разница между данными выборки и нулевой гипотезой просто вызвана случайностью. Таким образом, p-значения не могут сказать вам вероятность того, что ноль является истинным или ложным, поскольку он на 100% верен, исходя из точки зрения вычислений.
2. Хотя низкое значение p указывает на то, что ваши выборочные данные маловероятны при условии, что нулевое значение истинно, значение p по-прежнему не может сказать вам, какой из следующих случаев более вероятен:
- Нуль является ложным
- Нуль верен, но вы получили нечетную выборку
Что касается предыдущего примера, вот правильный и неправильный способ интерпретации p-значения:
- Правильная интерпретация: если предположить, что завод производит шины со средним весом 200 фунтов, вы получите наблюдаемую разницу, которую вы получили в своей выборке, или более значительную разницу в 4% аудитов из-за ошибки случайной выборки.
- Неверная интерпретация: если вы отвергаете нулевую гипотезу, существует 4%-ная вероятность того, что вы делаете ошибку.
Примеры интерпретации P-значений
Следующие примеры иллюстрируют правильные способы интерпретации p-значений в контексте проверки гипотез.
Пример 1
Телефонная компания утверждает, что 90% ее клиентов довольны их услугами. Чтобы проверить это утверждение, независимый исследователь собрал простую случайную выборку из 200 клиентов и спросил их, довольны ли они своим сервисом, на что 85% ответили утвердительно. Значение p, связанное с данными выборки, оказалось равным 0,018.
Правильная интерпретация p-значения: если предположить, что 90% клиентов действительно удовлетворены их обслуживанием, исследователь получит наблюдаемую разницу, которую он действительно получил в своей выборке, или более экстремальную разницу в 1,8% аудитов из-за ошибки случайной выборки. .
Пример 2
Компания изобретает новый аккумулятор для телефонов. Компания утверждает, что эта новая батарея будет работать как минимум на 10 минут дольше, чем старая. Чтобы проверить это утверждение, исследователь берет простую случайную выборку из 80 новых батарей и 80 старых батарей. Новые батареи работают в среднем 120 минут при стандартном отклонении 12 минут, а старые батареи работают в среднем 115 минут при стандартном отклонении 15 минут. Значение p, полученное в результате теста на разницу в средних значениях населения, равно 0,011.
Правильная интерпретация p-значения: если предположить, что новая батарея работает столько же или меньше времени, чем старая батарея, исследователь получит наблюдаемую разницу или более крайнюю разницу в 1,1% исследований из-за случайной ошибки выборки.
Дисперсия
Дисперсия в статистике — это мера, которая показывает разброс между результатами. Если все они близки к среднему, дисперсия низкая. А если результаты сильно различаются — высокая.
Это один из основных показателей в статистическом анализе. Точка, вокруг которой считают разброс, — это обычно среднее арифметическое из выборки, математическое ожидание или какое-то целевое значение. А если смотрят, например, разброс между ответами на какой-то тестовый вопрос, в качестве центральной точки можно взять правильный ответ.
Термин «дисперсия» также встречается в физике, химии и биологии. Например, так называют явление, когда разные вещества не смешиваются друг с другом. А еще — разложение света на отдельные цвета, когда он проходит через призму. Но это другие понятия. Они не имеют отношения к статистике.

Освойте профессию «Data Scientist»
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.

Профессия / 24 месяца
Data Scientist
Решайте амбициозные задачи с помощью нейросетей

Что показывает дисперсия
Если говорить о всей выборке, дисперсия показывает, насколько разнородны результаты. Например, в одной группе почти все — шатены. В другой половина — шатены, а остальные — блондины, рыжие и брюнеты. Вторая группа более разнородная, в ней выше дисперсия.
Более близкие к реальному миру примеры:
- бизнесу дисперсия поможет рассчитать разброс между доходами за разные месяцы;
- ученый с помощью дисперсии поймет, насколько совпадают между собой результаты серии экспериментов.
Еще дисперсия показывает вероятность того, что конкретный результат будет далек от среднего. Например, средний рост россиянина мужского пола — 175 см. Но если остановить на улице случайного мужчину, вряд ли он окажется ровно 175 см ростом — скорее всего, выше или ниже. Дисперсия высокая — вероятность встретить «не среднее» значение выше.
В реальном мире это можно использовать так:
- проверять, насколько предсказуемы бизнес-показатели;
- оценивать риски — для компании, продвижения или даже обычной жизни.
Логика тут такая: чем меньше предсказуемости — тем больше хаоса и, соответственно, больше рисков.
Кто работает с дисперсией
- Ученые, которые могут пользоваться метриками из математической статистики, например для оценки результатов эксперимента.
- Статистики — они могут собирать данные по разным параметрам и потом оценивать их.
- Аналитики — статистика и в частности дисперсия используются в большинстве направлений Data Science, анализа данных, бизнес-аналитики и так далее.
- ML-инженеры — дисперсию учитывают, когда оценивают работу модели машинного обучения. Тут это будет разброс между ответами.
Формула дисперсии
Сначала дадим формальное определение, а потом объясним простыми словами. Дисперсия рассчитывается по формуле как среднее квадратичное отклонение от среднего значения:
- n — количество элементов,
- xi – i-й элемент в выборке,
- x — среднее арифметическое.
Звучит и выглядит сложно, но фактически все не так страшно. Вот как выглядит расчет пошагово:
- Найти среднее арифметическое x. Для этого нужно сложить все элементы и разделить полученную сумму на их количество.
- Потом от каждого элемента по очереди нужно отнять среднее арифметическое, а получившееся число возвести в квадрат. Это называется квадратами отклонения от среднего.
- Найденные квадраты отклонения от среднего нужно сложить.
- Сумму разделить на количество элементов в выборке.
Формула дисперсии случайной величины рассчитывается так:
Найти дисперсию случайной величины также можно по формуле, записанной в более удобном для расчетов виде:
Все перечисленное посчитать несложно — достаточно школьных знаний математики. А вот чтобы понять, почему формула именно такая, уже нужно разбираться в статистике.

Станьте дата-сайентистом и решайте амбициозные задачи с помощью нейросетей
Пример расчета дисперсии
Давайте посмотрим на практике, как рассчитать дисперсию. Для этого возьмем простую выборку из шести элементов. Будем считать, что это оценки группы с дополнительных занятий: [5, 2, 3, 5, 4, 5].
- Сначала найдем среднее арифметическое: (5 + 2 + 3 + 5 + 4 + 5) / 6 = 24 / 6 = 4.
- Теперь найдем квадраты отклонения от среднего:
- Сложим получившиеся квадраты: 1 + 4 + 1 + 1 + 0 + 1 = 8.
- Разделим сумму на количество элементов: 8 / 6 = 1,33.
Число 1,33 — это и есть дисперсия. Не слишком большая — большинство значений близко к среднему арифметическому, равному 4.
Как интерпретировать результат
Единицы измерения дисперсии — квадраты от единиц, в которых указаны значения в выборке. Например, в нашем расчете вышел разброс в 1,33 — это не баллы оценок, а их квадраты. Чтобы узнать, каким разброс будет в баллах, нужно будет взять квадратный корень из 1,33.
Какую дисперсию считать большой или маленькой — зависит от значений и выборки в целом. Например, для нашей небольшой выборки из чисел от 0 до 5 условная дисперсия в 4 считалась бы довольно большой. Но можно представить много выборок, где 4 — маленькое значение. Например, крупная выборка, где собраны числа от 100 до 1000.
Еще это зависит от сферы. Например, в условной медицине или точной инженерии даже небольшое число может быть значимой дисперсией.
Связь с другими показателями
Дисперсия тесно связана с несколькими другими показателями из статистики. Мы уже сказали про среднее арифметическое, но оно не единственное. Вот еще три важных показателя.
Стандартное отклонение. Это квадратный корень из дисперсии — выше мы говорили, что дисперсия представляет собой значение «в квадрате». А стандартное отклонение дает результат в тех же единицах измерения, что и числа в выборке. Если взять квадратный корень из нашей дисперсии в 1,33, получится 1,15 — значит, числа в выборке отклоняются от среднего на 1,15 балла. Отклоняются они опять же в среднем — для конкретного числа отклонение может быть и больше, и меньше.
Смещение. Смещение — это ошибка выборки. Например, когда исследователь собирал выборку, отобранные значения оказались похожими по какому-то фактору, а остальные он случайно проигнорировал. Например, отобрал для выборки фото с котами только белых котиков. В случае с машинным обучением это еще и «перекос» результатов, которые выдает модель: например, называет всех белых животных котами.
При чем тут дисперсия — она растет при маленьком смещении и падает при большом. Идеальная выборка — это маленькая дисперсия при большом смещении, но в реальности это практически невозможно. Поэтому приходится балансировать.
Ошибка прогнозирования. Статистику используют для прогнозирования. Но из-за дисперсии и смещения нельзя спрогнозировать все точно. Ошибка прогнозирования — это мера неточности. Чем она выше, тем сильнее прогноз может расходиться с реальным результатом. Существуют разные способы расчета этой ошибки, обычно для них используют реальные значения, если они известны.
Когда нужно применять дисперсию
Стандартное отклонение проще для понимания, так что может возникнуть вопрос: зачем пользоваться именно дисперсией. На практике пользуются и тем, и другим — зависит от задачи. Где-то считать показатели и анализировать удобнее через дисперсию, где-то — через стандартное отклонение. Благо, одно легко высчитывается через другое.
Например, дисперсия удобнее стандартного отклонения, если исследователь пользуется статистическим анализом или регрессией либо пишет теоретическую работу вроде лабораторной. Дисперсию бывает проще представить в процентах, она используется во множестве формул — так что смотреть нужно на саму задачу. Хотя и стандартное отклонение используют не реже.
Если вы хотите узнать больше про статистику, анализ данных и машинное обучение — приглашаем на курсы! Дадим много практических заданий и поможем получить первый реальный опыт.
Статьи по теме:
Что такое z-оценка? Что такое p-значение?
Большинство статистических тестов начинаются с определения нулевой гипотезы. Нулевая гипотеза для инструментов анализа структурных закономерностей (Группа инструментов Анализ структурных закономерностей и Список кластеров) – это полная пространственная хаотичность (ППХ) или самих объектов или значений, связанных с ними. Z-оценки и p-значения, полученные в результате анализа структурных закономерностей, свидетельствуют о том, можно ли отклонить нулевую гипотезу или нет. Как правило, вы запускаете один из инструментов анализа структурных закономерностей, предполагая, что z-оценка и р-значение будут свидетельствовать о возможном опровержении нулевой гипотезы. Это будет говорить о том, что ваши объекты или значения, связанные с ними, проявляют статистически значимую кластеризацию или дисперсию. Всякий раз, когда вы видите пространственную структуру, такую как кластеризация ландшафта (или пространственных данных), вы видите доказательства работы некоторых основных пространственных процессов, и, как географа или ГИС-аналитика, это может интересовать вас больше всего.
p-значение – это вероятность. Для анализа структурных закономерностей, это вероятность того, что наблюдаемые пространственные закономерности были созданы некоторым случайным процессом. Когда p-значение является очень маленьким, это означает, что это очень маловероятно (маленькая вероятность), что наблюдаемые пространственные закономерности – результат случайных процессов, таким образом, можно отклонить нулевую гипотезу. Вы можете задать вопрос: насколько маленький объект в действительности мал? Хороший вопрос. Смотрите таблицу и обсуждения ниже.
Z-оценки являются стандартными отклонениями. Если, например, инструмент возвращает z-оценку +2.5, вы сказали бы, что результат – это 2.5 стандартных отклонений. И z-оценки, и p-значения связаны со стандартным нормальным распределением, как показано ниже.

Очень высокие или очень низкие (отрицательные) z-оценки, связанные с очень маленькими p-значениями, располагаются в хвостах нормального распределения. Когда Вы запускаете инструмент анализа структурных закономерностей, и он приводит к маленьким p-значениями или очень высоким или очень низким z-оценкам, это указывает, что маловероятно, что наблюдаемая пространственная модель отражает теоретическую случайную структурную закономерность, представленную Вашей нулевой гипотезой.
Чтобы отклонить нулевую гипотезу, Вы должны сделать субъективное суждение относительно уровня риска, который вы готовы принять для того, чтобы ошибиться (для того, чтобы ложно отклонить нулевую гипотезу). Следовательно, прежде чем вы запустите пространственный статистический процесс, вы выбираете доверительный уровень. Типичные доверительные уровни 90, 95, или 99 процентов. Доверительный уровень 99 процентов был бы самым консервативным в этом случае, указывая, что вы не желаете отклонить нулевую гипотезу до тех пор, пока вероятность, что модель была создана случайным процессом, не является действительно маленькой (меньше чем 1-процентная вероятность).
Доверительные уровни
В таблице ниже показаны некорректированные критические p-значения и z-оценки для различных доверительных уровней.
Примечание:
Инструменты, которые позволяют применять FDR, будут использовать корректированные критические p-значения. Эти критические значения будут такими же или меньше, чем показанные в таблице ниже.
Рассмотрим пример. Критические значения z-оценки, используя 95-процентный доверительный уровень являются-1.96 и +1.96 стандартными отклонениями. Нескорректированное p-значение, связанное с 95-процентным доверительным уровнем, равно 0.05. Если z-оценка находится между -1.96 и +1.96, то нескорректированное p-значение будет больше чем 0.05, и вы не сможете отклонить нулевую гипотезу, поскольку показанная модель может, вероятно, быть результатом случайных пространственных процессов. Если z-оценка падает вне того диапазона (например,-2.5 или +5.4 стандартных отклонений), наблюдаемая пространственная модель, вероятно, слишком необычная, чтобы быть результатом случайного процесса, и p-значения будут маленькими, чтобы отклонить это. В этом случае возможно отклонить нулевую гипотезу и возобновить выяснение, что могло бы вызывать статистически существенную пространственную структуру в ваших данных.
Ключевая идея здесь состоит в том, что значения в середине нормального распределения (z-оценки такие как 0.19 или-1.2, например), представляют ожидаемый результат. Когда абсолютное значение z-оценки является большим, и вероятности являются маленькими (в хвостах нормального распределения), однако, вы видите что-то необычное и вообще очень интересное. Для инструмента Анализ горячих точек например, «необычный» означает статистически существенную «горячую» или «холодную» точку.
Коррекция FDR
Инструменты анализа локальных пространственных закономерностей, включая Анализ горячих точек и Анализ кластеров и выбросов (Anselin Локальный индекс Морана I) предлагают дополнительный параметр Применить коррекцию FDR . Когда этот параметр включен, Коррекция FDR снижает критический порог p-значения, показанный в таблице выше, чтобы использовать во множественном тестировании и в пространственной зависимости. Уменьшение, если происходит, является функцией числа входных объектов и используемой структуры окружения.
Инструменты анализа локальных пространственных закономерностей работают, рассматривая каждый объект в контексте окружающих объектов, и определяют, отличается ли локальная закономерность (целевой объект и его окружение) от глобальной (все объекты набора данных). Результаты вычислений z-оценки и p-значения, связанные с каждым объектом, позволяют определить, является ли различие статистически значимым или нет. Этот аналитический подход создает определенные сложности при множественном тестировании и изучении зависимостей.
Множественное тестирование – с уровнем достоверности 95 процентов, теория вероятности говорит о том, что существует только 5 шансов из 100, что пространственная закономерность может быть структурированной (кластеризованной или дисперсионной, например) и может быть связана со статистически значимым p-значением, когда на самом деле, пространственные процессы, создающие эту закономерность, являются случайными. В этом случае мы неверно отвергаем нулевую гипотезу, основываясь на статистически значимых p-значениях. Пять шансов из 100 выглядят достаточно убедительно, пока вы не поймете, что локальная пространственная статистика выполняет тест каждого объекта в наборе данных. Например, если имеется 10000 объектов, мы может получить до 500 ошибочных результатов.
Пространственная зависимость – близко расположенные объекты имеют тенденцию к сходности; они чаще, чем не пространственные данные, демонстрируют такой тип зависимости. Тем не менее, для многих статистических тестов необходимо, чтобы объекты были независимыми. Это необходимо для инструментов анализа локальных закономерностей потому, что пространственная зависимость может искусственно сглаживать статистическую значимость. Пространственная зависимость усугубляется инструментами локального анализа закономерностей, поскольку каждый объект оценивается в контексте его соседства, и близко расположенные объекты будут иметь множество одинаковых соседств. Такое совпадение подчеркивает пространственную зависимость.
Для обработки проблем, возникающих с множественным тестом и пространственными зависимостями, используются как минимум три 3 подхода. Первый подход – это игнорировать проблему, учитывая то, что отдельный тест, выполненный для каждого объекта набора данных, должен рассматриваться отдельно от других. Однако при этом подходе, весьма вероятно, что некоторые статистически значимые результаты будут неверны (выглядеть статистически значимыми при случайном характере базовых пространственных процессов). Второй подход состоит в применении классической процедуры множественного тестирования, например поправки Бонферрони или коррекции Сидак. Однако эти методы обычно слишком консервативны. Хотя они значительно снижают число ложноположительных результатов, они также пропускают имеющиеся статистически значимые результаты. Третий подход состоит в применении коррекции FDR, которая оценивает число ложноположительных результатов для данного уровня достоверности и соответственно корректирует критическое p-значение. При этом способе статистически значимые p-значения ранжируются от наименьших (самых строгих) до наибольших(наименее строгих), на основе оценки ложноположительных результатов, наименее строгие убираются из списка. Оставшиеся объекты со статистически значимыми p-значениями определяются по полям Gi_Bin или COType в выходном классе объектов. Не будучи идеальным, этот метод, как показывают эмпирические тесты, показывает лучшие результаты, чем выполнение каждого теста по-отдельности или применение традиционных, часто излишне консервативных, методов множественного теста. В разделе дополнительных ресурсов можно найти более подробные сведения о коррекции FDR.
Нулевая гипотеза и пространственная статистика
Некоторые инструменты статистики в наборе инструментов пространственной статистики представляют собой логически выведенные методы пространственного анализа структурных закономерностей, например, Пространственная автокорреляция (Global Moran’s I) , Анализ кластеров и выбросов (Anselin Local Moran’s I) и Анализ горячих точек (Getis-Ord Gi*) . Логически выведенные статистические показатели обоснованы в теории вероятности. Вероятность – мера случайности, и лежащие в основе все статистические тесты (любой прямо или косвенно) – вычисления вероятностей, которые оценивают роль случая на результат вашего анализа. Как правило, с традиционными (не пространственными) статистическими показателями, вы работаете со случайной выборкой и пытаетесь определить вероятность, что ваша выборка данных – хорошее представление (рефлексивно) населения в целом. Как пример, вы могли бы спросить, «Каковы шансы, что результаты моего опроса избирателей (показывающие, что кандидат А слегка превзойдет кандидата Б) отразят заключительные результаты выборов?» Но в большинстве случаев работая с пространственными статистическими показателями, включая упомянутую выше пространственную автокорреляцию, как правило, вы используете все данные, которые доступны в области исследования (все преступления, все случаи болезни, атрибуты для каждого переписного участка, и так далее). Когда вы вычисляете статистическую величину для всего населения, у вас больше нет оценки вообще. Перед вами факт. Следовательно, более нет никакого смысла говорить о подобии или вероятностях. Таким образом, как могут инструменты анализа пространственных структурных закономерностей, часто применяемые ко всем данным в области исследования, законно сообщить о вероятностях? Ответ – то, что они могут сделать это, постулируя через нулевую гипотезу, что данные, фактически, являются частью некоторого более многочисленного населения. Рассмотрим это более подробно.
Рандомизация нулевой гипотезы – где необходимо, инструменты из набора инструментов пространственной статистики используют рандомизацию нулевой гипотезы в качестве основы для теста статистической значимости. Рандомизация нулевой гипотезы постулирует, что наблюдаемая пространственная модель ваших данных представляет одну из многих (n!) возможных пространственных организаций данных. Если бы вы могли собрать значения данных и бросить их на объекты в вашей области исследования, у вас было бы одно возможное пространственное расположение этих значений. (Отметьте, что собирание ваших значений данных и их произвольных бросок являются примером случайного пространственного процесса). Рандомизация нулевой гипотезы утверждает, что, если бы Вы могли сделать это упражнение (собрать их и бросить) бесконечное количество раз, в большинстве случаев вы бы создали структуру, которая не будет заметно отличаться от наблюдаемой структуры (ваши реальные данные). Иногда вы могли бы случайно бросить все самые высокие значения в один и тот же угол вашей области исследования, но вероятность такого исхода является маленькой. Рандомизация нулевой гипотезы утверждает, что ваши данные – одна из многих, многих, многих возможных версий полной пространственной хаотичности. Значения данных фиксированы; могла измениться только их пространственная организация.
Нормализация нулевой гипотезы – общая альтернативная нулевая гипотеза, не реализованная для набора инструментов пространственной статистики, является нормализацией нулевой гипотезы. Нормализация Нулевой гипотезы постулирует, что наблюдаемые величины получены из бесконечно большого, нормально распределенного населения посредством некоторого случайного процесса осуществления выборки. С разной выборкой, вы получили бы различные значения, но вы будете все еще ожидать, что те значения будут представительны для большего распределения. Нормализация нулевой гипотезы утверждает, что значения представляют одну из многих возможных выборок значений. Если вы могли бы привести свои наблюдаемые данные к нормальной кривой и хаотично выбирать значения из того распределения, чтобы бросить их на вашу область исследования, большую часть раз вы произведете модель и распределение значений, которые заметно не отличались бы от наблюдаемого образца/распределения (ваши реальные данные). Нормализация нулевой гипотезы утверждает, что ваши данные и их организация – одна из многих, многих, многих возможных случайных выборок. Ни значения данных, ни их пространственное расположение не установлены. Нормализация нулевой гипотезы является только соответствующей, когда значения данных нормально распределены.
Дополнительные источники
- Ebdon, David. Statistics in Geography. Blackwell, 1985.
- Mitchell, Andy. The ESRI Guide to GIS Analysis, Volume 2. ESRI Press, 2005.
- Goodchild, Michael F. Spatial Autocorrelation. Catmog 47, Geo Books, 1986
- Caldas de Castro, Marcia, and Burton H. Singer. «Controlling the False Discovery Rate: A New Application to Account for Multiple and Dependent Test in Local Statistics of Spatial Association.» Geographical Analysis38, pp 180-208, 2006.
Связанные разделы
- Кластеризация с высокими/низкими значениями (Глобальный индекс Getis-Ord G)
- Пространственная автокорреляция (Глобальный индекс Морана I)
- Анализ кластеров и выбросов (Anselin Локальный индекс Морана I)
- Анализ горячих точек
- Метод наименьших квадратов (МНК)
- Оптимизированный анализ горячих точек
- Анализ возникновения горячих точек
Статистика: как рассчитать стандартное отклонение и другие статистические характеристики


Статистические величины, такие как стандартное отклонение и математическое ожидание, полезны при оценке эффективности или характеристик устройства, системы или процесса, смоделированных с помощью COMSOL Multiphysics ® . В этой статье мы рассмотрим функции, графики и другие инструменты COMSOL Multiphysics, предназначенные для расчёта и визуализации статистических величин.
Статистика: вводный обзор
Статистические методы позволяют рассчитать количественные характеристики случайной величины или большого массива данных. Ниже в таблице перечислены некоторые статистические величины, а также названия операторов и операций над массивами данных, которые используются для их вычисления в COMSOL Multiphysics:
| Величина | Параметр | Оператор | Операция над массивом данных |
|---|---|---|---|
| Среднее значение или математическое ожидание | \mu | mean, timeavg | Average |
| Стандартное отклонение | \sigma | stddev | Standard deviation |
| Дисперсия | Var, \sigma^2 | – | Variance |
Теперь расшифруем смысл каждой из перечисленных выше статистических величин:
- Среднее или математическое ожидание (в уравнении ниже обозначается как \mu ) равно сумме всех значений, отнесённой к числу элементов в массиве данных. Этот статистический показатель даёт полезную информацию об уровне любой колеблющейся величины. Среднее значение чувствительно к так называемым выбросам (то есть элементам выборки, значения которых сильно отличаются от значений других элементов). Ещё одним, схожим по смыслу статистическим параметром является медиана — срединное значение, которое находится в середине упорядоченного по возрастанию массива данных (либо полусумма соседних значений, если число элементов в массиве чётное). Например, оператор timeavg в COMSOL Multiphysics позволяет рассчитать среднее значение зависящей от времени величины в заданном интервале времени.
- Стандартное отклонение (обозначается ниже как \sigma ) характеризует степень отклонения данных от среднего значения. Определяется как квадратный корень из дисперсии. В отличие от дисперсии, стандартное отклонение исчисляется в тех же единицах измерения, что и исходные данные.
- Дисперсия (обозначается как Var) является мерой разброса значений относительно ее математического ожидания. Единица измерения дисперсии — это квадрат единицы измерения исходных данных.
Математическое ожидание \mu можно рассчитать по формуле:
\mu(X)=\frac<1>\sum_^nx_i \cdot
Следующее соотношение позволяет определить дисперсию:
Var(X)=\frac<1>\sum_^(x_i-\mu)^2
Здесь X — это величина, дисперсию (и среднее значение) которой нужно рассчитать, x_i — массив значений этой величины, \mu — математическое ожидание. Это определение дисперсии справедливо для массива данных с фиксированным числом элементов.
В COMSOL Multiphysics X и x_i представляют собой фиксированный массив данных.
Стандартное отклонение \sigma равно квадратному корню из дисперсии:
\sigma = \sqrt>Эти формулы можно легко обобщить на случай расчёта статистических величин, определённых на геометрических объектах, если заменить суммирование на интегрирование по пространству. Именно такое обобщение и используется в COMSOL Multiphysics. Интегральная форма соотношения для расчёта средней величины X по области \Omega имеет вид:
\mu(X) = \frac<1><|\Omega|>\int_\Omega x d\Omega
и, аналогично, дисперсия переменной X по области \Omega равна
Var(X) = \frac<1><|\Omega|>\int_\Omega (x-\mu(x))^2 d\Omega
где |\Omega| — размер области (объём, площадь или длина, в зависимости от пространственной размерности модели).
В следующих параграфах мы объясним, как использовать все эти операции и операторы при моделировании в COMSOL Multiphysics.
Статистические величины в COMSOL Multiphysics
Нелокальные операторы
Позже мы рассмотрим, как использовать встроенный оператор stddev для вычисления стандартного отклонения. Но перед этим давайте обсудим, как рассчитать среднее значение величины, например, в объёме или вдоль границ: кликните правой кнопкой мыши по узлу Definitions в текущем компоненте Component, а затем выберите пункт Average в меню Nonlocal Couplings. Так мы добавляем оператор осреднения с именем по умолчанию aveop1 , а затем в настройках этого оператора указываем тип геометрического объекта Geometric entity level (например, Boundary) и выбираем сам объект (например, границы области), в пределах которого нужно выполнить осреднение. Аналогичным образом в дерево модели можно добавить операторы для расчёта интегралов, максимальных и минимальных значений.
Добавленные операторы можно использовать как в процессе расчёта модели, так и на этапе обработки результатов. Например, в задачах вычислительной гидродинамики с помощью оператора осреднения можно рассчитать среднюю скорость среды в выходном сечении расчётной области. Для этого в ветке Results дерева модели к узлу Derived Values нужно добавить подузел Global Evaluation, в окне настройки которого нужно ввести выражение aveop1(spf.U) и нажать кнопку Evaluate. После этого рассчитанные значения средней скорости для каждого сохранённого момента времени нестационарной задачи появятся в окне Table.
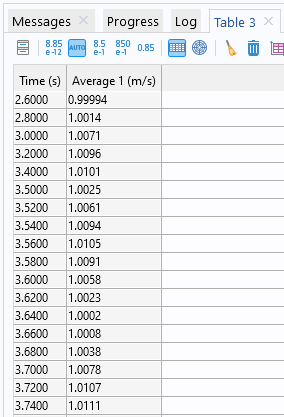
Окно Table, в которое выводятся значения средней скорости для каждого сохранённого момента времени.
Стандартное отклонение или дисперсию можно рассчитать с помощью повторного использования нелокального оператора: сначала с помощью оператора вычисляется среднее значение, а затем тот же оператор используется для расчёта стандартного отклонения или дисперсии. Например, в нашем примере с гидродинамической задачей для определения стандартного отклонения давления на выходной границе можно воспользоваться оператором осреднения aveop1 , заданным на выходной границе. Для этого в окне настройки узла Global Evaluation введём выражение sqrt(aveop1((aveop1(p)-p)^2)) .
Упрощение выражений с помощью оператора Expression Operator
Выражение sqrt(aveop1((aveop1(p)-p)^2)) , которое мы использовали выше, длинновато. Чтобы упростить использование этого выражения для настройки расчётной модели, можно воспользоваться оператором Expression Operator. Для этого сначала включим опцию Variable Utilities в разделе General окна настройки дерева модели Show More Options. Затем добавим узел Expression Operator из контекстного меню Variable Utilities, которое можно вызвать, кликнув правой кнопкой мыши по узлу Definitions текущего компонента модели Component. В окне настройки узла Expression Operator даём новому оператору название, например, stdop1 и вводим его определение, используя то же самое выражение, но уже с произвольным аргументом, который мы обозначим, скажем, pin :
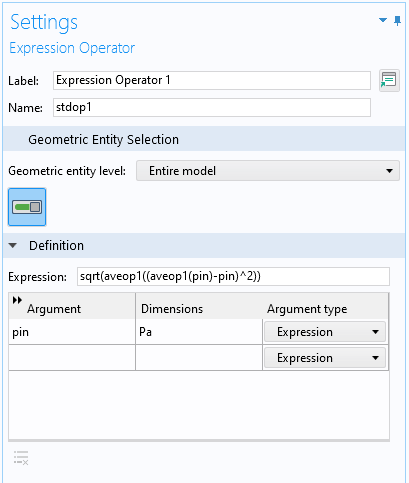
Окно настройки Settings узла Expression Operator, который позволяет дать определение упрощённому оператору stdop1 для расчёта стандартного отклонения.
Теперь этот оператор можно использовать для обработки результатов моделирования, вводя команду stdop1(p) вместо sqrt(aveop1((aveop1(p)-p)^2)) .
Производные величины
На этапе обработки результатов можно добавить узлы для расчёта среднего по объёму Volume Average, по поверхности Surface Average и вдоль контура Line Average, если воспользоваться контекстным меню узла Derived Values и выбрать соответствующую команду из подменю Average. Аналогично можно добавить узлы для вычисления интегральных Integration, максимальных Maximum и минимальных Minimum значений.
Преобразование результатов нестационарных и параметрических исследований
Для обработки массива данных, полученных в результате нестационарного, параметрического исследования или исследования на собственные значения, с помощью узла Point Evaluation можно вычислить следующие значения:
- Среднее
- Интегральное
- Максимальное или минимальное
- Среднеквадратическое (RMS)
- Стандартное отклонение
- Дисперсию
Результатом каждой из этих операций является одно число, которое представляет собой, например, среднее значение всех результатов параметрического исследования или стандартное отклонение переменной нестационарной модели в точке.
Встроенные операторы
В COMSOL Multiphysics доступно большое количество физических переменных, а также встроенных физических и математических констант, функций и операторов, которые можно использовать для обработки и визуализации результатов моделирования. Вы можете ввести имя непосредственно в любое поле Expression или выбрать из списка, нажав кнопку Add Expression или Replace Expression (кнопки расположены на панели инструментов раздела Expression). На скриншоте ниже показаны операторы из группы Integration and statistics COMSOL Multiphysics ® версии 6.0:

Встроенные операторы группы Integration and statistics.
Особый интерес представляет оператор stddev для вычисления стандартного отклонения. С его помощью можно рассчитать стандартное отклонение давления на выходной границе в описанном выше примере, если ввести выражение stddev(‘comp1.aveop1’,p) . Это более простой и эффективный синтаксис, чем последовательное обращение к оператору осреднения, которые мы использовали выше для определения стандартного отклонения. Отметим, что имена компонентов и операторов в выражении приведены для примера, и в ваших моделях они могут быть иными.
Стандартное отклонение и математическое ожидание: пример
Давайте рассчитаем парочку статистических характеристик в нестационарной модели обтекания цилиндра Flow Past a Cylinder model, которую можно найти в разделе Fluid Dynamics библиотеки приложений Application Library в COMSOL Multiphysics. Вычислим следующие величины:
- Среднее значение и стандартное отклонение давления в расчётной области во всём временном интервале моделирования
- Среднее значение и стандартное отклонение скорости в некоторой точке выходной границы во всём временном интервале моделирования
Построенный по умолчанию график в модели обтекания цилиндра Flow Past a Cylinder, показывающий распределение скорости и частиц в момент времени 7 с.
Среднее значение и стандартное отклонение давления в домене и на выходной границе
Чтобы определить среднее значение и стандартное отклонение давления в какой-то области, сначала добавим узел Average с названием оператора, скажем, aveop2 , и выберем область осреднения. (В рассматриваемой геометрической модели существует только один домен). После завершения расчёта добавим подузел Global Evaluation к узлу Derived Values ветки Results дерева модели, и в окне настройки этого подузла введём выражение aveop2(p) . Искомое значение среднего по объёму давления появится в окне Table для всех моментов времени, указанных в списке Time selection (по умолчанию выбраны все сохранённые моменты времени). Если нужно рассчитать среднее по времени значение осреднённого по объёму давления, выберите опцию Average из списка Transformation в разделе Data Series Operation. В результате получится одно скалярное число для среднего по времени значения осреднённого давления. Чтобы вывести стандартное отклонение на каждом шаге по времени, введите также выражение stddev(‘comp1.aveop2’,p) (или воспользуйтесь любым из упомянутых выше вариантов расчёта).
Аргумент оператора stddev не обязательно должен быть средним значением. Например, в качестве аргумента можно ввести оператор интегрирования, но результатом по-прежнему будет правильно рассчитанное значение стандартного отклонения. Кроме того, его можно использовать в комбинации с оператором timeavg , чтобы получить тот же результат, что и в результате использования операций над массивами данных. Это можно сделать с помощью выражения типа stddev(‘timeavg’,t1,t2,expr) , где t1 и t2 — начальный и конечный моменты временного интервала, а expr — это выражение, которое нужно осреднить в заданном временном интервале. Например, чтобы построить график стандартного отклонения давления во временной области для каждой точки выходной границы в интервале времени от 6 до 7 секунд, можно использовать выражение stddev(‘timeavg’,6,7,p) .
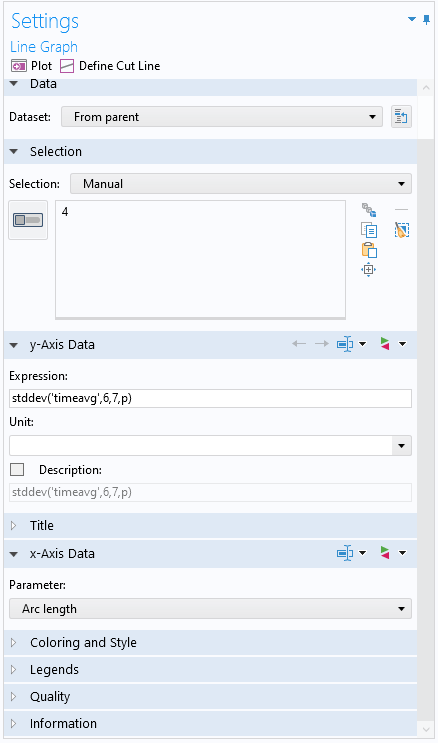
Окно настройки Settings графика Line Graph, в котором используется выражение для расчёта стандартного отклонения во временной области в интервале времени от 6 до 7 секунд.
График показывает, что наименьшее значение стандартного отклонения давления достигается в срединной точке выходной границы.
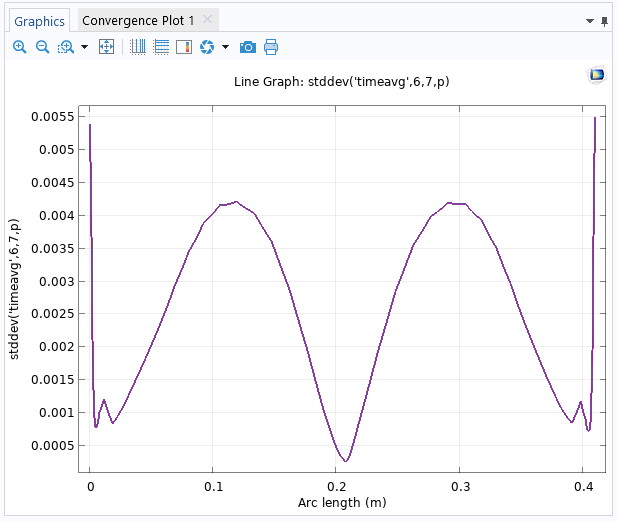
Одномерный график Line Graph стандартного отклонения давления во временной области на выходной границе.
Среднее значение и стандартное отклонение скорости на выходной границе
Если нужно определить среднее значение и стандартное отклонение скорости в срединной точке выходной границы на каждом шаге по времени, то сначала надо найти значение скорости в этой точке. Это можно сделать двумя способами:
- Добавить в геометрическую модель точку посередине выходной границы, даже если эта точка не используется в самой модели
- Добавить набор данных Cut Point (в нашем случае Cut Point 2D), а затем задать координаты точки в окне настройки набора данных
Чтобы найти скорость в средней точке, используйте узел Point Evaluation, в окне настройки которого либо выберите нужную точку в геометрической модели, либо выберите в качестве входных данных для графика набор данных Cut Point 2D. Затем в качестве входной переменной для графика укажите, например, spf.U . В разделе Data Series Operation окна настройки выберите Average или Standard deviation. Кликнув по кнопке Evaluate, расположенной в верхней части окна настройки Settings, вы получите график среднего значения или стандартного отклонения (оба в м/с) для скорости в средней точке выходной границы на каждом сохранённом временном шаге исследования.

Среднее значение и стандартное отклонение скорости выводятся в таблицу в окне Table.
Гистограммы
С помощью гистограмм удобно визуализировать форму и разброс некоторых массивов данных. В COMSOL Multiphysics встроены следующие типы гистограмм:
- Гистограммы Histogram (1D и 2D графики) показывают, как та или иная величина распределена в пространстве в пределах геометрических объектов. В одномерных гистограммах по оси x отложены значения величины (в виде интервалов), а по оси y — общее число элементов в каждом интервале.
- Табличные гистограммы Table Histogram (1D и 2D графики) аналогичны обычным гистограммам Histogram, но строятся на основе данных из таблицы или расчётной группы.
- Матричные гистограммы Matrix Histogram (только 2D графики) позволяют визуализировать матрицы в виде 2D гистограмм.
При построении графиков Histogram и Table Histogram можно выбрать, хотите вы задать количество столбиков на гистограмме или диапазон значений для каждого столбика гистограммы. Для 2D гистограмм можно добавить подузел Height Expression, чтобы придать столбикам трёхмерный вид за счет использования оси z, как показано на рисунке ниже.
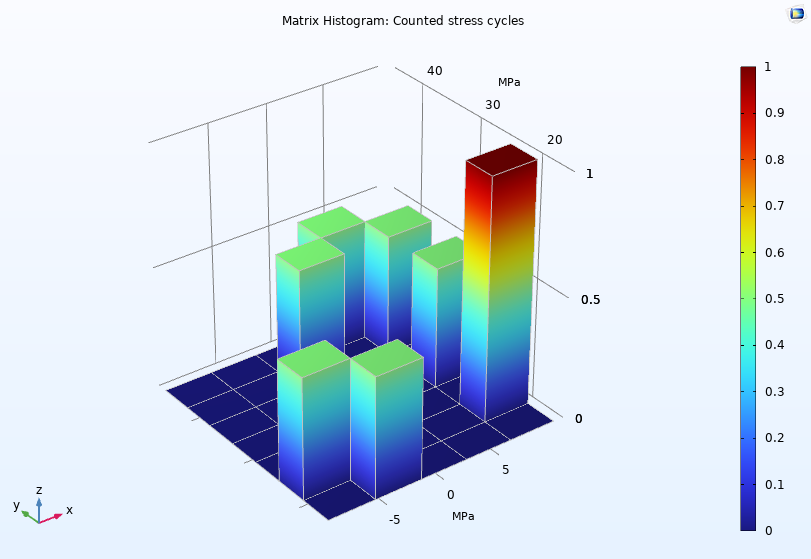
График Matrix Histogram показывает число циклов нагружения, рассчитанное в верификационной модели Cycle Counting in Fatigue Analysis — Benchmark model.
Оценка неопределённости и статистика
С помощью модуля «Оценка неопределённости», дополняющего функционал среды COMSOL Multiphysics, можно получить статистические данные, связанные с количественной оценкой неопределённости, непосредственно в таблицах выходных данных. Например, для анализа распространения неопределенности с использованием неадаптивных суррогатных режимов гауссовского процесса доступны следующие четыре таблицы:
- Таблица доверительных интервалов QoI Confidence interval, в которой для каждой целевой переменной выводятся данные о математическом ожидании, стандартном отклонении, минимальном и максимальном значениях, а также о доверительных интервалах для доверительных вероятностей 90%, 95% и 99%.
- Таблица UP predicted QoI, в которой приведены спрогнозированные суррогатной моделью значения целевых переменных для точек выборки метода Монте-Карло.
- Таблица спрогнозированных значений стандартного отклонения UP predicted standard deviation, в которой указаны спрогнозированные суррогатной моделью стандартные отклонения для точек выборки метода Монте-Карло. Эти данные можно интерпретировать как встроенную оценку погрешности суррогатной модели.
- Таблица максимальных значений энтропии Maximum entropy, в которой указаны максимальные относительные значения стандартного отклонения для каждой целевой переменной.
При использовании адаптивной суррогатной модели гауссовского процесса в группу выходных таблиц также добавляются четыре соответствующие адаптивные таблицы результатов. Они содержат информацию о результатах на всех этапах адаптации.
Дальнейшие шаги
В качестве следующего шага попробуйте использовать некоторые из этих статистических инструментов в своих собственных расчётных моделях; так вы сможете получить статистические характеристики и количественные оценки целевых переменных или параметров. Если у вас возникли вопросы по данной теме, свяжитесь с COMSOL с помощью этой кнопки.