Исправление ошибки #####
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Еще. Меньше
Приложение Microsoft Excel может отображать в ячейках символы #####, если ширины столбца недостаточно для отображения всего содержимого ячейки. В формулах, возвращающих дату и время как отрицательные значения, также может отображаться строка #####.
Чтобы расширить столбец и отобразить все содержимое ячейки, дважды щелкните правый край заголовка столбца или перетащите его на нужное расстояние.
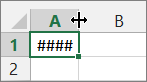
Также попробуйте сделать следующее.
- Чтобы уменьшить содержимое ячейки, нажмите кнопку Главная >
 рядом с кнопкой Выравнивание ,а затем в диалоговом окне Формат ячеек выберите нужный размер.
рядом с кнопкой Выравнивание ,а затем в диалоговом окне Формат ячеек выберите нужный размер. 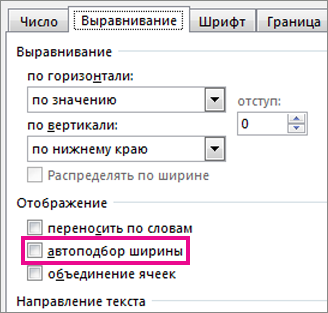
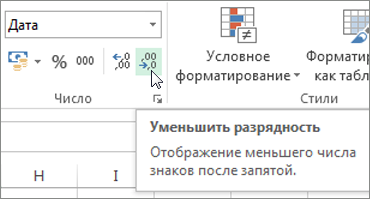
- Если число содержит слишком много знаков после запятой, щелкните Главная >Уменьшить разрядность.
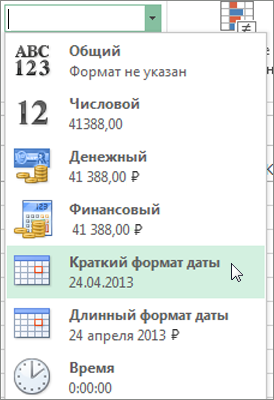
- Если даты слишком длинные, щелкните Главная, затем — стрелку рядом с элементом Формат чисел и выберите Краткий формат даты.
Исправление отрицательных значений даты или времени
Если Excel отображает символы #####, потому что ячейка содержит отрицательное значение даты или времени, сделайте следующее.
- При использовании системы дат 1900 убедитесь, что дата и время заданы положительными значениями.
- Используйте формулу для вычитания дат или правильного сложить или вычесть время, чтобы избежать отрицательных значений даты или времени.
- Для ячеек с отрицательными результатами в формате даты или времени выберите другой числовой формат.
Почему появляются символы в результате
3.3.2. Создание символов вручную и их редактирование
Рассмотрим последовательность операций по созданию нового символа компонента или его редактирования.
- Создание нового символа. Для создания нового символа переходят в режим редактирования символов и выбирают команду Part>New, в результате на экране появляется диалоговое окно для описания символа.
Это же окно активизируется по команде Part>Definition для редактирования информации о новом или существующем символе:
- Description — текстовое описание символа (например, биполярный п-р-п транзистор, резистор и т.п., к сожалению, только по-английски), которое просматривается при выборе символов из библиотек и используется в средствах поиска компонента по ключевым словам;
- Part Name — имя компонента, под которым он занесен в библиотеку символов;
- Alias List — список псевдонимов символа; при размещении символа на схеме можно равноправно указывать как основное имя (Part Name), так и любой из псевдонимов (Alias);
- АКО Name — имя прототипа, т.е. компонента, графика которого, выводы и все атрибуты переносятся для построения нового символа. При этом в текущем компоненте нужно отредактировать атрибуты и можно добавить новые и изменить текстовое описание, графику изменить нельзя — для этого нужно редактировать прототип. Символ компонента и его прототип должны находиться в одной и той же библиотеке. Этот способ значительно сокращает размер библиотек символов. Если у компонента имеется прототип, то в списке компонентов в скобках указывается его имя, например КТ316А (АКО NPN-R);
- Туре — тип компонента, принимающий значения:
- component — стандартные компоненты или иерархические символы;
- annotation — неэлектрические символы;
- hier port — соединения между разными уровнями иерархии;
- global port — глобальные узлы, соединяющиеся друг с другом на всех страницах схемы (например, соединение с «землей»);
- off page — соединители цепей на одной или разных страницах;
- title block — угловой штамп чертежа;
- border — рамка чертежа;
- marker — маркер для вывода графиков;
- viewpoint — отображение напряжения узла цепи в рабочей точке;
- current probe — отображение тока вывода в рабочей точке;
- optimizer parameter — задание значений оптимизируемых параметров;
- stimulus — указание узла, к которому подключается источник сигналов, созданный с помощью StmEd;
- simulation control — задание команд моделирования типа .IC, .NODESET;
- No Connect — отсутствие соединений.
Правильное назначение типа компонентов обеспечивает правильность выполнения ряда операций. Например, по команде Edit>Select All выбираются все символы схемы вместе с соединительными цепями, кроме символа углового штампа, имеющего тип title block. Это позволяет смещать изображение принципиальной схемы внутри рамки, оставляя угловой штамп на прежнем месте в нижнем правом углу листа. В противном случае угловой штамп перемещался бы вместе с остальными символами и его затем нужно было возвращать на прежнее место.
Для ввода текстовых переменных курсором выбирается соответствующее поле редактирования и на клавиатуре набирается текст. При этом для внесения в список псевдонимов Alias еще одного имени нажимается кнопка Add. Работа в диалоговом окне завершается выбором ОК.
- Графика символа. Графика символа компонента создается по командам Graphics . По окончании построения графики символа по команде Graphics>Bbox изменяют размеры прямоугольника, стороны которого нарисованы пунктирной линией, чтобы внутри контура прямоугольника находились все выводы компонента. Контур символа вычерчивается по командам Arc, Box,Circle и Line. Пояснительные надписи (к ним не относятся имена выводов и позиционное обозначение) наносятся по команде Text.
- Выводы компонента. Выводы компонента изображаются по команде Graphics>Pin . На экране появляются изображение вывода, помеченное крестиком, и линия вывода, которые перемещаются вместе с курсором. Прежде чем нажатием левой кнопки зафиксировать расположение вывода, можно «горячими» клавишами Ctrl+F, Ctrl+R и Ctrl+T зеркально отобразить линию вывода (Flip), повернуть ее на 90° (Rotate) и изменить тип вывода (Pin Type). Имеются следующие типы выводов:
- Normal — сигнал;
- Bubble — сигнал с инверсией;
- Clock — вход тактовых импульсов;
- Bubble Clock — инверсный вход тактовых импульсов;
- ANSI Inverted Out — выход в стандарте ANSI;
- ANSI Inverted In — вход в стандарте ANSI;
- ANSI Inverted Clock — инверсный вход тактовых импульсов в стандарте ANSI;
- Zero Length — вывод нулевой длины;
- Normal (long) — сигнал (длинный вывод);
- Bubble (long) — сигнал с инверсией (длинный вывод);
- Clock (long) — вход тактовых импульсов (длинный вывод);
- Bubble Clock (long) — инверсный вход тактовых импульсов (длинный вывод).
После фиксации вывода редактор предлагает разместить следующий вывод. Этот режим заканчивается двукратным нажатием левой кнопки.
В заключение по команде Graphics>Origin курсором указывается положение начала координат на чертеже символа, которое отмечается квадратиком . К нему привязан курсор при размещении символа на схеме.
При выполнении команды Graphics>Pin выводы нумеруются как 1, 2 и т.д. в порядке их подключения к символу и им присваиваются имена pin1, pin2 и т.д. Изменения номеров и/или имен выводов производятся в меню команды Part>Pin List .
В списке имен выводов, помещенном в правом верхнем углу меню, выбирается имя редактируемого вывода, и оно переносится в окно Pin Name. После изменения имени вывода нужно включить/выключить опцию Display Name, чтобы это имя было видно/не видно на схеме. Одновременно редактируется тип вывода и его ориентация. На панели атрибутов вывода (Pin Attributes) изменяется номер вывода и указывается реакция модуля контроля ошибок электрической схемы (ERC), если на схеме к данному выводу не подключена ни одна цепь. В выпадающем списке If unconnected выбирается один из следующих вариантов:
- Error — выводится сообщение об ошибке (список соединений не составляется);
- RtoGND — вывод подключается к «земле» через резистор с большим сопротивлением;
- UniqueNet — создается новое имя цепи (для контроля состояния цепи и подключения к этому выводу маркера программы Probe).
В строке Modeled Pin каждому выводу присваивается признак его участия в моделировании. Если в описании модели компонента какой-нибудь вывод не участвует (например, вывод для подачи напряжения смещения на операционный усилитель), ему этот признак не присваивается, и на схеме он будет изображен пунктиром.
- Редактирование выводов компонента. После нанесения на чертеж всех выводов компонента и их атрибутов может возникнуть необходимость их редактирования. Для задания типа вывода его сначала необходимо выбрать (например, одинарным нажатием левой кнопки мыши) и затем по команде Edit>Pin Type (Ctrl+T) назначить тип вывода (одинарнре выполнение этой команды переключает тип вывода на одну позицию в списке»типов). Тип вывода, а также все его остальные атрибуты вводятся на панели диалога после двукратного нажатия левой кнопки при расположении курсора на выбранном выводе (аналогично команде Edit>Change). В нем редактируются следующие параметры:
- Pin Name — имя вывода;
- Туре — тип графического изображения вывода (т.е. указателя вывода);
- Hidden — признак скрытого вывода, который не отображается на схеме (например, на схемах цифровых устройств не принято изображать цепи подключения питания и «земли», для операционных усилителей не всегда указывают подключение цепей питания), но необходим для моделирования (крестик слева от опции Hidden свидетельствует о ее активизации);
- Net — имя проводника, к которому на схеме должен быть подключен скрытый вывод (на рис. 3.40 показано, что скрытый вывод V+ подключения источника питания микросхемы на рис. 3.39 должен быть соединен с цепью, имеющей на схеме имя $G_+15V);
- Display Name — вывод на чертеж схемы имен выводов;
- Size, Orient, Hjust, Vjust — размер, ориентация, горизонтальная и вертикальная привязка имен выводов;
- Pin — порядковый номер вывода;
- ERC — электрический тип вывода, используемый только при выполнении команды поиска ошибок схемы Electrical Rule Check, принимающий значения:
- don’t care — не проверяется;
- input — вход;
- output — выход;
- bidir — двунаправленный вывод;
- highZ — высокий импеданс;
- open collec — открытый коллектор;
- open emitter — открытый эмиттер;
- power — подключение источника питани.
Из рассматриваемой панели выбором командной кнопки Edit Attributes переходят в панель диалога для редактирования атрибутов выводов.Просмотр имен всех выводов и при необходимости их редактирование производятся по команде Part>Pin List (Ctrl+P).
- Редактирование атрибутов и шаблона символа. На заключительном этапе создания символа компонента редактируют введенные ранее и дописывают новые атрибуты, задается его шаблон. Это производится одним из двух способов.
1 способ. По команде Part>Attributes возможно редактирование всех существующих атрибутов символа и добавление новых с помощью диалогового окна .
2 способ. Курсор устанавливается на редактируемый атрибут компонента, и два раза щелкают левой кнопкой мыши. В результате управление передается в панель диалога для изменения этого атрибута . В связи с тем, что способ редактирования атрибутов в различных панелях диалога одинаков, обсудим работу в изображенной на панели с наиболее полной информацией. На ней имеются следующие поля:
- Name — задание имени атрибута (если атрибут с введенным именем существует, то можно отредактировать его значение);
- Value — значение атрибута;
- What to Display (что выводить на экран):
- — Value only — только значение атрибута;
- — Name only — только имя атрибута;
- — Both name and value — имя и значение атрибута;
- — Both name and value only if value define — имя и значение атрибута, если его значение определено;
- — None — ничего;
- — Layer — задание слоя, на котором размещается имя и/или значение атрибута (видимость на экране информации, размещенной в разных слоях, устанавливается по,команде Options>Set Display Level);
- — Orient — ориентация текста атрибута;
- — Hjust — привязка текста по горизонтали (левая, по центру, правая);
- — Vjust — привязка текста по вертикали (нижняя, по центру, верхняя);
- — Size — масштаб изображения текста в процентах;
Обсудим, как редактируются атрибуты. В поле списка на правой стороне панели диалога приводится перечень всех атрибутов компонента. Для ввода нового атрибута курсором отмечается первая свободная строка в поле списка, а для редактирования существующего — строка, где он расположен. В результате в верхнем поле редактирования (Name) появляются имя атрибута, а во втором (Value) — его значение, которые редактируются как обычные текстовые переменные. Результаты редактирования сохраняются после выбора командной кнопки Save Attr (отмена Del Attr). Назначение отдельных атрибутов символов подробно обсуждается в п. 3.3.3. Правила составления шаблона символа и его редактирования также подробно излагаются в п. 3.3.3.
- Копирование символов. По команде Part>Copy создается новый символ путем копирования графической и текстовой информации одного из существующей. В диалоговом окне этой команды сначала на строке Existing Part Name указывают имя существующего компонента (его удобно выбрать из списка в окне Part), затем на строке New Part Name вводится имя нового компонента. После нажатия кнопки ОК на экране появляется графическое изображение символа и по командам Part>Attribute и Part>Definition вводятся необходимые коррективы в текстовую информацию (исправляется имя модели компонента, корректируется при необходимости его описание и т.п.). При этом если копируемый компонент имел прототип АКО, этот же прототип присваивается и новому компоненту.
- Создание символов с помощью программы Model Editor. Отметим здесь способность программы Model Editor создавать типовые графические символы компонентов, для которых рассчитаны параметры математической модели (символ компонента помещается в библиотеку символов, имеющую то же имя, что и библиотека математических моделей). См. подробнее разд. 4.2.
- Упаковочная информация. Для обеспечения возможности создания печатных плат символы компонентов необходимо сопроводить так называемой информацией об упаковке. Проиллюстрируем это на примере цифровой ИС 1533ЛАЗ, содержащей 4 логических элемента (секции) 2И-НЕ. Сначала создается символ секции 2И-НЕ этого компонента , и вводятся его атрибуты:
TEMPLATE=X A @REFDES %A %B %Y %PWR %GND ©MODEL PARAMS: n\
В состав одной секции входят только три вывода: входы А, В и выход Y. Выводы «питания» PWR и «земли» GND обычно не должны быть видимы на схеме (имеют признак «Hidden») и они относятся не к отдельной секции, а к компоненту в целом.
Информация об упаковке компонента вводится с помощью Мастера по команде Packaging>New в последовательности диалоговых окон . Сначала в окне Set Up Packaging указывают общие сведения:
- Package Name — имя упаковочной информации;
- Are there multiple gates in this package? Yes/No — наличие в корпусе компонента нескольких одинаковых секций;
- Are there swappable pins? Yes/No — наличие логически эквивалентных выводов, которые можно переставлять между собой в целях упрощения трассировки проводников.
В следующем диалоговом окне Set Up Multi Gate Package указывается количество секций и отмечается наличие общих для всех секций выводов :
- Number of Gates — количество секций;
- Number Pins per Gate — количество выводов в одной секции;
- Use letters or numbers for Gate Names: Letters/Numbers — обозначение секций буквами или цифрами;
- Are there pins that are shared between gates (e.g. power and ground pins)? Yes/No — наличие выводов, общих для всех секций (например, выводов питания и земли).
Далее в окне Specify Footprint указывается имя одного или нескольких корпусов (Footprint), ассоциируемых с данным компонентом (все они должны иметь одинаковое количество выводов): Footprint — одно или несколько имен корпусов, разделяемых запятыми.
В окне Assign Shared Pins указывают имена и номера выводов, являющихся общими для компонента :
- Shared Pin Name — имя вывода;
- Number — номер вывода.
В окне Assign Pins (Multi Gates) указывают номера однотипных выводов во всех секциях, имеющих одинаковые логические имена :
- Shared — признак общего вывода (имена и номера этих выводов переносятся из предыдущего окна);
- Pin Name — логическое имя вывода;
- Numbers — номера выводов, принадлежащих разным секциям и имеющим одно и то же логическое имя (разделяются запятыми).
В последнем окне Set Up Package Pin Swaps указывают имена логически эквивалентных выводов :
- Pin Names — общий список имен выводов секции компонента, в котором курсором выбираются имена логически эквивалентных выводов и нажимают кнопку Assign;
- Pin Swaps — имена логически эквивалентных выводов.
Полная информация об упаковке компонента выводится по команде Packaging>Edit и ее можно при необходимости отредактировать. Нажатие на кнопку Print выводит на печать полную информацию о символе компонента.
- Библиотека символов и библиотека компонентов. Информация о символах компонентов заносится в текстовые файлы библиотек, имеющих расширение имени .SLB. Графическая и текстовая информация отдельных символов заносится в файлы с расширением имени .SYM по команде Part>Export и могут быть включены в другие библиотеки по команде Part>Import.
Текстовая информация о компонентах заносится в библиотечные файлы с расширением имени .PLB. Они содержат ссылки на имена символов компонентов и их упаковочную информацию. В табл. 3.6 в качестве примера приведен фрагмент файла библиотеки отечественных ИС серии 1533, содержащейся в файле 1533.plb. По команде Packaging>Export из библиотеки компонентов извлекается информация об упаковке одного или нескольких компонентов, которая заносится в файл с расширением имени .PKG.
Таблица 3.6. Фрагмент библиотеки компонентов и информация об упаковке одного компонента
Файл 1533 LAS.pkg
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 2 8 =256).
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
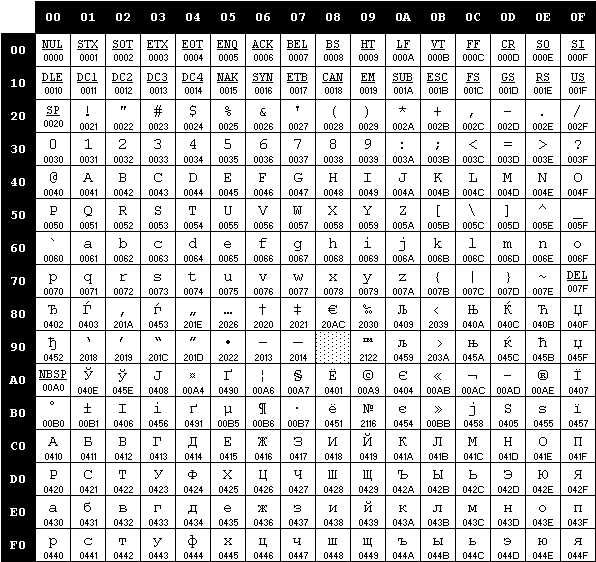
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Unicode
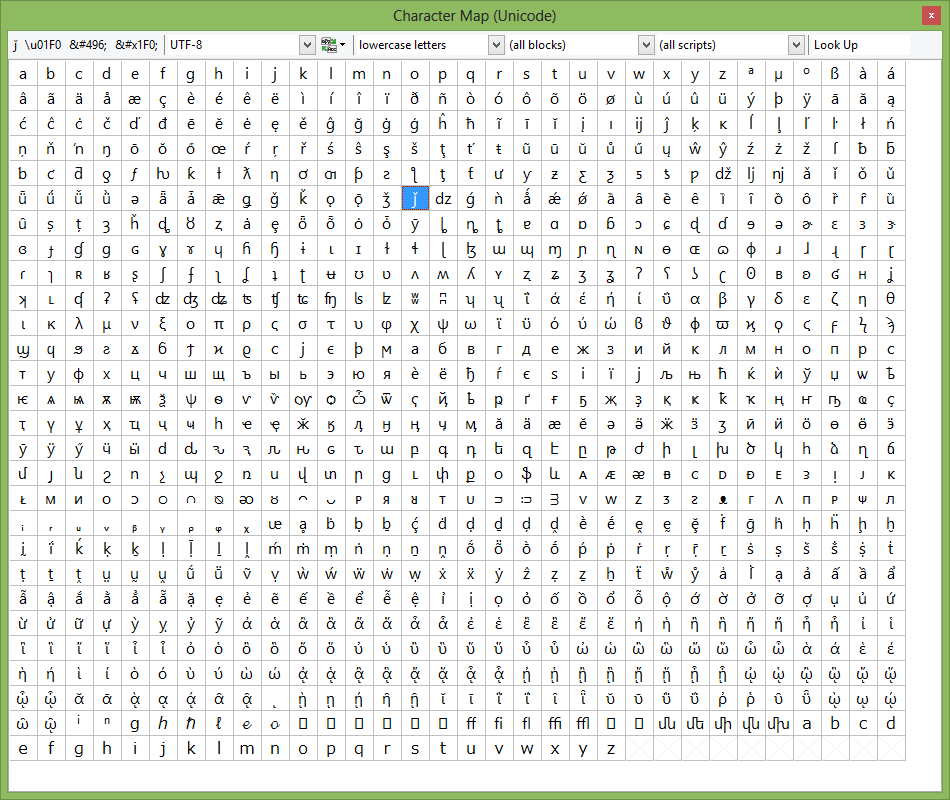
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111 . В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111 . И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
110 10000 10 111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся ( 10000111100 ), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 = 0000000000 1111010101 (ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять))
- 0 + D800 = D800 ( 110110 0 000000000 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат
- 3D5 + DC00 = DFD5 ( 110111 1 111010101 ) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат
- итого данный символ в UTF-16 — 1101100000000000 1101111111010101
- переведем в шестнадцатиричный вид = D822DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
- 110110 0 000100010 — десятый бит (справа) нулевой, значит первый суррогат
- 110111 1 010001000 — десятый бит (справа) единица, значит второй суррогат
- отбрасываем по 6 бит отвечающих за определение суррогата, получим 0000100010 1010001000 (8A88)
- прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символовОснова основ – кодировка ASCII и ее современные интерпретации.
На сегодняшний день кодировка ASCII представляет собой стандартом представления первых 128-значений (включая цифры и знаки препинания) английского алфавита, представленных в определенном порядке.
Однако, даже 1 байт позволяет закодировать в 2 раза больше значений, то есть не 128, а целых 256 разных значений. Поэтому достаточно быстро на смену базовой ASCII стали появляться более расширенные варианты этой знаменитой и популярной по сей день кодировки, в которых кодировались также символы алфавитов и, соответственно, текста различных языков, в том числе и русского.
Расширения ASCII для России
На сегодняшний день для российских пользователей приоритетными являютсякодировка Windows1251 и кодировка юникод, а также UTF 8, которые произошли от ASCII.
Собственно говоря, у кого-то может возникнуть весьма справедливый вопрос: «А зачем вообще нужны эти кодировки текстов?»
Стоит помнить, что компьютер – это всего-навсего машина, которая должна действовать четко по инструкциям. Чтобы было понятно, что нужно делать с каждым символом написанного, его представляют в виде набора векторных форм, каждый набор которых отправляет в нужное место, чтобы на экране появлялось то или иное обозначение.За формирование векторных форм отвечают шрифты, а сам процесс кодирования зависит от операционной системы, а также используемых в ней программ. Таким образом, каждый текст по своей сути – это некоторый набор байтов, в каждом из них представлена кодировка одного написанногосимвола. А программа, занимающаяся отображением напечатанной информации на экране (это может быть браузер или текстовый процессор), разбирает код, находит подходящее отображение по его коду в таблице кодировок, преобразует в необходимую векторную форму и отображает в текстовом файле.
Кодировка CP866 и KOI8-R широко применялись до появления графической операционной системы, завоевавшей популярность во всем мире, — Windows. Теперь самой популярной кодировкой, поддерживающей русский, стала Windows1251.
Однако, она не единственная, поэтому у производителей шрифтов для русского, используемых в программном обеспечении, периодически даже до сих пор появляются затруднения, связанные с неверным отображением символов и появлением так называемой кракозябры. Эти несуразные иероглифы являются результатом некорректного использования таблиц кодировок, то есть при кодировании и декодировании использовались разные таблицы.
Такая же ситуация имеет место и на сайтах, блогах и прочих ресурсах, где есть информация на русском и прочих иностранных символах, отличных от английских. Данная ситуация определила основную предпосылкой создания универсальной кодировки, позволяющей кодировать текст на любом языке, даже китайском, где символов значительно больше, чем 256.
Универсальные кодировки
Первой версией универсальной кодировки, разработанной в рамках консорциума Юникод, была кодировка UTF 32. Для кодирования каждого символа использовалось 32 бита. Теперь была реализована возможность кодирования огромного количества знаков, но появилась другая проблема –большинству европейских стран такое число лишних символов было совершенно не нужно. Ведь документы получались очень тяжелыми. Поэтому на смену UTF 32 пришла UTF 16, ставшая базовой для всех символов, используемых в нашей стране и не только.
Но все равно оставалось достаточно много недовольных. Например, те, кто общался только на английском языке, так как при переходе с ASCII на UTF 16 их документы все равно увеличивались в размерах, причем существенно, практически в 2 раза.
В результате появилась кодировка переменной длинны UTF 8, что позволило не увеличивать вес текста.Кракозябры и методы борьбы с ними
Вообще, кодировка задается на странице, где создается само информационное сообщение. В результате, в начале документа формируется своеобразная метка, в которой запоминается, в прямом или обратном порядке записаны коды символов UTF16.
Если что-то было напечатано в UTF-8, то никакого маркера в начале нет, так как сама возможность записи кода символа в обратном порядке в этой кодировке отсутствует.
Поэтому, следует сохранять все, что набрано в редакторе, без маркеров (BOM), чтобы снизить вероятность появления кракозябров в документе.
Помимо правильного сохранения рекомендуется отказаться от использования стандартного редактора Windows«Блокнот», а выбрать более совершенную среду для редактирования документов сайта.
Еще одним полезным советом по борьбе с кракозябрами – прописать в шапке кода каждой страницы сайта информацию о правильной кодировке текста, чтобы ни на локальном хосте, ни на сервере не было путаницы.