Парсинг нетабличных данных с сайтов
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet) , вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК: 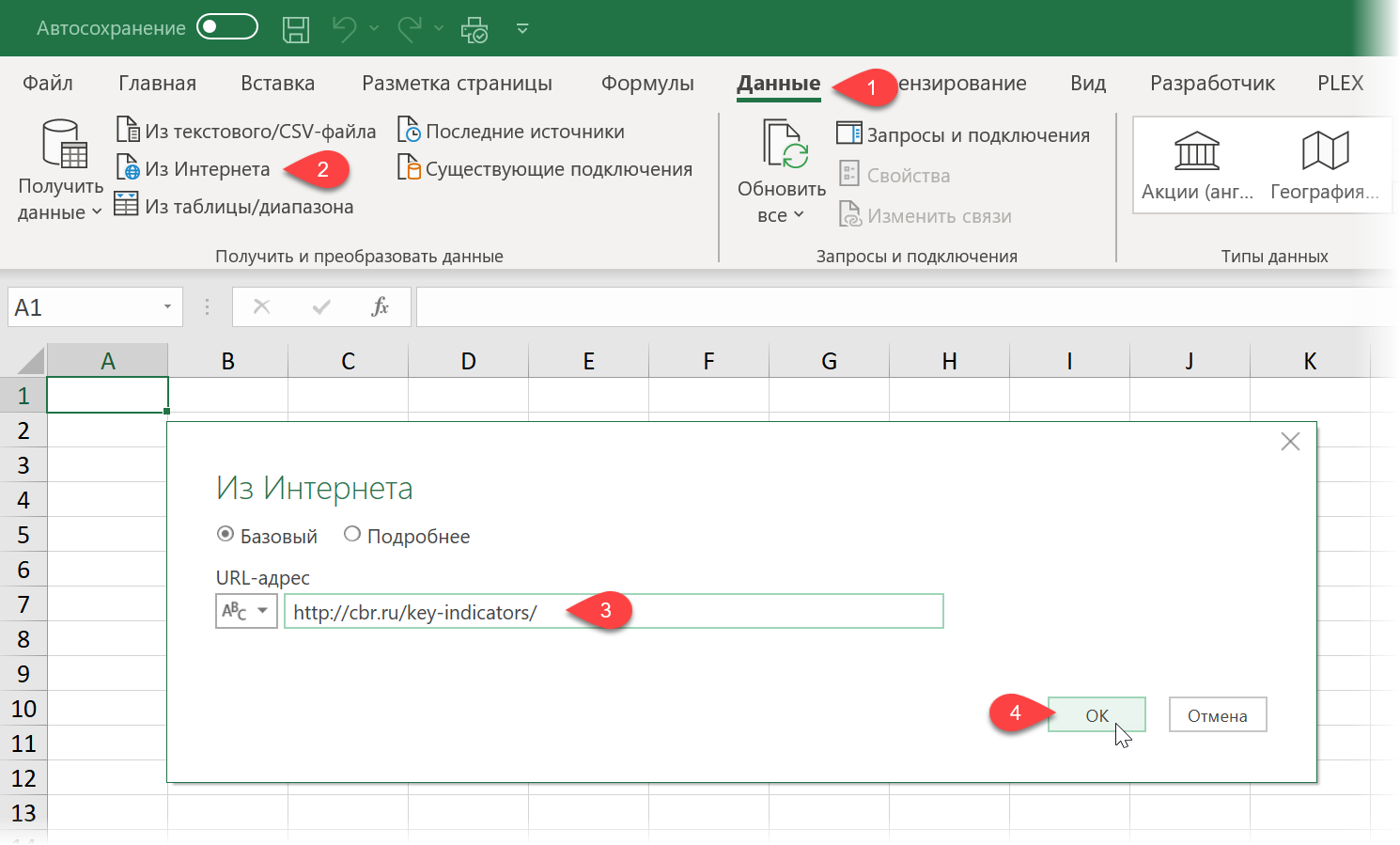
Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора: 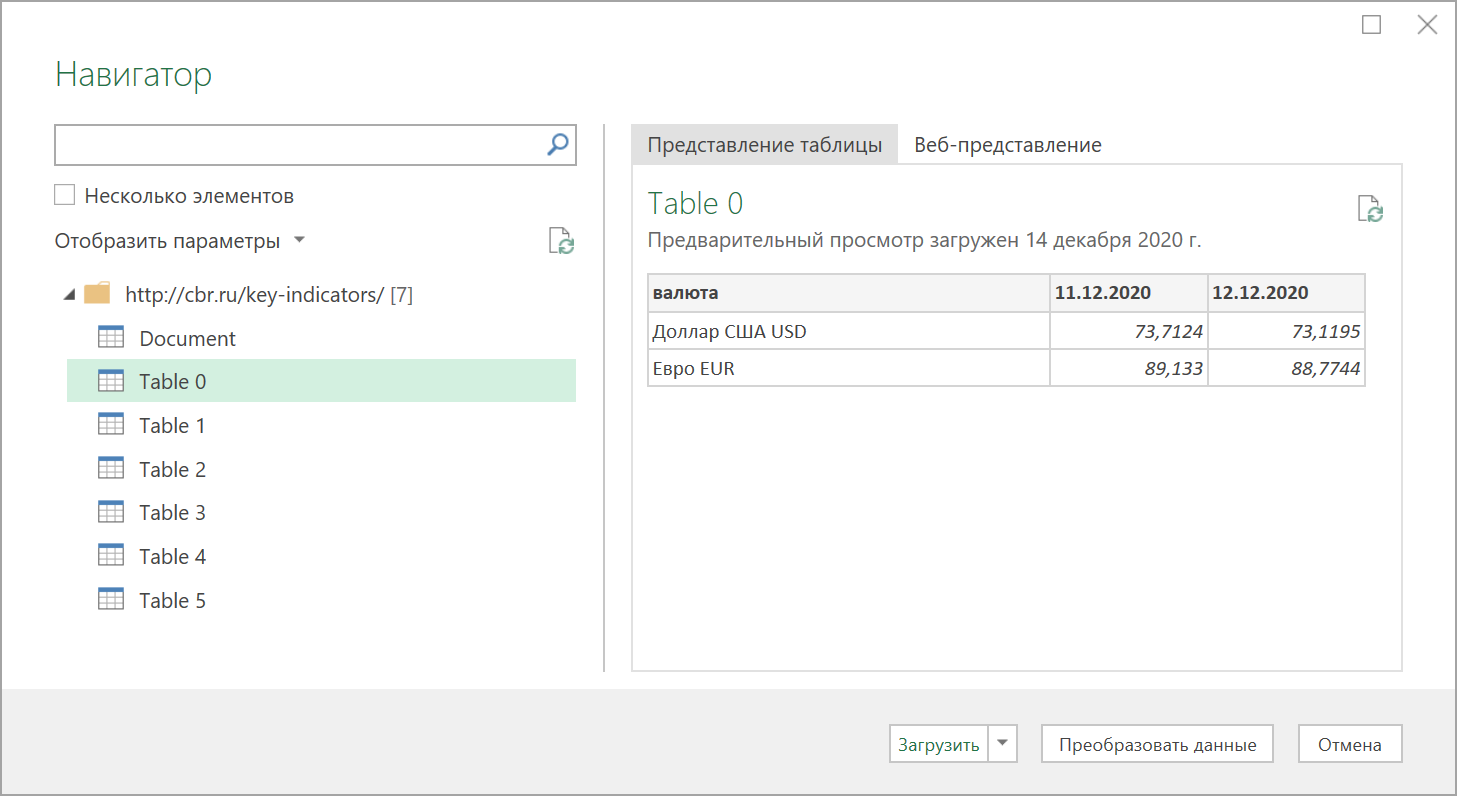
Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2. или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом , а её аналог — вложенные друг в друга теги-контейнеры . Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel. Тем не менее, есть способ обойти это ограничение 😉
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы: 
Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы: https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document: 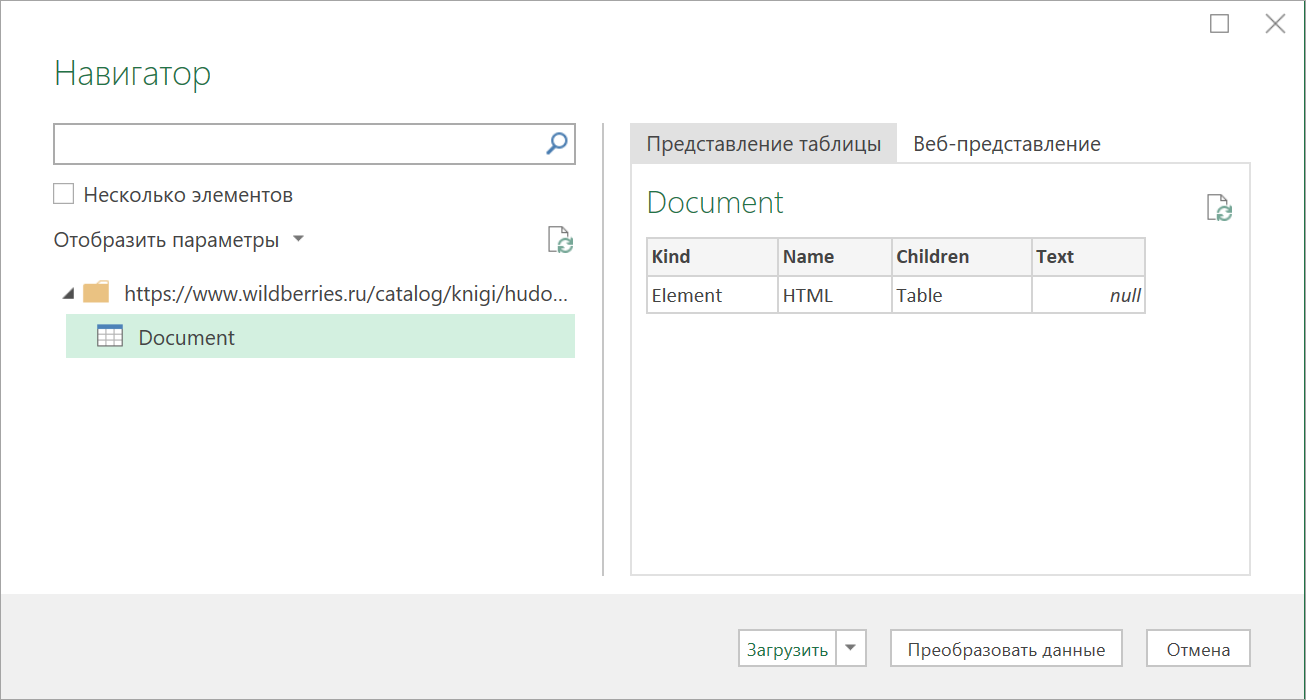
Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data) , чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом: 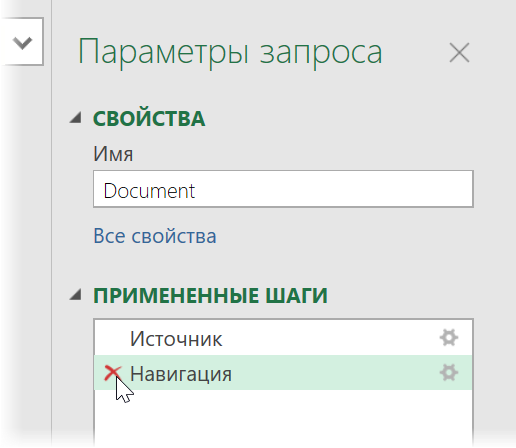
. и затем щёлкаем по значку шестерёнки справа от шага Источник (Source) , чтобы открыть его параметры: 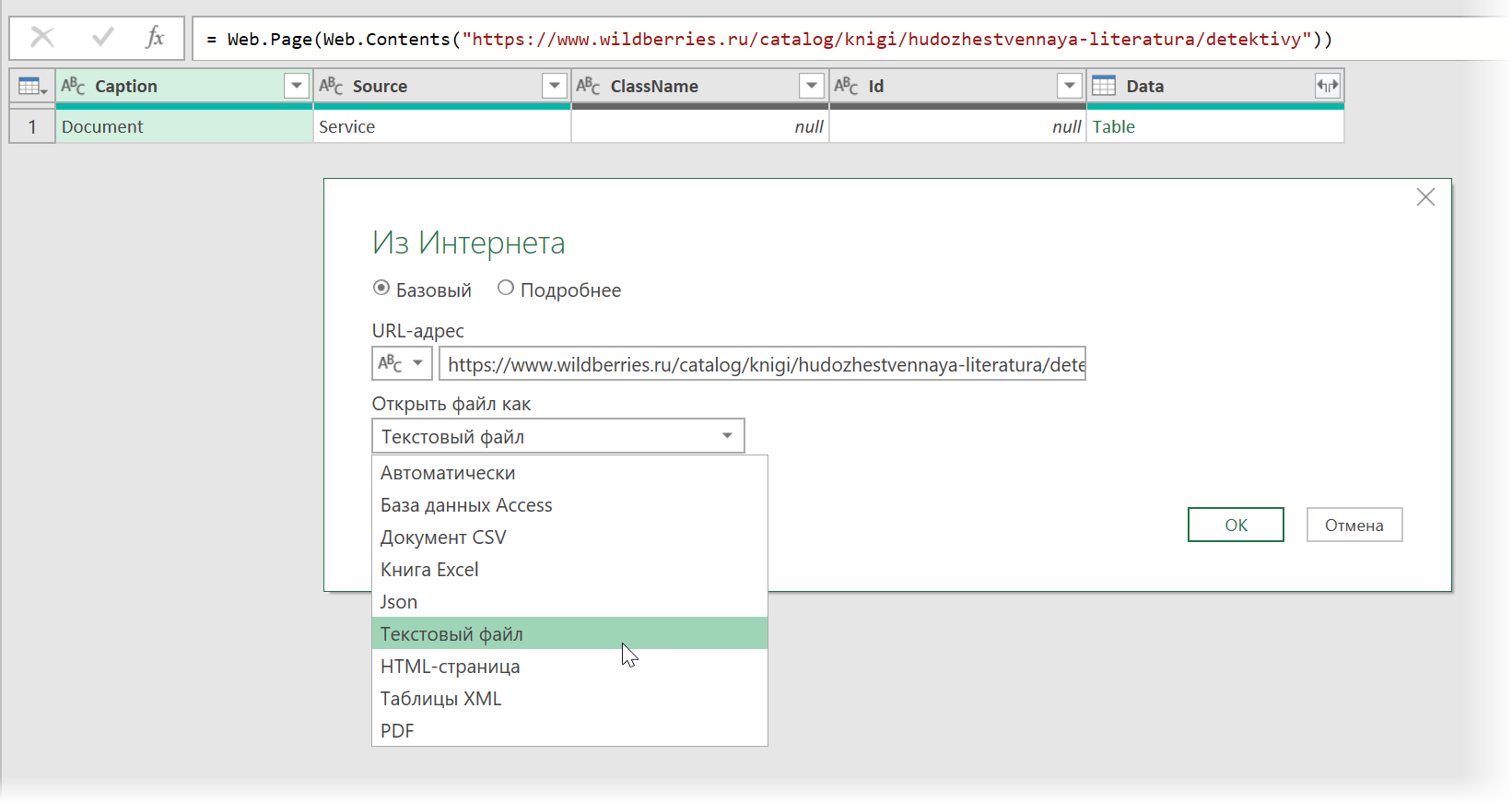
В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file) . Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь): 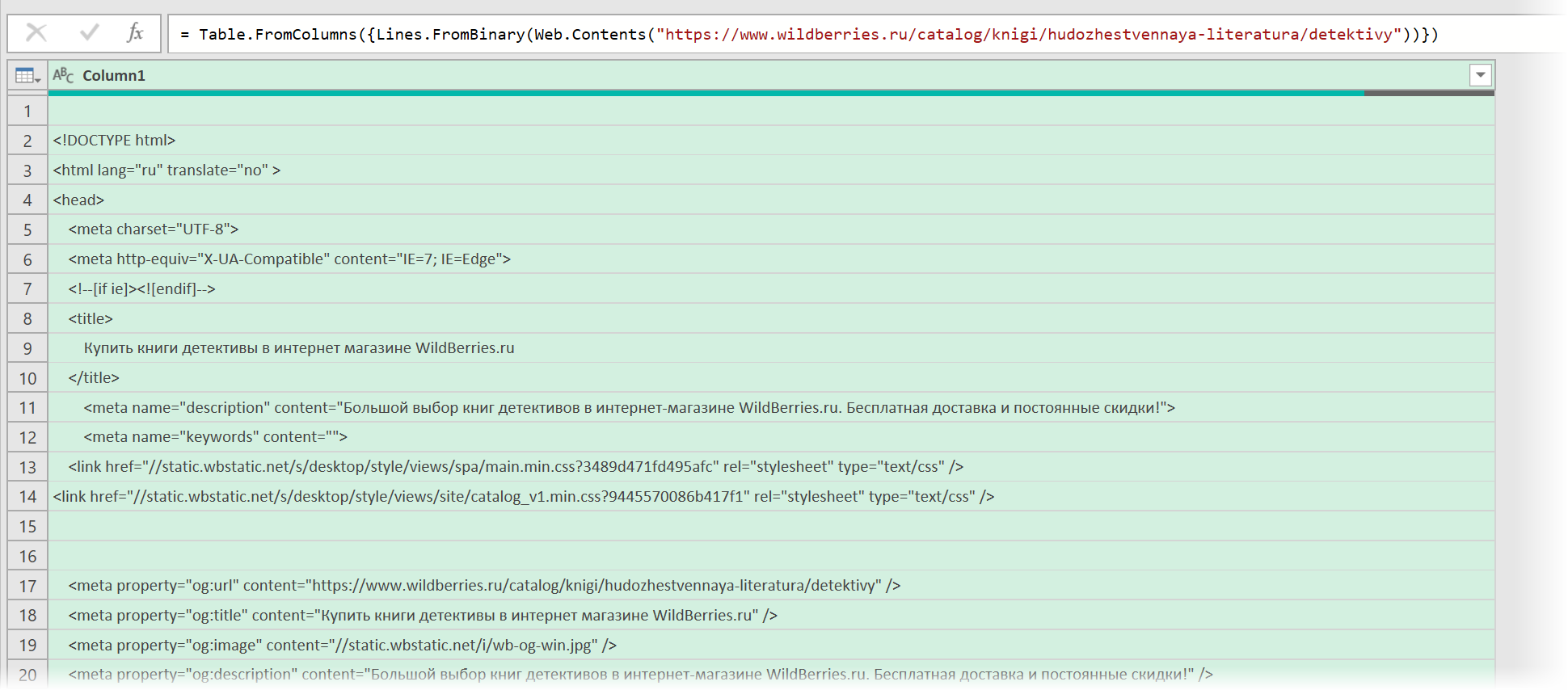
Ищем за что зацепиться
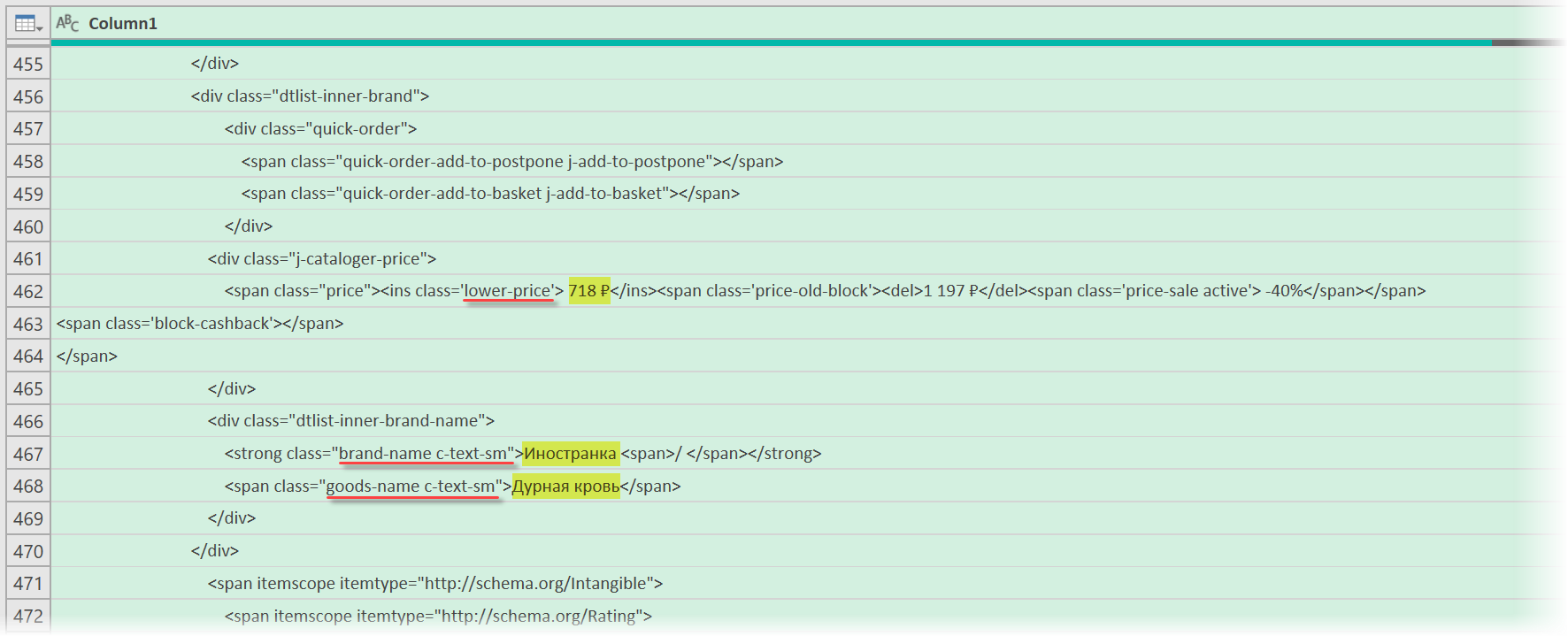
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать. В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:
- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:
Фильтруем нужные данные
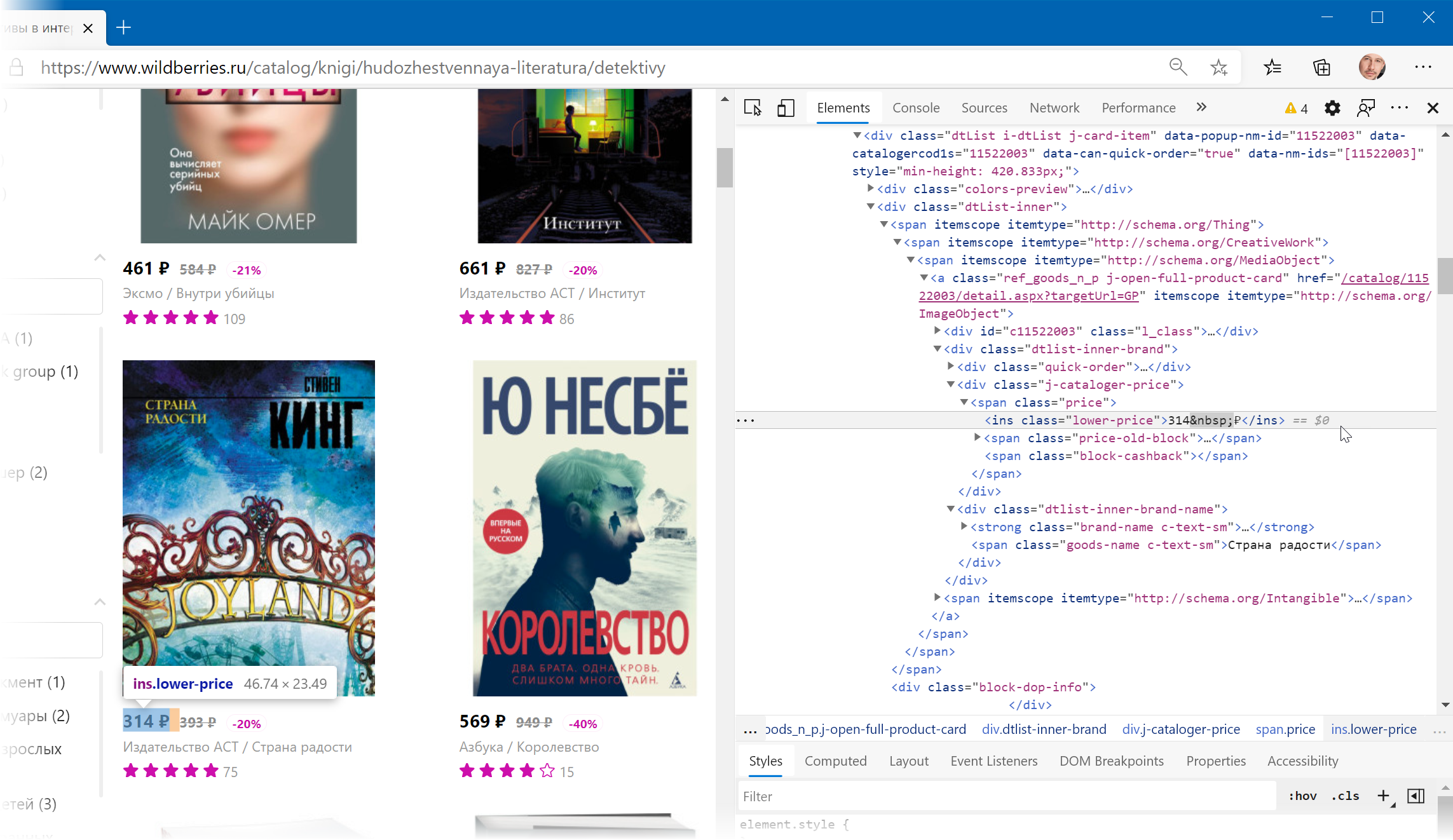
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains) , переключаемся в режим Подробнее (Advanced) [ 2] и вводим наши критерии:
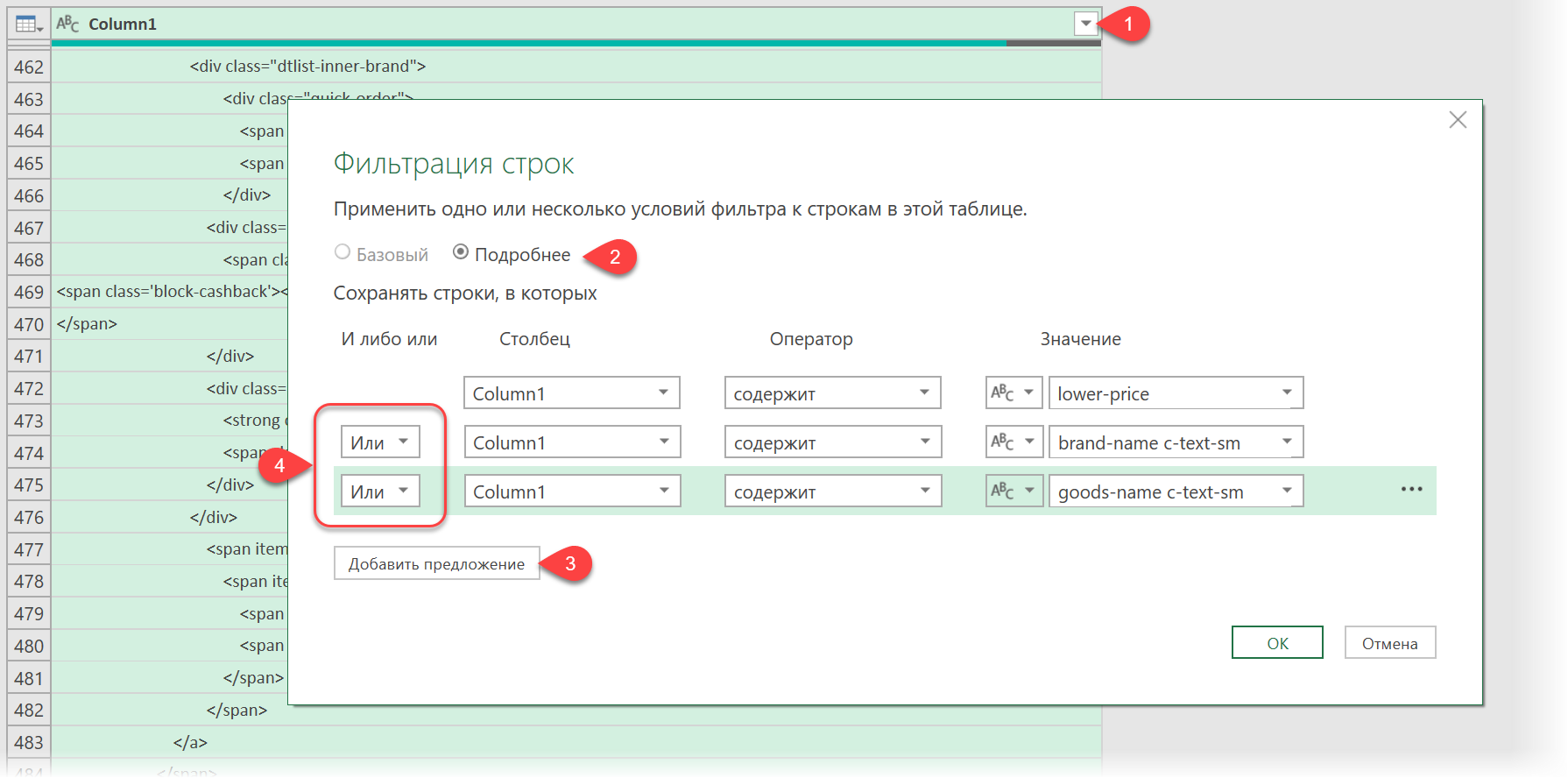
Добавление условий выполняется кнопкой со смешным названием Добавить предложение [ 3] . И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
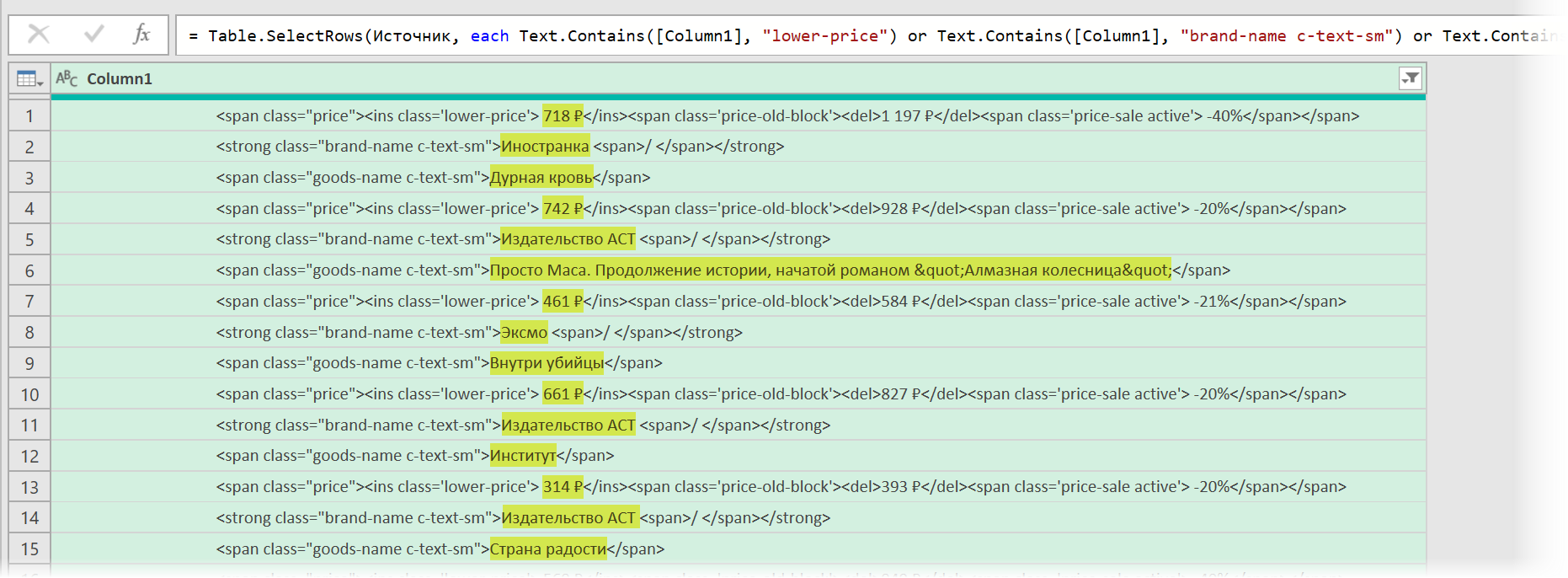
После нажатия на ОК на экране останутся только строки с нужной нам информацией:
Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: через команду Главная — Замена значений (Home — Replace values) .
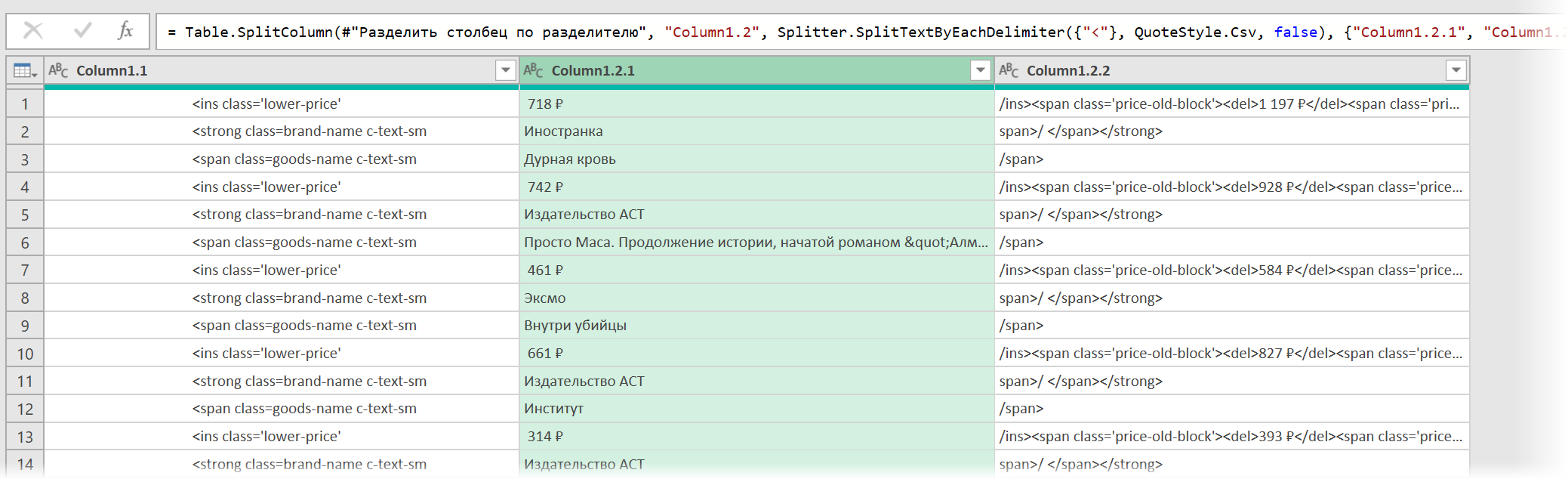
- Разделить получившийся столбец по первому разделителю » > » слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя » < " слева, чтобы отделить полезные данные от тегов:
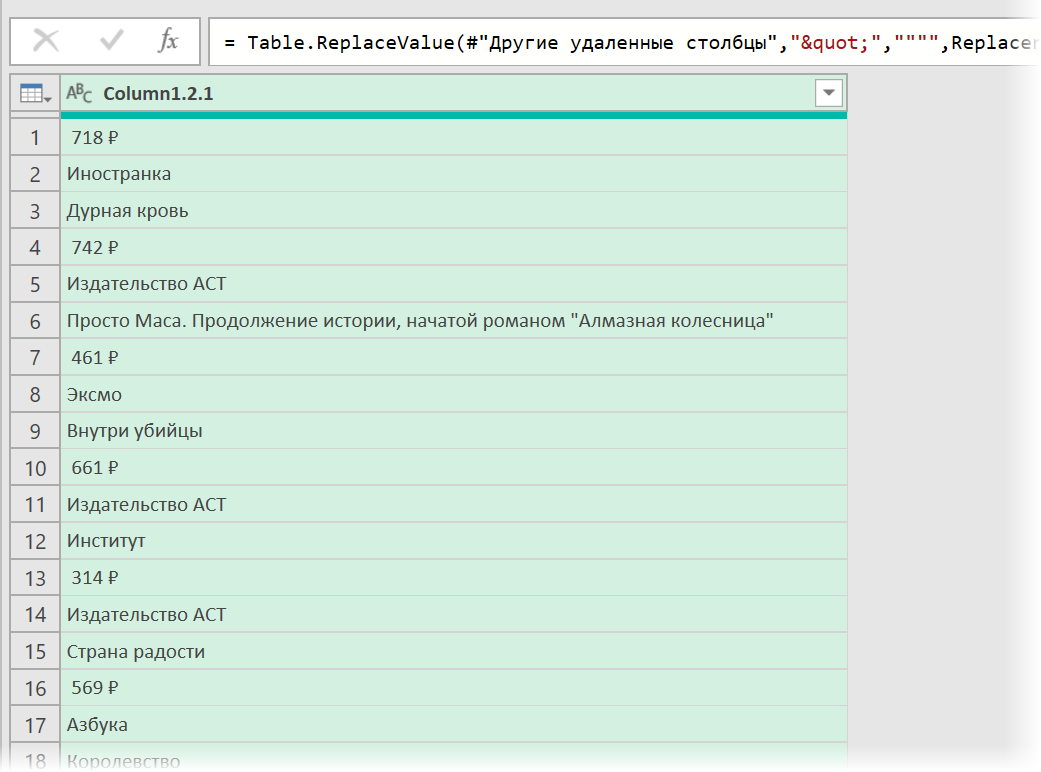
Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View) ) и вводим следующую конструкцию:
= Table.FromRows(List.Split( #»Замененное значение1″ [Column1.2.1] , 3 ))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:
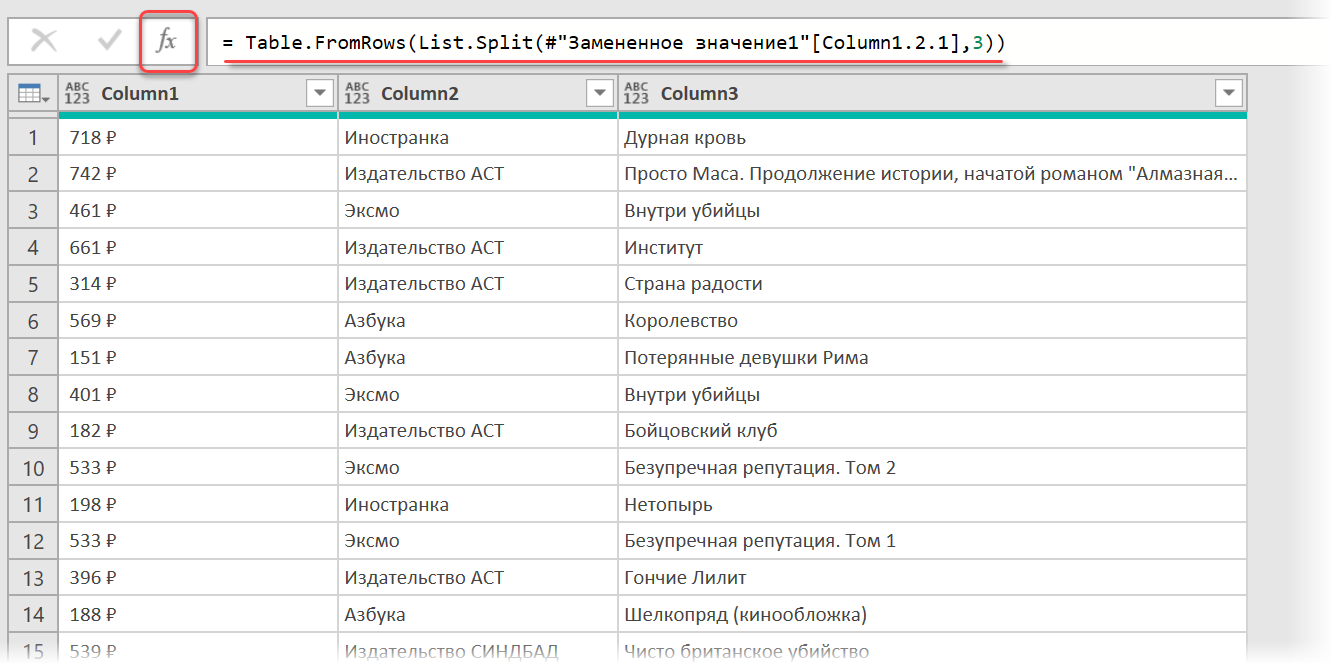
Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load. )
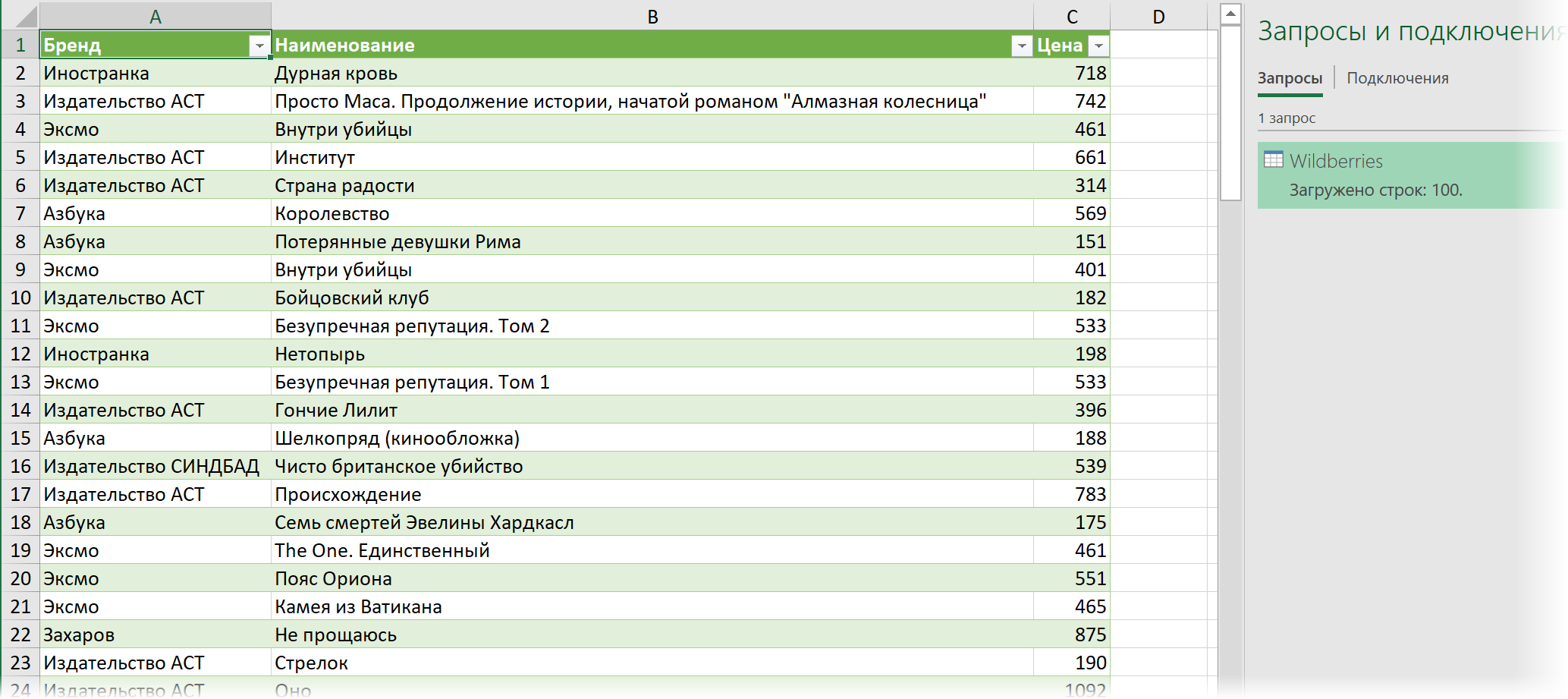
Вот и все хитрости 🙂
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
Как утащить простой сайт за 5 минут
Когда начинаешь практиковаться в вёрстке сайтов, может быть очень полезно разобраться, как устроены сайты у других ребят. Вот как это сделать.
�� Всё, что мы делаем в этой статье, мы делаем в учебных целях. Если вы просто скопируете себе чужой сайт и будете выдавать его за свой, это может плохо кончиться.
�� На самом деле всё сказанное в этой статье нужно для тех, кто боится отключения интернета и хочет сохранить у себя на компьютере самую важную информацию. Но эта мысль бредовая сразу на стольких уровнях, что мы стесняемся её произносить вслух. Разве что шёпотом.
В чём идея
Мы будем копировать чужой сайт, чтобы его можно было запустить на своём сервере или на домашнем компьютере. Задача — не просто открыть сайт в браузере и посмотреть его код, а забрать из него все важные файлы — и стили, и скрипты, и изображения. Чтобы было проще, мы будем практиковаться на одностраничном сайте, но всё то же самое будет работать и на многостраничном.
❌ Мы не сможем утащить чужие PHP-скрипты и страницы, связанные с данными пользователя (например, не сможем утащить из интернет-магазина рабочую версию корзины с покупками). Для этого нужен доступ к файлам сервера, а этого у нас нет.
Главный принцип этой работы: когда ваш браузер запрашивает страницу чужого сайта, веб-сервер отправляет ему эту страницу, в буквальном смысле. То же с картинками, стилями и скриптами: каждый раз, когда вы посещаете сайт, вы как будто делаете его копию у себя на компьютере. Браузер получает страницу от сервера и выводит её копию на экран, а в памяти держит исходный код. Разве что он не сохраняет эту страницу на диск, чтобы вы могли её редактировать.
Вот этот последний этап мы и исправим: теперь мы будем сохранять чужие сайты к себе на диск.
Весь процесс покажем на примере сайта ux-posters.ru – простом одностраничном сайте, где есть картинки, стили и скрипты. Автору этого текста пришлось помогать авторам этого сайта с похожей задачей, так что пример свеженький.
Быстрый путь: грабберы
Есть категория программ под названием «веб-грабберы», или «веб-рипперы». Они работают так:
- Ты говоришь программе, на какую страницу сайта зайти.
- Программа собирает все ссылки с этой страницы, переходит по этим ссылкам и строит себе виртуальную карту сайта — то есть пытается понять, сколько на этом сайте страниц и как они связаны.
- Потом граббер начинает ползать по этим страницам подряд, запрашивать их у сервера, получать ответы и сохранять ответы на вашем жёстком диске.
- В какой-то момент граббер останавливается, потому что он скачал все доступные ему страницы с этого сайта.
После работы граббер оставляет у вас на диске гору файлов, которые представляют собой статичный отпечаток чужого сайта. Эту гору можно загрузить на собственный сервер, и издалека это будет похоже на чужой сайт.
✅ Плюсы: граббер может быстро охватить много страниц и скачать из них огромное количество стилей, картинок и всего подряд. Работа очень быстрая и хорошо автоматизирована.
❌ Минусы: часто он качает всё без разбора, оставляя на диске много дублей. Также он бессилен с сайтами, в которых контент выводится динамически или имеет нестандартную систему адресации.
�� В целом грабберы можно использовать, чтобы скачивать сайты библиотек, архивов и других мест, где документов много и всё устроено логично. Например, с помощью граббера можно скачать какую-нибудь классическую книгу из онлайн-библиотеки.
Вот ссылки на грабберы для разных платформ:
- HTTrack — старый интерфейс из нулевых, но свою задачу выполняет полностью. Бесплатный и надёжный, работает везде.
- Getleft — мультиплатформенный граббер, который пытается выкачивать всё, до чего дотянется, включая PHP-скрипты.
- Cyotek WebCopy — для тех, кто любит только Windows, тоже бесплатный.
Сложный путь: ручное сохранение
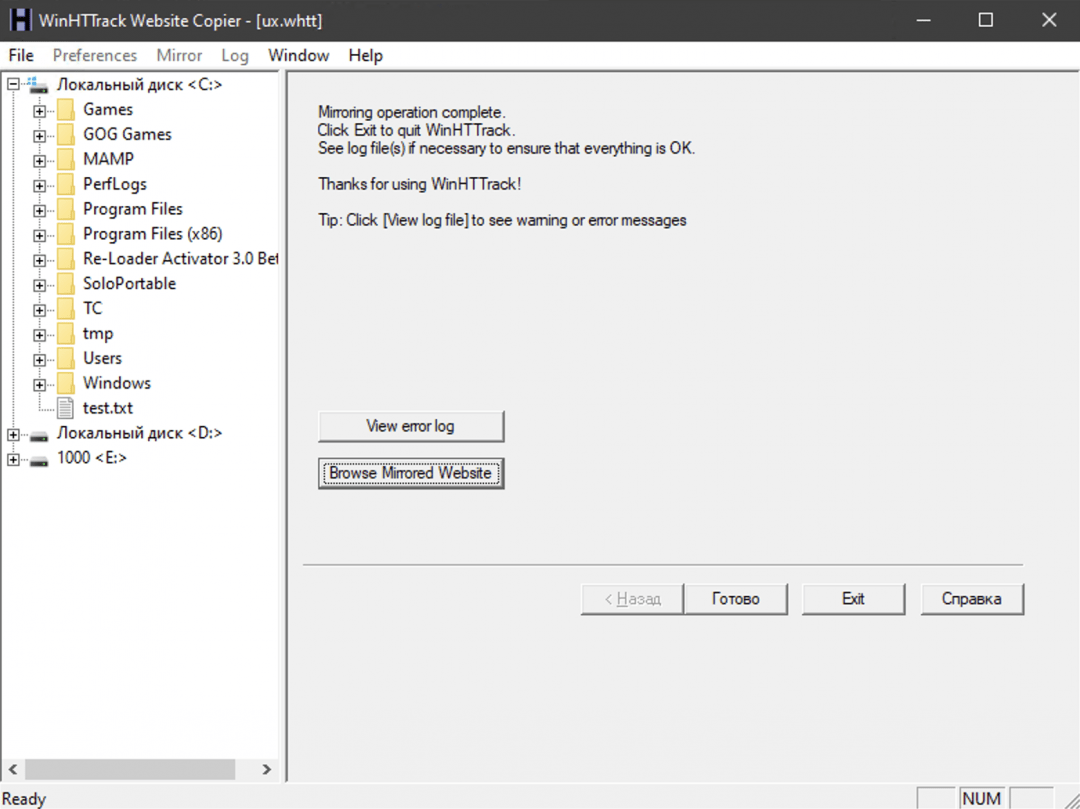
Допустим, мы хотим сохранить какую-то отдельную страницу сайта или конкретные её части (например, картинки). Но эти картинки как-то так хитро встроены, что вы не можете просто нажать «Сохранить картинку как. ». Тогда потребуется ручной метод.
Заходим на страницу и нажимаем в браузере Ctrl + I (в Виндоус) или ⌥ + ⌘ + I (если у вас мак). Появляется окно «Инспектора», где видна внутренняя структура страницы:
Мы видим, что текущий документ в браузере состоит:
- из страницы index.html;
- скрипта likely.js;
- четырёх таблиц стилей;
- шрифтов, подключённых через сервис Google;
- папки с картинками.
Шрифты нам скачивать необязательно — сайт и так их подключит с сервера гугла, а всё остальное скачать нужно. Чтобы не создавать хаос на компьютере, создадим сначала папку ux-posters — в ней будет храниться наш сайт. Потом в эту папку сохраняем все файлы таким способом:
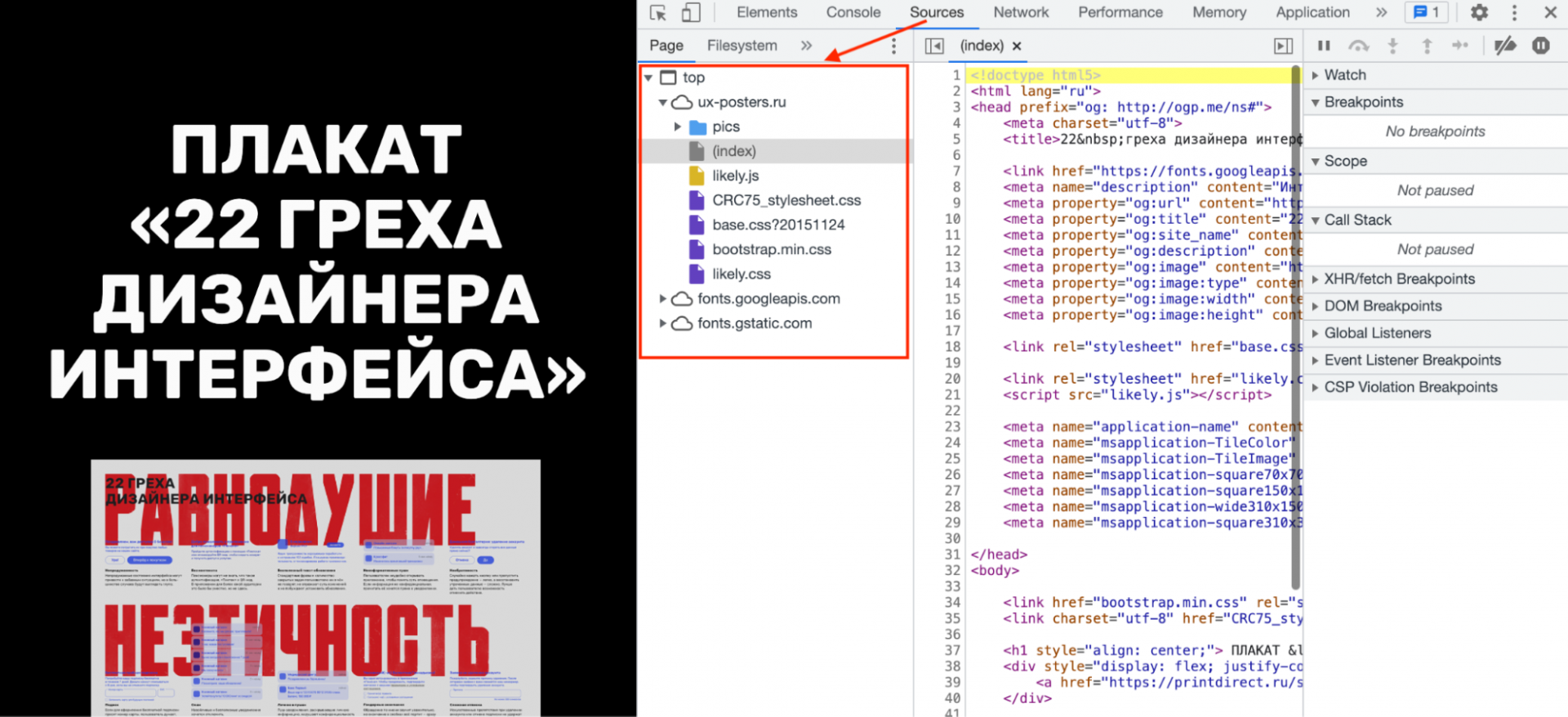
- Нажимаем правой кнопкой мыши на очередной файл.
- Выбираем пункт Save as, или «Сохранить как».
- Пишем имя и расширение файла — точно так, как указано в списке.
- Если лень писать самому — скопируйте перед этим название файла, нажав правую кнопку мыши и выбрав Copy file name, или «Скопировать имя файла».
- Чаще всего название файла подставится само, но если нет — смотрите пункт 4.
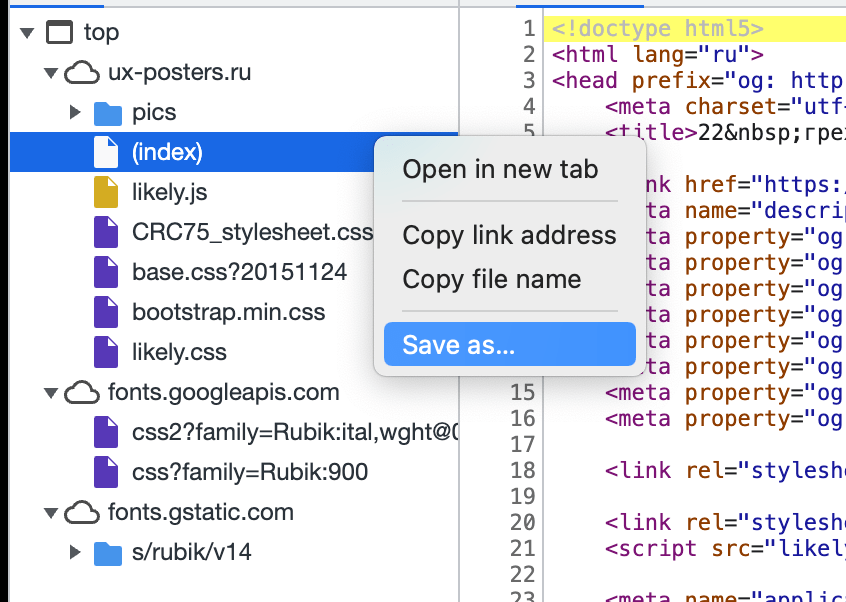
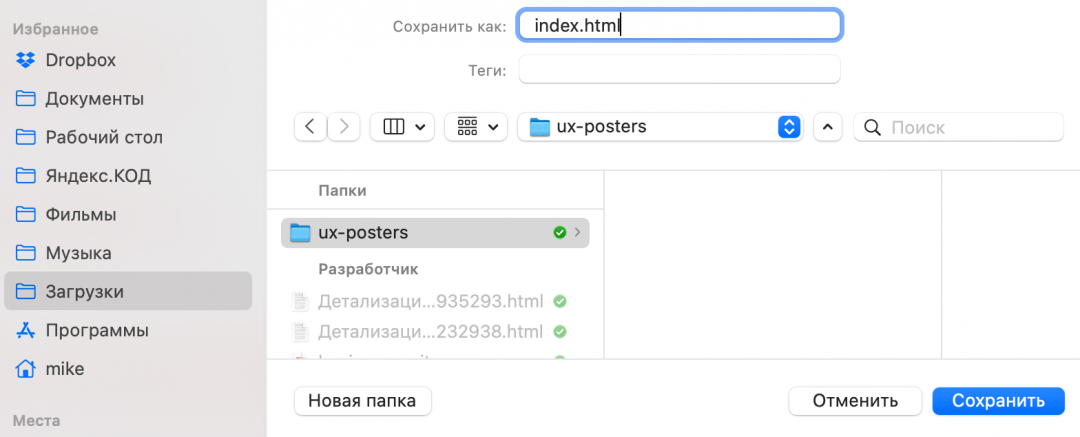
Исключения в названии файлов два:
- (index) — это index.html.
- В любом файле знак вопроса и всё, что после него, писать не нужно.
Скачать можно всё, а можно только то, что вам нужно для работы и экспериментов. Например, если вам нужны только стили и код страницы, сохраняйте файлы .css и (index). Если нужны картинки, заходите в папку pics и сохраняйте всё оттуда.
Что в итоге
Если мы пройдёмся по всем папкам и сохраним в них всё нужное нам, у нас получится локальный слепок сайта. Теперь можно:
- Изучить, как он устроен, что-то отредактировать и увидеть результат у себя на компьютере.
- Открыть файл index.html в браузере, и будет ощущение, что вы зашли на сайт, но с локального компьютера. Сайт откроется по протоколу file:// — это так браузер говорит нам, что файл взялся с нашего компьютера, а не из интернета.
- Запустить MAMP и завести на нём локальную копию сайта для экспериментов. Тогда браузер будет думать, что ходит за этим сайтом в интернет. Можно написать какие-нибудь php-скрипты и оживить сайт.
�� Важно понимать, что перед нами именно «слепок» — то, что мы бы увидели, если бы сервер сегодня ответил на наш запрос. Если завтра сервер будет отвечать по-другому, мы этого в своей локальной копии не увидим.
Когда ещё это пригодится
Защитить сайт перед наплывом пользователей. С помощью грабберов можно быстро создать неубиваемую статическую копию сайта и временно подменить ей динамическую версию сайта. Это полумера, но может сработать. А вообще вместо этого есть специальные надстройки, которые делают почти то же самое, но более умно, — поищите слово «кеширование».
Сделать копию своего блога, личного сайта или ещё чего-то важного вам, если вы потеряли к нему доступ, но сайт всё ещё на ходу.
Если вы едете туда, где не будет интернета, а вам нужна информация с сайта (например, путеводитель по чужой стране). Помните, что динамические карты и видеоролики так не сохранятся.
Сделать собственный «веб-архив» — это сервис, который ползает по сайтам и делает их «слепки» для истории. Благодаря этому сервису можно посмотреть, как выглядели ваши любимые сайты много лет назад — например, Яндекс.
Как скачать сайт полностью на компьютер?
Всем привет подскажите пожалуйста как скачать сайт www.bartek.wojtyca.pl/work/kceto.html себе на комп? Я качал через Teleport Pro, HTTrack но обе программы не полностью его качают! Они не могут скачать папку primary и все что в ней находится!
Жду ваших гениальных предложений!
- Вопрос задан более трёх лет назад
- 364532 просмотра
6 комментариев
Простой 6 комментариев
главный вопрос, зачем.
Saboteur @saboteur_kiev
По ftp не пробовали?
Андрей Васильченко @dron_4r Автор вопроса
Сергей: Это не мой сайт! так что FTP не канает
Андрей Васильченко @dron_4r Автор вопроса
386DX: Что бы был!
Saboteur @saboteur_kiev
Андрей Васильченко: Программы типа teleport pro и так далее устарели по своим алгоритмам, и подходят для примитивных сайтов. Современные динамические сайты адекватно и целиком такими методами скачать невозможно.

те же .php вытянуть не получится
Решения вопроса 0
Ответы на вопрос 13
Olejik2211 @Olejik2211
Чужой лендинг/сайт можно скачать с помощью webcloner.ru, если свой выгрузить хотите с сервера, то в помощь filezilla. Но если конструктор какой: тильда, викс, юкоз, то только через сервисы. Т.к. не дают они выгружать полностью сайт.
Ответ написан более трёх лет назад
Нравится 28 1 комментарий
А каким сервером бользоватся если через конструтор?
Владимир Мартьянов @vilgeforce
Раздолбай и программист
Ответ написан более трёх лет назад
Комментировать
Нравится 24 Комментировать
Попробуйте «Cyotek WebCopy».
www.cyotek.com/cyotek-webcopy
Ответ написан более трёх лет назад
Комментировать
Нравится 12 Комментировать
Чтобы скачать сайт целиком с помощью wget нужно выполнить команду:
wget -r -k -l 7 -p -E -nc http://site.com/
-r — указывает на то, что нужно рекурсивно переходить по ссылкам на сайте, чтобы скачивать страницы.
-k — используется для того, чтобы wget преобразовал все ссылки в скаченных файлах таким образом, чтобы по ним можно было переходить на локальном компьютере (в автономном режиме).
-p — указывает на то, что нужно загрузить все файлы, которые требуются для отображения страниц (изображения, css и т.д.).
-l — определяет максимальную глубину вложенности страниц, которые wget должен скачать (по умолчанию значение равно 5, в примере мы установили 7). В большинстве случаев сайты имеют страницы с большой степенью вложенности и wget может просто «закопаться», скачивая новые страницы. Чтобы этого не произошло можно использовать параметр -l.
-E — добавлять к загруженным файлам расширение .html.
-nc — при использовании данного параметра существующие файлы не будут перезаписаны. Это удобно, когда нужно продолжить загрузку сайта, прерванную в предыдущий раз.
Ответ написан более года назад
Комментировать
Нравится 9 Комментировать
archivarix @archivarix
Можно попровобать еще эту систему скачивания сайтов — https://ru.archivarix.com
Сервис скачитвает сайт онлайн, потом готовый сайт отправляет на емайл в zip файле вместе с CMS. Это будет работоспособный сайт, с лоадером и возможностью редактирования файлов, а не просто набор html файлов и картинок, который обычно получают при скачивании другими даунлоадерами. В этом основное отличие сервиса, по сути дела он импортирует скачиваемый сайт на свою CMS из любой другой, это дает огромные возможности для последующиего редактирования контента, вроде удаления битых ссылок, счетчиков и рекламы, создание новых страниц в скачанном сайте на основе существующих и тд.
Для того, чтобы посмотреть сайт на своем компьютере надо будет поставить локальный Apache сервер, например вот этот — https://www.apachefriends.org/ru/index.html
Ответ написан более трёх лет назад
Нравится 8 2 комментария
Эта программа больше предназначена не для скачивания сайта на комп, а для клонирования сайтов и для скачивания старых сайтов из web.archive.org. В отличие от всех других программ к скаченному сайту идет CMS, хоть и простая но вполне функциональная. Так что полученный контент можно легко подправить под свои нужды.

Руслан @Konovalovrg
archivarix а копируется ли сайт на Тильде с внутренним квизом в нем?
Java Developer
Выкачивал сайты с помощью программы Offline Explorer.
Скачивал без всяких проблем со всеми страницами и ресурсами.
На рутрекере много крякнутых версий данной программы.
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Андрей Васильченко @dron_4r Автор вопроса
Так же не может скачать!
Пробовал webparse.ru — можно скачать мобильную версию и десктопную. Доступны различные тарифы. Тестовая скачка бесплатна
Ответ написан более трёх лет назад
Нравится 4 1 комментарий
Спасибо большое!!
Web Developer
Есть ещё saveweb2zip.com, можно бесплатно скопировать сайт в архив, а там дальше делай с ним, что хочешь.
Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
- Найдите официальное API,
- Найдите XHR запросы в консоли разработчика вашего браузера,
- Найдите сырые JSON в html странице,
- Отрендерите код страницы через автоматизацию браузера,
- Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
�� Ого? Это не очевидно ��? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
Поищите XHR запросы в консоли разработчика

Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:

- Открывайте вебстраницу, которую хотите спарсить
- Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
- Открывайте вкладку Network и кликайте на фильтр XHR запросов
- Обновляйте страницу, чтобы в логах стали появляться запросы
- Найдите запрос, который запрашивает данные, которые вам нужны
- Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. �� Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? ��♀️ Нет! ��♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! ������
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):

Алгоритм действий такой:
- В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
- Внизу ищите длинную длинную строчку с данными.
- Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто requests.get .
- Вырезаете JSON из HTML любыми костылямии (я использую html.find(«= <") ).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_sourceSelenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver( enable_vnc=False, browser_name="firefox" ): capabilities = < "browserName": browser_name, "version": "", "enableVNC": enable_vnc, "enableVideo": False, "screenResolution": "1280x1024x24", "sessionTimeout": "3m", # Someone used these params too, let's have them as well "goog:chromeOptions": , "prefs": < "credentials_enable_service": False, "profile.password_manager_enabled": False >, > driver = webdriver.Remote( command_executor=SELENOID_URL, desired_capabilities=capabilities, ) driver.implicitly_wait(10) # wait for the page load no matter what if enable_vnc: print(f"You can view VNC here: ") return driverЗаметьте фложок enableVNC . Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход ��