Какой командой можно выполнить обновление конфигурации postgresql
Для обновления данных в базе данных PostgreSQL применяется команда UPDATE . Она имеет следующий общий формальный синтаксис:
UPDATE имя_таблицы SET столбец1 = значение1, столбец2 = значение2, . столбецN = значениеN [WHERE условие_обновления]
Например, увеличим у всех товаров цену на 3000:
UPDATE Products SET Price = Price + 3000;
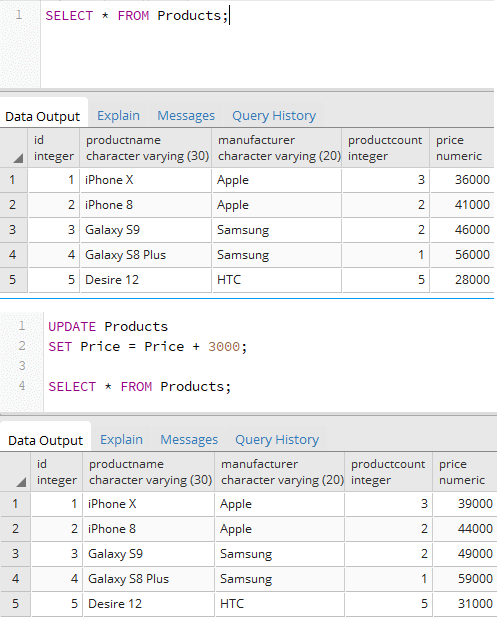
В данном случае обновление касается всех строк. С помощью выражения WHERE можно с помощью условию конкретизировать обновляемые строки — если строка соответствует условию, то она будет обновляться. Например, изменим название производителя с «Samsung» на «Samsung Inc.»:
UPDATE Products SET Manufacturer = 'Samsung Inc.' WHERE Manufacturer = 'Samsung';
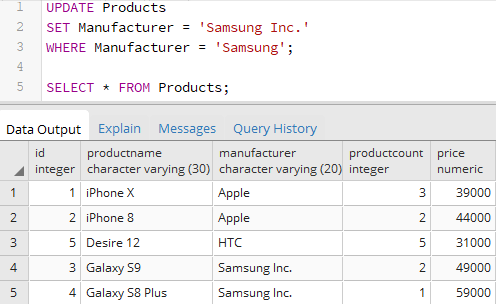
Также можно обновлять сразу несколько столбцов:
UPDATE Products SET Manufacturer = 'Samsung', ProductCount = ProductCount + 3 WHERE Manufacturer = 'Samsung Inc.';
Какой командой можно выполнить обновление конфигурации postgresql
Имена всех параметров являются регистронезависимыми. Каждый параметр принимает значение одного из пяти типов: логический, строка, целое, число с плавающей точкой или перечисление. От типа значения зависит синтаксис установки этого параметра:
Логический: Значения могут задаваться строками on , off , true , false , yes , no , 1 , 0 (регистр не имеет значения), либо как достаточно однозначный префикс одной из этих строк.
Строка: Обычно строковое значение заключается в апострофы (при этом внутренние апострофы дублируются). Однако если значение является простым числом или идентификатором, апострофы обычно можно опустить. (Значения, совпадающие с ключевыми словами SQL, всё же требуют заключения в апострофы в некоторых контекстах.)
Число (целое или с плавающей точкой): Значения числовых параметров могут задаваться в обычных форматах, принятых для целых чисел или чисел с плавающей точкой; если параметр целочисленный, дробные значения округляются до ближайшего целого. Кроме того, целочисленные параметры принимают значения в шестнадцатеричном (с префиксом 0x ) и восьмеричном (с префиксом 0 ) виде, но дробная часть в таких случаях исключена. Разделители разрядов в значениях использовать нельзя. Заключать в кавычки требуется только значения в шестнадцатеричном виде.
Число с единицей измерения: Некоторые числовые параметры задаются с единицами измерения, так как они описывают количества информации или времени. Единицами могут быть байты, килобайты, блоки (обычно восемь килобайт), миллисекунды, секунды или минуты. При указании только числового значения для такого параметра единицей измерения будет считаться установленная для него единица по умолчанию, которая указывается в pg_settings . unit . Для удобства параметры также можно задавать, указывая единицу измерения явно, например, задать ‘120 ms’ для значения времени. При этом такое значение будет переведено в основную единицу измерения параметра. Заметьте, что для этого значение должно записываться в виде строки (в апострофах). Имя единицы является регистронезависимым, а между ним и числом допускаются пробельные символы.
Допустимые единицы информации: B (байты), kB (килобайты), MB (мегабайты), GB (гигабайты) и TB (терабайты). Множителем единиц информации считается 1024, не 1000.
Если с единицей измерения задаётся дробное значение, оно будет округлено до следующей меньшей единицы, если такая имеется. Например, значение 30.1 GB будет преобразовано в 30822 MB , а не в 32319628902 B . Если параметр имеет целочисленный тип, после преобразования единиц измерения значение окончательно округляется до целого.
19.1.2. Определение параметров в файле конфигурации
Самый основной способ установки этих параметров — определение их значений в файле postgresql.conf , который обычно находится в каталоге данных. При инициализации каталога кластера БД в этот каталог помещается копия стандартного файла. Например, он может выглядеть так:
# Это комментарий log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
Каждый параметр определяется в отдельной строке. Знак равенства в ней между именем и значением является необязательным. Пробельные символы в строке не играют роли (кроме значений, заключённых в апострофы), а пустые строки игнорируются. Знаки решётки ( # ) обозначают продолжение строки как комментарий. Значения параметров, не являющиеся простыми идентификаторами или числами, должны заключаться в апострофы. Чтобы включить в такое значение собственно апостроф, его следует продублировать (предпочтительнее) или предварить обратной косой чертой. Если один и тот же параметр определяется в файле конфигурации неоднократно, действовать будет только последнее определение, остальные игнорируются.
Параметры, установленные таким образом, задают значения по умолчанию для данного кластера. Эти значения будут действовать в активных сеансах, если не будут переопределены. В следующих разделах описывается, как их может переопределить администратор или пользователь.
Основной процесс сервера перечитывает файл конфигурации заново, получая сигнал SIGHUP ; послать его проще всего можно, запустив pg_ctl reload в командной строке или вызвав SQL-функцию pg_reload_conf() . Основной процесс сервера передаёт этот сигнал всем остальным запущенным серверным процессам, так что существующие сеансы тоже получают новые значения (после того, как завершится выполнение текущей команды клиента). Также возможно послать этот сигнал напрямую одному из серверных процессов. Учтите, что некоторые параметры можно установить только при запуске сервера; любые изменения их значений в файле конфигурации не будут учитываться до перезапуска сервера. Более того, при обработке SIGHUP игнорируются неверные значения параметров (но об этом сообщается в журнале).
В дополнение к postgresql.conf в каталоге данных PostgreSQL содержится файл postgresql.auto.conf , который имеет тот же формат, что и postgresql.conf , но предназначен для автоматического изменения, а не для редактирования вручную. Этот файл содержит параметры, задаваемые командой ALTER SYSTEM . Он считывается одновременно с postgresql.conf и заданные в нём параметры действуют таким же образом. Параметры в postgresql.auto.conf переопределяют те, что указаны в postgresql.conf .
Вносить изменения в postgresql.auto.conf можно и с использованием внешних средств. Однако это не рекомендуется делать в процессе работы сервера, так эти изменения могут быть потеряны при параллельном выполнении команды ALTER SYSTEM . Внешние программы могут просто добавлять новые определения параметров в конец файла или удалять повторяющиеся определения и/или комментарии (как делает ALTER SYSTEM ).
Системное представление pg_file_settings может быть полезным для предварительной проверки изменений в файлах конфигурации или для диагностики проблем, если сигнал SIGHUP не даёт желаемого эффекта.
19.1.3. Управление параметрами через SQL
В PostgreSQL есть три SQL-команды, задающие для параметров значения по умолчанию. Уже упомянутая команда ALTER SYSTEM даёт возможность изменять глобальные значения средствами SQL; она функционально равнозначна редактированию postgresql.conf . Кроме того, есть ещё две команды, которые позволяют задавать значения по умолчанию на уровне баз данных и ролей:
Команда ALTER DATABASE позволяет переопределить глобальные параметры на уровне базы данных.
Значения, установленные командами ALTER DATABASE и ALTER ROLE , применяются только при новом подключении к базе данных. Они переопределяют значения, полученные из файлов конфигурации или командной строки сервера, и применяются по умолчанию в рамках сеанса. Заметьте, что некоторые параметры невозможно изменить после запуска сервера, поэтому их нельзя установить этими командами (или командами, перечисленными ниже).
Когда клиент подключён к базе данных, он может воспользоваться двумя дополнительными командами SQL (и равнозначными функциями), которые предоставляет PostgreSQL для управления параметрами конфигурации:
Команда SHOW позволяет узнать текущее значение всех параметров. Соответствующая ей функция — current_setting(имя_параметра text) .
Кроме того, просмотреть и изменить значения параметров для текущего сеанса можно в системном представлении pg_settings :
Запрос на чтение представления выдаёт ту же информацию, что и SHOW ALL , но более подробно. Этот подход и более гибкий, так как в нём можно указать условия фильтра или связать результат с другими отношениями.
Выполнение UPDATE для этого представления, а именно присваивание значения столбцу setting , равносильно выполнению команды SET . Например, команде
SET configuration_parameter TO DEFAULT;
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
19.1.4. Управление параметрами в командной строке
Помимо изменения глобальных значений по умолчанию и переопределения их на уровне базы данных или роли, параметры PostgreSQL можно изменить, используя средства командной строки. Управление через командную строку поддерживают и сервер, и клиентская библиотека libpq .
При запуске сервера, значения параметров можно передать команде postgres в аргументе командной строки -c . Например:
postgres -c log_connections=yes -c log_destination='syslog'
Параметры, заданные таким образом, переопределяют те, что были установлены в postgresql.conf или командой ALTER SYSTEM , так что их нельзя изменить глобально без перезапуска сервера.
При запуске клиентского сеанса, использующего libpq , значения параметров можно указать в переменной окружения PGOPTIONS . Заданные таким образом параметры будут определять значения по умолчанию на время сеанса, но никак не влияют на другие сеансы. По историческим причинам формат PGOPTIONS похож на тот, что применяется при запуске команды postgres ; в частности, в нём должен присутствовать флаг -c . Например:
env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
19.1.5. Упорядочение содержимого файлов конфигурации
PostgreSQL предоставляет несколько возможностей для разделения сложных файлов postgresql.conf на вложенные файлы. Эти возможности особенно полезны при управлении множеством серверов с похожими, но не одинаковыми конфигурациями.
Помимо присваиваний значений параметров, postgresql.conf может содержать директивы включения файлов, которые будут прочитаны и обработаны, как если бы их содержимое было вставлено в данном месте файла конфигурации. Это позволяет разбивать файл конфигурации на физически отдельные части. Директивы включения записываются просто:
include 'имя_файла'
Если имя файла задаётся не абсолютным путём, оно рассматривается относительно каталога, в котором находится включающий файл конфигурации. Включения файлов могут быть вложенными.
Кроме того, есть директива include_if_exists , которая работает подобно include , за исключением случаев, когда включаемый файл не существует или не может быть прочитан. Обычная директива include считает это критической ошибкой, но include_if_exists просто выводит сообщение и продолжает обрабатывать текущий файл конфигурации.
Файл postgresql.conf может также содержать директивы include_dir , позволяющие подключать целые каталоги с файлами конфигурации. Они записываются так:
include_dir 'каталог'
Имена, заданные не абсолютным путём, рассматриваются относительно каталога, содержащего текущий файл конфигурации. В заданном каталоге включению подлежат только файлы с именами, оканчивающимися на .conf . При этом файлы с именами, начинающимися с « . », тоже игнорируются, для предотвращения ошибок, так как они считаются скрытыми в ряде систем. Набор файлов во включаемом каталоге обрабатывается по порядку имён (определяемому правилами, принятыми в C, т. е. цифры идут перед буквами, а буквы в верхнем регистре — перед буквами в нижнем).
Включение файлов или каталогов позволяет разделить конфигурацию базы данных на логические части, а не вести один большой файл postgresql.conf . Например, представьте, что в некоторой компании есть два сервера баз данных, с разным объёмом ОЗУ. Скорее всего при этом их конфигурации будут иметь общие элементы, например, параметры ведения журналов. Но параметры, связанные с памятью, у них будут различаться. Кроме того, другие параметры могут быть специфическими для каждого сервера. Один из вариантов эффективного управления такими конфигурациями — разделить изменения стандартной конфигурации на три файла. Чтобы подключить эти файлы, можно добавить в конец файла postgresql.conf следующие директивы:
include 'shared.conf' include 'memory.conf' include 'server.conf'
Общие для всех серверов параметры будут помещаться в shared.conf . Файл memory.conf может иметь два варианта — первый для серверов с 8ГБ ОЗУ, а второй для серверов с 16 ГБ. Наконец, server.conf может содержать действительно специфические параметры для каждого отдельного сервера.
Также возможно создать каталог с файлами конфигурации и поместить туда все эти файлы. Например, так можно подключить каталог conf.d в конце postgresql.conf :
include_dir 'conf.d'
Затем можно дать файлам в каталоге conf.d следующие имена:
00shared.conf 01memory.conf 02server.conf
Такое именование устанавливает чёткий порядок подключения этих файлов, что важно, так как если параметр определяется несколько раз в разных файлах конфигурации, действовать будет последнее определение. В рамках данного примера, установленное в conf.d/02server.conf значение переопределит значение того же параметра, заданное в conf.d/01memory.conf .
Вы можете применить этот подход и с описательными именами файлов:
00shared.conf 01memory-8GB.conf 02server-foo.conf
При таком упорядочивании каждому варианту файла конфигурации даётся уникальное имя. Это помогает исключить конфликты, если конфигурации разных серверов нужно хранить в одном месте, например, в репозитории системы управления версиями. (Кстати, хранение файлов конфигурации в системе управления версиями — это ещё один эффективный приём, который стоит применять.)
| Пред. | Наверх | След. |
| Глава 19. Настройка сервера | Начало | 19.2. Расположения файлов |
Как обновить базу данных PostgreSQL — pg_upgrade

В сегодняшней статье мы поговорим о том как обновить кластер базы данных PostgresSQL до последней версии с помощью утилиты pg_upgrade. Обновления будем проводить из 13 версии на 14.
Рано или поздно вы столкнетесь с такой проблемой как обновить базу данных PostgresSQL до последней версии. Обновлять базу данных является очень важной и востребованной задачей в жизни администратора баз данных, так как разработчики СУБД PostgresSQL с каждой новой версией устраняют различные проблемы с производительностью и безопасностью, а так же добавляют новые функции.
Обновить базу данных можно двумя способами.
Первый способ заключается в том чтобы сначала сделать резервную копию всей базы данных с помощью утилиты pg_dump или pg_dumpall, затем удалить старую базу данных и вместо старой развернуть новую, и только после теми же утилитами pg_dump или pg_dumpall восстановить резервную копию уже в новую СУБД PostgresSQL. Этот способ отлично подходит в том случаи если у вас размер вашей базы данных не очень велик в размерах, а то если у вас размер базы данных превышает 100 гигабайт то на обновления уйдет очень много времени.
Второй способ заключается в том, чтобы использовать утилиту pg_upgrade. Утилита pg_upgrade позволяет обновлять базу данных без создания резервных копий и восстановления этих копий утилитами pg_dump или pg_dumpall. pg_upgrade в процессе обновления переносит данные со старого кластера в новый путем обычного копирования данных. pg_upgrade перед обновлениями проверяет, чтобы старый и новый кластер были совместимы с бинарными файлами, утилита проверяет совместимые настройки времени компиляции, включая 32/64-битные бинарные файлы. Использования pg_upgrade дает нам большой плюс в том что обновления происходит очень быстро. Мы обновляли базу данных размером в 3 терабайта, и обновления заняло у нас примерно 10 минут.
Синтаксис утилиты:
pg_upgrade -b old_pghome_bin -B new_pghome_bin -d old_pgdata -D new_pgdata [—options]
1. Предварительные требования.
Чтобы вам было понятно о чем идет речь в данной статье я вам очень рекомендую посмотреть статью о том как мы проводить установку СУБД PostgresSQL на Centos 8.
2. Расположения директорий.
Каждая из СУБД у нас будет храниться в отдельных директориях.
Версия СУБД 13 будет храниться в директории /app/postgresql/13 и хранить в себе еще три директории. Первая директория называется log, она отвечает за то, чтобы хранить в себе все журналы событий связанные с базой данных. Вторая директория называется pgdata, она отвечает за то, чтобы хранить в себе все файлы кластера базы данных. Третья директория называется pghome, она хранит в себе все утилиты по управлению базой данных, все возможные расширения и различные библиотеки.
/app/postgresql/13
/app/postgresql/13/log
/app/postgresql/13/pgdata
/app/postgresql/13/pghome

Версия СУБД версии 14 будет храниться в директории /app/postgresql/14 и хранить в себе те же три директории с одинаковыми именами.
/app/postgresql/14
/app/postgresql/14/log
/app/postgresql/14/pgdata
/app/postgresql/14/pghome

3. Файлы переменных окружений.
В домашней директории учетной записи postgres у нас должно быть создано два файла переменных окружений. Под каждую базу данных у нас будет отдельный файл с конкретными переменными которые нужны для нормальной работы самой базы данных. Называться файлы будут pgsql_13.env и pgsql_14.env. Файл pgsql_13.env будет относиться в базе данных версии 13, а файл pgsql_14.env будет относиться к версии базы данных 14. Содержимое каждого из файлов будет показано ниже.

Файл pgsql_13.env
export PGUSER=postgres
export PGPORT=5432
export PGPASSWORD=’Qwerty123!’
export PGHOME=/app/postgresql/13/pghome
export LD_LIBRARY_PATH=/app/postgresql/13/pghome/lib
export PGDATA=/app/postgresql/13/pgdata
export PATH=$PGHOME/bin:$PGDATA:$PATH
Файл pgsql_14.env
export PGUSER=postgres
export PGPORT=5432
export PGPASSWORD=’Qwerty123!’
export PGHOME=/app/postgresql/14/pghome
export LD_LIBRARY_PATH=/app/postgresql/14/pghome/lib
export PGDATA=/app/postgresql/14/pgdata
export PATH=$PGHOME/bin:$PGDATA:$PATH
Обозначения переменных:
- PGUSER — Основная учетная запись из под которой происходим авторизация в базе дынных.
- PGPORT — Порт на котором запущена база данных.
- PGPASSWORD — Пароль от учетной записи из под которой происходим авторизация в базе дынных.
- PGHOME — Путь до директории в которой хранятся все утилиты которые управляют базой данных.
- LD_LIBRARY_PATH — Путь до библиотек которые использует база данных.
- PGDATA — Путь до директории где хранятся все файлы кластера базы данных.
- PATH — Переопределяем основную переменную в Linux путем добавления переменных связанных с СУБД PostgreSQL.
4. Сборка и инициализация нового кластера.
Перед тем как использовать утилиту pg_upgrade нам нужно собрать и проинициализировать новый кластер базы данных уже 14 версии, потому что утилита pg_upgrade перед обновлениями будет подключиться на старый и в то же время на новый кластер и проверять их на совместимость. Если pg_upgrade найдет хоть одну не совместимость, то обновить кластер не получится.
Показывать в этой статье как собирать новый кластер я не буду, потому что вы можете посмотреть это в моей прошлой статье как Скачать и установить Postgresql 14 на Linux CentOS/RHEL 8/7 TAR .
После того как вы собрали и проинициализировали новый кластер, то следующим шагом вам необходимо скопировать два конфигурационных файла из старого кластера и перенести из в новый кластер. Конфигурационные файлы называются pg_hba.conf и postgresql.conf, копировать их нужно потому что утилита pg_upgrade будет переносить только сами данные, а конфигурационные файлы не будет переносить.
Обозначения конфигурационных файлов.
- pg_hba.conf — Отвечает за авторизацию в базу данных.
- postgresql.conf — Основной конфигурационный файл который отвечает за всю базу данных.
5. Проверка совместимости.
Ну на конец-то мы потихоньку подходим к тому, чтобы использовать утилиту pg_upgrade. Самое важное что нам нужно знать так это то что утилиту нужно запускать из нового кластера, а не со старого. В данному случаи мы будем запускать утилиту с директории где у нас развернут кластер базы данных 14 версии.
Перед началом запуска обновления нам нужно обязательно проверить совместимость двоих кластеров. Проверять на совместимость можно даже в том случае когда у нас запущен старый кластер базы данных.
Для того чтобы проверить совместимость двоих кластеров, нам нужно запустить утилиту pg_upgrade с параметрами:
$. /app/postgresql/14/pghome/bin/pg_upgrade -b /app/postgresql/13/pghome/bin -B /app/postgresql/14/pghome/bin -d /app/postgresql/13/pgdata -D /app/postgresql/14/pgdata —check
- -b — Путь до директории с исполняемыми файлами старой версии PostgreSQL.
- -B — Путь до директории с исполняемыми файлами новой версии PostgreSQL.
- -d — Путь до директории где хранятся все файлы старого кластера базы данных.
- -D — Путь до директории где хранятся все файлы нового кластера базы данных.
- —check — проверить кластеры на совместимость между собой, изменять никакие данные не будет.
В результате проверки вы должны получить такой ответ:
Checking cluster versions ok
Checking database user is the install user ok
Checking database connection settings ok
Checking for prepared transactions ok
Checking for system-defined composite types in user tables ok
Checking for reg* data types in user tables ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for user-defined encoding conversions ok
Checking for user-defined postfix operators ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
*Clusters are compatible*
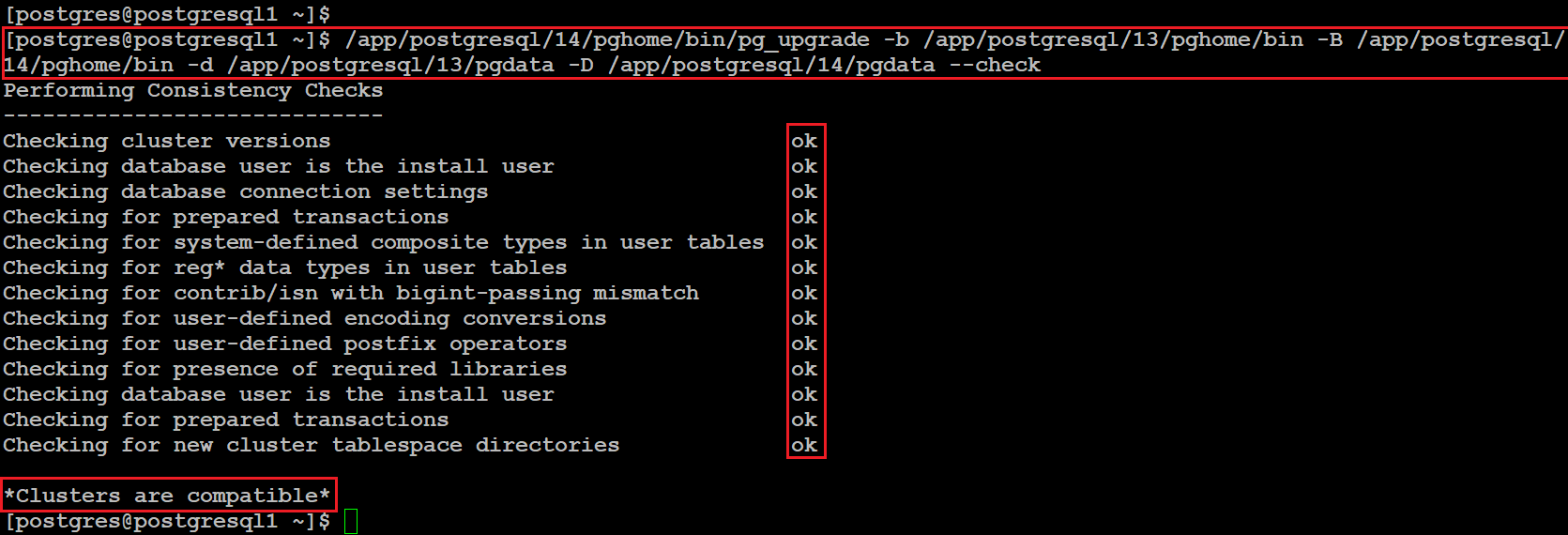
Если у вас в результате будет хоть одна ошибка, то обновить кластер не получится, пока вы эту ошибку не исправите.
6. Останавливаем старый кластер.
Перед запуском обновления обязательно нужно чтобы старый и новый кластер базы данных были остановлены. Для того чтобы остановить базу данных, необходимо использовать команду:
7. Обновляем кластер простым методом.
Теперь мы приступаем к самому обновлению кластера базы данных. В этом примере мы будем использовать метод обновления который просто копирует данные со старого кластера в новый, этот метод является методом по умолчанию. Плюс такого подхода заключается в том что он позволяет сохранить рабочее состояние старого кластера при запуске нового. К примеру мы обновили кластер и запустили его, но все таки что-то пошло не так, и мы можем новый кластер остановить и заново запустить старый кластер.
Для запуска обычного обновления выполните команду:
$. /app/postgresql/14/pghome/bin/pg_upgrade -b /app/postgresql/13/pghome/bin -B /app/postgresql/14/pghome/bin -d /app/postgresql/13/pgdata -D /app/postgresql/14/pgdata
В результате обновления вы должны получить такой ответ:
Performing Consistency Checks
——————————
Checking cluster versions ok
Checking database user is the install user ok
Checking database connection settings ok
Checking for prepared transactions ok
Checking for system-defined composite types in user tables ok
Checking for reg* data types in user tables ok
Checking for contrib/isn with bigint-passing mismatch ok
Checking for user-defined encoding conversions ok
Checking for user-defined postfix operators ok
Creating dump of global objects ok
Creating dump of database schemas
ok
Checking for presence of required libraries ok
Checking database user is the install user ok
Checking for prepared transactions ok
Checking for new cluster tablespace directories ok
If pg_upgrade fails after this point, you must re-initdb the
new cluster before continuing.
Performing Upgrade
——————
Analyzing all rows in the new cluster ok
Freezing all rows in the new cluster ok
Deleting files from new pg_xact ok
Copying old pg_xact to new server ok
Setting oldest XID for new cluster ok
Setting next transaction ID and epoch for new cluster ok
Deleting files from new pg_multixact/offsets ok
Copying old pg_multixact/offsets to new server ok
Deleting files from new pg_multixact/members ok
Copying old pg_multixact/members to new server ok
Setting next multixact ID and offset for new cluster ok
Resetting WAL archives ok
Setting frozenxid and minmxid counters in new cluster ok
Restoring global objects in the new cluster ok
Restoring database schemas in the new cluster
ok
Copying user relation files
ok
Setting next OID for new cluster ok
Sync data directory to disk ok
Creating script to delete old cluster ok
Checking for extension updates ok
Upgrade Complete
—————-
Optimizer statistics are not transferred by pg_upgrade.
Once you start the new server, consider running:
/app/postgresql/14/pghome/bin/vacuumdb —all —analyze-in-stages
Running this script will delete the old cluster’s data files:
./delete_old_cluster.sh
После выполнения обновления, у вас в той директории откуда вы запускали команду обновления кластера появится файл, под названием delete_old_cluster.sh. В этом файле будет указана всего одна команду, которая удалит вам старый кластер. Вы можете либо сами удалить старый кластер или выполнить этот файл, но если хотите то старый кластер можете не удалять, а удалить его чуть позже если захотите.
8. Запуск нового кластера.
После того как вы успешно обновили кластер базы данных, то теперь мы можем его запустить. Для того чтобы запустить кластер, мы можем воспользоваться командой:

Как видим в результате кластер у нам успешно запустился и версия нашего кластера теперь 14.0 вместо 13.0
9. Итоги.
Коллеги в итоге мы сегодня успешно рассмотрели как можно простым способом обновить наш кластер базы данных. Конечно помимо простого обновления можно еще использовать такие методы как обновления с использованием жестких ссылок и методом клонирования, но у этих способов есть один не достаток. Не достатков заключается в том что после обновления старый кластер базы данных приходит в негодность, и чтобы его обратно запустить то нужно вносить изменения в файлы данных старого кластера.
Всем спасибо, я надеюсь что вам моя статья хоть чем-то помогла.
Какой командой можно выполнить обновление конфигурации postgresql
pg_upgrade — обновить экземпляр сервера PostgreSQL
Синтаксис
pg_upgrade -b старый_каталог_bin [ -B новый_каталог_bin ] -d старый_каталог_конфигурации -D новый_каталог_конфигурации [ параметр . ]
Описание
Программа pg_upgrade (ранее называвшаяся pg_migrator ) позволяет обновить данные в каталоге базы данных PostgreSQL до последней основной версии PostgreSQL без операции выгрузки/восстановления данных, обычно необходимой при обновлениях основной версии, например, при переходе от 9.5.8 к 9.6.4 или от 10.7 к 11.2. Эти действия не требуются при установке корректирующей версии, например, при переходе от 9.6.2 к 9.6.3 или от 10.1 к 10.2.
С выходом новых основных версий в PostgreSQL регулярно добавляются новые возможности, которые часто меняют структуру системных таблицы, но внутренний формат хранения меняется редко. Учитывая этот факт, pg_upgrade позволяет выполнить быстрое обновление, создавая системные таблицы заново, но сохраняя старые файлы данных. Если при обновлении основной версии формат хранения данных изменится так, что данные в старом формате окажутся нечитаемыми, pg_upgrade не сможет произвести такое обновление. (Сообщество разработчиков постарается не допустить подобных ситуаций.)
Программа pg_upgrade делает всё возможное, чтобы убедиться в том, что старый и новый кластеры двоично-совместимы, в частности проверяя параметры времени компиляции и разрядность (32/64 бита) исполняемых файлов. Важно, чтобы и все внешние модули тоже были двоично-совместимыми, хотя это pg_upgrade проверить не может.
pg_upgrade поддерживает обновление с версии 8.4.X и новее до текущей основной версии PostgreSQL , включая бета-выпуски и сборки снимков кода.
Параметры
pg_upgrade принимает следующие аргументы командной строки:
-b каталог_bin
—old-bindir= каталог_bin
каталог с исполняемыми файлами старой версии PostgreSQL; переменная окружения PGBINOLD -B каталог_bin
—new-bindir= каталог_bin
каталог с исполняемыми файлами новой версии PostgreSQL, по умолчанию это каталог, в котором располагается pg_upgrade ; переменная окружения PGBINNEW -c
—check
только проверить кластеры, не изменять никакие данные -d каталог_конфигурации
—old-datadir= каталог_конфигурации
каталог конфигурации старого кластера; переменная окружения PGDATAOLD -D каталог_конфигурации
—new-datadir= каталог_конфигурации
каталог конфигурации нового кластера; переменная окружения PGDATANEW -j число_заданий
—jobs= число_заданий
число одновременно задействуемых процессов или потоков -k
—link
использовать жёсткие ссылки вместо копирования файлов в новый кластер -o параметры
—old-options параметры
параметры, передаваемые непосредственно старой программе postgres ; несколько параметров складываются вместе -O параметры
—new-options параметры
параметры, передаваемые непосредственно новой программе postgres ; несколько параметров складываются вместе -p порт
—old-port= порт
номер порта старого кластера; переменная окружения PGPORTOLD -P порт
—new-port= порт
номер порта нового кластера; переменная окружения PGPORTNEW -r
—retain
сохранить SQL и журналы сообщений даже при успешном завершении -s каталог
—socketdir= каталог
каталог, в котором будет создавать сокеты процесс postmaster во время обновления; по умолчанию выбирается текущий рабочий каталог; переменная окружения PGSOCKETDIR -U имя_пользователя
—username= имя_пользователя
имя пользователя, установившего кластер; переменная окружения PGUSER -v
—verbose
включить подробные внутренние сообщения -V
—version
показать версию, а затем завершиться —clone
Использовать эффективное клонирование файлов (в ряде систем это называется « reflink » ) вместо копирования файлов в новый кластер. В результате файлы данных могут копироваться практически мгновенно, как и с использованием -k / —link , но последующие изменения не будут затрагивать старый кластер.
Клонирование файлов поддерживается не во всех операционных системах и только с определёнными файловыми системами. Если этот режим выбран, но клонирование не поддерживается, при выполнении pg_upgrade произойдёт ошибка. В настоящее время оно поддерживается в Linux (с ядром 4.5 или новее) с Btrfs и XFS (если файловая система была создана с поддержкой reflink), а также в macOS с APFS. -?
—help
показать справку, а затем завершиться
Использование
Далее описан план обновления с использованием pg_upgrade :
Переместить старый кластер (необязательно)
Если ваш каталог инсталляции привязан к версии, например, /opt/PostgreSQL/14 , перемещать его не требуется. Все графические инсталляторы выбирают при установке каталоги, привязанные к версии.
Если ваш каталог инсталляции не привязан к версии, например /usr/local/pgsql , необходимо переместить каталог текущей инсталляции PostgreSQL, чтобы он не конфликтовал с новой инсталляцией PostgreSQL . Когда текущий сервер PostgreSQL отключён, каталог этой инсталляции PostgreSQL можно безопасно переместить; если старый каталог /usr/local/pgsql , его можно переименовать, выполнив:
mv /usr/local/pgsql /usr/local/pgsql.old
Собрать новую версию при установке из исходного кода
Соберите из исходного кода новую версию PostgreSQL с флагами configure , совместимыми с флагами старого кластера. Программа pg_upgrade проверит результаты pg_controldata , чтобы убедиться, что все параметры совместимы, прежде чем начинать обновление.
Установить новые исполняемые файлы PostgreSQL
Установите новые исполняемые файлы сервера и вспомогательные файлы. Программа pg_upgrade включена в инсталляцию по умолчанию.
При установке из исходного кода, если вы хотите разместить сервер в нестандартном каталоге, воспользуйтесь переменной prefix :
make prefix=/usr/local/pgsql.new install
Инициализировать новый кластер PostgreSQL
Инициализируйте новый кластер, используя initdb . При этом так же необходимо указать флаги initdb , совместимые с флагами в старом кластере. Многие готовые инсталляторы выполняют это действие автоматически. Запускать новый кластер не требуется.
Установить разделяемые объектные файлы расширения
Многие расширения и пользовательские модули, как из contrib , так и из других источников, используют разделяемые объектные файлы (или библиотеки DLL), например, pgcrypto.so . Если они использовались в старом кластере, разделяемые объектные файлы, соответствующие новому исполняемому файлу сервера, должны быть установлены в новом кластере, обычно средствами операционной системы. Не загружайте определения схемы, например, выполняя CREATE EXTENSION pgcrypto , потому что они будут скопированы из старого кластера. Если доступны обновления расширений, pg_upgrade сообщит об этом и создаст скрипт, который можно будет запустить позже, чтобы обновить эти расширения.
Скопируйте пользовательские файлы полнотекстового поиска
Скопировать пользовательские файлы полнотекстового поиска (словари, тезаурусы, списки синонимов и стоп-слов) из старого кластера в новый.
Настроить аутентификацию
Программа pg_upgrade будет подключаться к новому и старому серверу несколько раз, так что имеет смысл установить режим аутентификации peer в pg_hba.conf или использовать файл ~/.pgpass (см. Раздел 34.16).
Остановить оба сервера
Убедитесь в том, что оба сервера баз данных остановлены. Для этого в Unix можно выполнить:
pg_ctl -D /opt/PostgreSQL/9.6 stop pg_ctl -D /opt/PostgreSQL/14 stop
А в Windows, с соответствующими именами служб:
NET STOP postgresql-9.6 NET STOP postgresql-14
Ведомые серверы с потоковой репликацией и трансляцией журнала должны продолжать работать во время этого отключения, чтобы получить все изменения.
Подготовиться к обновлению ведомых серверов
Если вы производите обновление ведомых серверов (как описано в разделе Шаг 11), удостоверьтесь, что эти серверы находятся в актуальном состоянии, запустив pg_controldata в старых ведущем и ведомых кластерах. Убедитесь в том, что « Положение последней контрольной точки » во всех кластерах одинаковое. Также смените wal_level на replica в файле postgresql.conf нового ведущего кластера.
Запустить pg_upgrade
Всегда запускайте программу pg_upgrade от нового сервера, а не от старого. pg_upgrade требует указания каталогов данных старого и нового кластера, а также каталогов исполняемых файлов ( bin ). Вы можете также определить имя пользователя и номера портов, и нужно ли копировать файлы данных (по умолчанию), клонировать их или создавать ссылки на них.
Если выбрать вариант со ссылкой на данные, обновление выполнится гораздо быстрее (так как файлы не копируются) и потребует меньше места на диске, но вы лишитесь возможности обращаться к вашему старому кластеру, запустив новый после обновления. Этот вариант также требует, чтобы каталоги данных старого и нового кластера располагались в одной файловой системе. (Табличные пространства и pg_wal могут находиться в других файловых системах.) Вариант с клонированием работает так же быстро и экономит место на диске, но позволяет сохранить рабочее состояние старого кластера при запуске нового. Для этого варианта тоже требуется, чтобы старый и новый каталоги данных находились в одной файловой системе. Клонирование возможно только в некоторых операционных системах с определёнными файловыми системами.
Параметр —jobs позволяет задействовать для копирования/связывания файлов и для выгрузки/восстановления схем баз данных несколько процессорных ядер. В качестве начального значения параметра стоит выбрать максимум из числа процессорных ядер и числа табличных пространств. Этот параметр может радикально сократить время обновления сервера со множеством баз данных, работающего в многопроцессорной системе.
В Windows вы должны войти в систему с административными полномочиями, затем запустить командную строку от имени пользователя postgres , задать подходящий путь:
RUNAS /USER:postgres "CMD.EXE" SET PATH=%PATH%;C:\Program Files\PostgreSQL\14\bin;
Наконец, запустить pg_upgrade с путями каталогов в кавычках, например, так:
pg_upgrade.exe --old-datadir "C:/Program Files/PostgreSQL/9.6/data" --new-datadir "C:/Program Files/PostgreSQL/14/data" --old-bindir "C:/Program Files/PostgreSQL/9.6/bin" --new-bindir "C:/Program Files/PostgreSQL/14/bin"
При запуске pg_upgrade проверит два кластера на совместимость и, если всё в порядке, выполнит обновление. Также возможно запустить pg_upgrade —check , чтобы ограничиться только проверками (при этом старый сервер может продолжать работать). Команда pg_upgrade —check также сообщит, какие коррективы вам нужно будет внести вручную после обновления. Если вы планируете использовать режим ссылок на данные или клонирования, укажите вместе с —check или —clone параметр —link , чтобы были проведены специальные проверки для этого режима. Программе pg_upgrade требуются права на запись в текущий каталог.
Очевидно, никто не должен обращаться к кластерам в процессе обновления. Программа pg_upgrade по умолчанию запускает серверы с портом 50432, чтобы не допустить нежелательных клиентских подключений. В процессе обновления оба кластера могут использовать один номер порта, так как они не будут работать одновременно. Однако для проверки старого работающего сервера новый порт должен отличаться от старого.
Если при восстановлении схемы базы данных происходит ошибка, pg_upgrade завершает свою работу и вы должны вернуться к старому кластеру, как описывается ниже в Шаг 17. Чтобы попробовать pg_upgrade ещё раз, вы должны внести коррективы в старом кластере, чтобы pg_upgrade могла успешно восстановить схему. Если проблема возникла в модуле contrib , может потребоваться удалить этот модуль contrib в старом кластере, а затем установить его в новом после обновления (предполагается, что этот модуль не хранит пользовательские данные).
Обновить ведомые серверы с потоковой репликацией и трансляцией журнала
Если вы используете режим ссылок и у вас реализована потоковая репликация (см. Подраздел 27.2.5) или трансляция журнала (см. Раздел 27.2) для ведомых серверов, вы можете быстро обновить эти серверы следующим образом. Вам не нужно будет запускать на них pg_upgrade , вместо этого вы выполните rsync на ведущем. Не запускайте никакие серверы на этом этапе.
Установите новые исполняемые файлы PostgreSQL на ведомых серверах
Убедитесь в том, что на всех ведомых серверах установлены новые исполняемые и вспомогательные файлы.
Убедитесь в том, что новые каталоги данных на ведомых серверах не существуют
Новые каталоги данных ведомых серверов должны отсутствовать либо быть пустыми. Если запускалась программа initdb , удалите новые каталоги данных на ведомых.
Установить разделяемые объектные файлы расширения
Установите на новых ведомых серверах те же разделяемые объектные файлы расширения, что вы установили в новом ведущем кластере.
Остановите ведомые серверы
Если ведомые серверы продолжают работу, остановите их, следуя приведённым выше инструкциям.
Сохраните файлы конфигурации
Сохраните все нужные вам файлы конфигурации из старых каталогов конфигурации ведомых серверов, в частности postgresql.conf (и все файлы, включённые в него), postgresql.auto.conf и pg_hba.conf , так как они будут перезаписаны или удалены на следующем этапе.
Запустите rsync
Когда используется режим ссылок, ведомые серверы можно быстро обновить, применив rsync . Для этого в каталоге, внутри которого находятся каталоги старого и нового кластера, для каждого ведомого сервера выполните на ведущем :
rsync --archive --delete --hard-links --size-only --no-inc-recursive old_cluster new_cluster remote_dir
Здесь каталоги old_cluster и new_cluster задаются относительно текущего каталога на ведущем, а remote_dir находится над каталогами старого и нового кластера на ведомом. Структура подкаталогов в заданных каталогах на ведущем и ведомых серверах должна быть одинаковой. Обратитесь к странице руководства rsync , где подробно описано, как указать удалённый каталог, например так:
rsync --archive --delete --hard-links --size-only --no-inc-recursive /opt/PostgreSQL/9.5 \ /opt/PostgreSQL/9.6 standby.example.com:/opt/PostgreSQL
Проверить, что будет делать команда, можно, воспользовавшись параметром rsync —dry-run . Выполнить rsync на ведущем необходимо как минимум с одним ведомым, но затем, пока обновлённый ведомый остаётся остановленным, можно запускать rsync на нём для обновления других ведомых.
В ходе этой операции записываются ссылки, созданные режимом ссылок pg_upgrade , связывающие файлы нового и старого кластера на ведущем сервере. Затем в старом кластере ведомого находятся соответствующие файлы и в новом кластере ведомого создаются ссылки на них. Файлы, не связанные ссылками на ведущем, копируются с него на ведомый. (Обычно их объём невелик.) Это позволяет произвести обновление ведомого быстро. К сожалению, при этом rsync будет напрасно копировать файлы, связанные с временными и нежурналируемыми таблицами, так как они обычно не будут существовать на ведомых серверах.
Если у вас есть табличные пространства, вам потребуется выполнить подобную команду rsync для каталогов всех табличных пространств, например:
rsync --archive --delete --hard-links --size-only --no-inc-recursive /vol1/pg_tblsp/PG_9.5_201510051 \ /vol1/pg_tblsp/PG_9.6_201608131 standby.example.com:/vol1/pg_tblsp
Если вы вынесли pg_wal за пределы каталогов данных, нужно будет запустить rsync и для этих каталогов.
Настройте ведомые серверы с потоковой репликацией и трансляцией журнала
Восстановить pg_hba.conf
Если вы изменяли pg_hba.conf , восстановите его исходное состояние. Также может потребоваться скорректировать другие файлы конфигурации в новом кластере, чтобы они соответствовали старому, например, postgresql.conf (и файлы, включённые в него) и postgresql.auto.conf .
Запустить новый сервер
Теперь можно безопасно запустить новый сервер, а затем ведомые серверы, синхронизированные с ним с помощью rsync .
Действия после обновления
Если после обновления требуются какие-то дополнительные действия, программа pg_upgrade выдаст предупреждения об этом по завершении работы. Она также сгенерирует файлы скриптов, которые должны запускаться администратором. Эти скрипты будут подключаться к каждой базе данных, требующей дополнительных операций. Каждый такой скрипт следует выполнять командой:
psql --username=postgres --file=script.sql postgres
Эти скрипты могут выполняться в любом порядке, а после выполнения их можно удалить.
Внимание
Обычно к таблицам, задействованным в перестраивающих базу скриптах, опасно обращаться, пока эти скрипты не сделают свою работу; при этом можно получить некорректный результат или плохую производительность. К таблицам, не задействованным в таких скриптах, можно обращаться немедленно.
Статистика
Так как статистика оптимизатора не передаётся в процессе работы pg_upgrade , вы получите указание запустить соответствующую команду для воссоздания этой информации после обновления. Возможно, для этого вам понадобится установить параметры подключения к новому кластеру.
Удалить старый кластер
Если вы удовлетворены результатами обновления, вы можете удалить каталоги данных старого кластера, запустив скрипт, упомянутый в выводе pg_upgrade после обновления. (Автоматическое удаление невозможно, если в старом каталоге данных находятся дополнительные табличные пространства.) Также вы можете удалить каталоги старой инсталляции (например, bin , share ).
Возврат к старому кластеру
Если выполнив команду pg_upgrade , вы захотите вернуться к старому кластеру, возможны следующие варианты:
Если использовался ключ —check , в старом кластере ничего не меняется; его можно просто перезапустить.
Если не использовался ключ —link , в старом кластере ничего не меняется; его можно просто перезапустить.
Если использовался ключ —link , у старого и нового кластера могут оказаться общие файлы данных:
Если работа pg_upgrade была прервана до начала расстановки ссылок, в старом кластере ничего не меняется; его можно просто перезапустить.
Если вы не запускали новый кластер, старый кластер не претерпел никаких изменений, за исключением того, что при создании ссылки на данные к имени $PGDATA/global/pg_control было добавлено окончание .old . Чтобы продолжить использование старого кластера, достаточно убрать окончание .old из имени файла $PGDATA/global/pg_control ; после этого старый кластер можно будет перезапустить.
Замечания
pg_upgrade создаёт в текущем рабочем каталоге различные временные файлы, например выгружая схему базы. В целях безопасности этот каталог не должен быть доступен для чтения и записи другим пользователям.
Программа pg_upgrade запускает на короткое время процессы postmaster со старым и новым каталогом данных. Временные файлы сокетов Unix для взаимодействия с этими процессами по умолчанию создаются в текущем рабочем каталоге. В некоторых ситуациях путь к файлу в текущем каталоге может оказаться слишком длинным для имени сокета. В этом случае вы можете передать параметр -s , чтобы файлы сокетов создавались в другом каталоге с более коротким путём. В целях безопасности этот каталог не должен быть доступен для чтения и записи другим пользователям. (В Windows это не поддерживается.)
Программа pg_upgrade сообщит обо всех актуальных для вашей инсталляции ошибках и потребностях перестроения или переиндексации базы; при этом будут созданы завершающие обновление скрипты, перестраивающие таблицы или индексы. Если вы попытаетесь автоматизировать обновление множества серверов, вы обнаружите, что для кластеров с одинаковыми схемами баз данных потребуются одинаковые действия после обновления; это объясняется тем, что эти действия диктуются схемой базы данных, а не данными пользователей.
Для проверки развёртывания новой версии создайте копию только схемы старого кластера, наполните этот кластер фиктивными данными, и попробуйте обновить его.
pg_upgrade не поддерживает обновление баз данных, в которых есть таблицы со столбцами, имеющими следующие системные типы данных reg* , ссылающиеся на OID:
| regcollation |
| regconfig |
| regdictionary |
| regnamespace |
| regoper |
| regoperator |
| regproc |
| regprocedure |
(Обновление regclass , regrole и regtype поддерживается.)
Если вы производите обновление кластера PostgreSQL версии до 9.2, в которой используется каталог только с файлами конфигурации, вы должны передать расположение собственно каталога с данными программе pg_upgrade , а расположение каталога конфигурации передать серверу, например -d /каталог-данных -o ‘-D /каталог-конфигурации’ .
Если вы используете старый сервер версии до 9.1, работающий с нестандартным каталогом Unix-сокетов, либо его стандартное расположение отличается от принятого в новой версии, задайте в PGHOST расположение сокета старого сервера. (К Windows это не относится.)
Если вы хотите использовать режим ссылок на данные, но при этом исключить изменения в старом кластере при запуске нового, вам может подойти режим клонирования. Если же этот режим недоступен, сделайте копию старого кластера и обновите его в этом режиме. Чтобы получить рабочую копию старого кластера, воспользуйтесь командой rsync и создайте предварительную копию кластера при работающем сервере, а затем отключите старый сервер и ещё раз запустите rsync —checksum , чтобы привести эту копию в согласованное состояние. (Ключ —checksum необходим, потому что rsync различает время с точностью только до секунд.) При этом вы можете исключить некоторые файлы, например postmaster.pid , как описано в Подразделе 26.3.3. Если ваша файловая система поддерживает снимки файловой системы или копирование при записи, вы можете воспользоваться этим для создания копии старого кластера и табличных пространств; при этом важно, чтобы такие снимки и копии файлов создавались одномоментно или когда сервер баз данных отключён.
См. также
| Пред. | Наверх | След. |
| pg_test_timing | Начало | pg_waldump |