Squeezed text python что это
Анализ тональности текста (анализ настроений, анализ мнений) — это классическая задача Машинного обучения (ML), позволяющая идентифицировать, извлекать и количественно оценивать текстовые данные для облегчения Классификации (Classification) и работы с ними. К примеру, если речь идет о Текстовом блоке (Corpus) комментариев к продуктам, Sentiment Analysis способен, среди прочих, с помощью определения эмоциональной окраски:
- Определить основные причины популярности тех или иных наименований
- Определить неучтенные потребности пользователей, аспекты или особенности товара, вызвавшие отрицательные эмоции
- Быстро найти жалобы среди большого потока комментариев
- Сгенерировать комментарии для непродающихся публикаций
- Быстро найти спам
- Сгруппировать похожие товары
- Определить вызывающие проблемы процессы, например, взаимодействие со службой техподдержки
- Лечь в основу рекомендательной системы и т.д.
Это измеримый способ понять и проанализировать общественное восприятие различных идей и концепций или недавно запущенного продукта.
Мы используем различные инструменты Обработки естественного языка (NLP) и анализа текста, чтобы выяснить, что может быть субъективной информацией. Нам нужно идентифицировать, извлечь и количественно оценить такие детали из текста для облегчения классификации и работы с данными.
Понимание эмоций и анализ настроений играют огромную роль в системах рекомендаций на основе совместной фильтрации. Группировка людей, имеющих сходную реакцию на определенный продукт, и показ им похожих продуктов. Например, рекомендовать фильмы людям, группируя их с другими людьми, имеющими схожие взгляды на определенное шоу или фильм.
Как работает анализ тональности?
Обработка естественного языка — это основная концепция, на которой строится анализ настроений. Это ветвь Искусственного интеллекта (AI), работающая с текстами, дающая машинам возможность «понимать» предложения и использовать эту способность.
В зависимости от объема текстового блока Sentiment Analysis можно разделить на анализ на уровне документа, предложения и фразы.
Выделяют два основных метода анализа мнений:
- Анализ тональности на основе словарей эмоций: существует предопределенный список слов для каждого настроения; текст или документ сопоставляют с такими списками. Затем алгоритм определяет, какой тип слов или какая Полярность (Polarity) преобладает в нем. Этот тип анализа настроений на основе правил прост в реализации, но ему не хватает гибкости и он не учитывает контекст.
- Автоматический анализ тональности в основном основан на контролируемых алгоритмах Машинного обучения и на самом деле очень полезен для понимания сложных текстов. Алгоритмы в этой категории включают Метод опорных векторов (SVM), Линейную регрессию (Linear Regression), Рекуррентную нейросеть (RNN) и ее подвиды. В этой статье мы будем использовать рекуррентную нейронную сеть.
Система анализа настроений
Рекуррентные нейронные сети – это еще и способ превратить текстовые данные в последовательные, то есть такие, что каждая последующая запись зависит от предыдущей. Рекуррентные нейронные сети имеют собственную память и запоминают входные данные, которые были переданы каждому узлу. В Нейронных сетях прямого распространения (Feed Forward Neural Network) информация – входные данные, перемещается вперед и никогда не перемещаются назад ни в каких узлах. Поскольку у таких сетей нет памяти, они не запоминают предыдущие вводы:

RNN же учитывает, какие вводные данные она получила, также как и предыдущие итерации ввода. Рекуррентная нейронная сеть создает копию выходных данных и зацикливает ее отправку обратно.
Например, когда предложение передается через нейросеть прямого распределения, она принимает слово за словом, пока не достигнет последнего. Она не помнит, что выдавали до этого. Но РНН также знает предыдущие входные данные и, таким образом, может предсказать, что может произойти дальше. Идеально для последовательных данных!
Рекуррентные нейронные сети не новы, они были впервые представлены в 1980-х годах, но стали очень популярными с ростом Глубокого обучения (Deep Learning) и его использования в последовательных данных. Тем не менее, у Рекуррентных нейросетей есть свой собственный набор проблем, основной из которых является Проблема исчезающего градиента (Vanishing Gradient Problem).
Ответом на этот вопрос является Долгая краткосрочная память (LSTM). Это особый тип модели RNN, который может изучать долгосрочные зависимости. Она сделана, чтобы «помнить» долгосрочные данные. Что делает LSTM особенной, так это дополнительная ячейка памяти, которая является повторяющимся состоянием, и каждая из них имеет несколько Гейтов (Gate), которые контролируют поток информации в ячейку памяти и из нее:

Входные ворота (Input Gate) используются для обновления состояния ячейки, Гейт забывания (Forget Gate) решает, какую информацию следует сохранить, а какую следует отбросить. Выходной гейт (Output Gate) определяет значения для следующих скрытых гейтов.
Анализ настроений: PyTorch
Теперь, когда у нас есть общее представление о концепции, попробуем реализовать такую модель с помощью PyTorch. Мы создадим простой классификатор тональности, который будет классифицировать, были ли отзывы пользователей о фильме на IMDB положительными, отрицательными или нейтральными.
Датасет (Dataset), который мы будем использовать, представляет собой 50 000 отзывов на фильмы. Это набор данных для Двоичной классификации (Binary Classification), в котором каждый обзор классифицируется как положительный или отрицательный.
Установим библиотеку torchtext , из которой и возьмем датасет:
!pip install torchtext==0.10.0Импортируем необходимые библиотеки:
import random import spacy import time import torch import torch.nn as nn import torch.optim as optim import torchtext from torchtext.legacy import data from torchtext.legacy import datasetsМы собираемся использовать метод data.field , чтобы решить, как данные должны быть предварительно обработаны. Параметры, которые мы туда передаем, будут определять предварительную обработку:
seed = 42 torch.manual_seed(seed) torch.backends.cudnn.deterministic = True device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') txt = data.Field(tokenize = 'spacy', tokenizer_language = 'en_core_web_sm', include_lengths = True) labels = data.LabelField(dtype = torch.float)Первый параметр, наш tokenizer_language (который определяет, как предложения будут разбиты на токены) — это модуль en_core_web_sm для английского языка библиотеки spacy. По умолчанию он просто разделит текст с помощью пробелов.
Мы также устанавливаем случайное начальное число seed , которое может принимать любое значение, но мы упоминаем его только для целей воспроизводимости (чтобы и при верстке статьи, и при самостоятельном запуске кода читателем результаты были идентичны). Вы можете изменить его или даже опустить без какого-либо существенного эффекта.
Мы также будем использовать cuda , а также доступный нам Центральный процессор (CPU).
Загрузим набор данных и разделим его на Тренировочные (Train Data) и Тестовые данные (Test Data). Набор уже разделен.
train_data, test_data = datasets.IMDB.splits(txt, labels)Далее мы выделим из тренировочных данных еще и Валидационные данные (Validation Data):
train_data, valid_data = train_data.split(random_state = random.seed(seed))Мы дополнительно ограничим количество слов, которые освоит модель, до 25000:
num_words = 25_000 txt.build_vocab(train_data, max_size = num_words, vectors = "glove.6B.100d", unk_init = torch.Tensor.normal_) labels.build_vocab(train_data)Это позволит выбрать наиболее часто используемые 25000 слов из набора данных и использовать их для обучения. Так мы значительно сократим работу модели без реальной потери точности.
Воспользуемся преимуществами Пакетов (Batch), то есть разделим данные на части по 64 записи. Если этого не сделать, памяти не хватит:
btch_size = 64 train_itr, valid_itr, test_itr = data.BucketIterator.splits( (train_data, valid_data, test_data), batch_size = btch_size, sort_within_batch = True, device = device)Теперь подготовим модель и определим ее архитектуру. Мы используем многослойный двунаправленный LSTM RNN для нашей задачи. Это означает, что будет несколько слоев нейросети, наложенных друг на друга.
Двунаправленная RNN имеют то преимущество, что охватывает больше контекста, чем однонаправленная сеть. Например, если модель должна угадать следующее слово в предложении, она сделает это на основе предыдущих знаний. Но в двунаправленной сети он также будет знать, что будет дальше, благодаря двум сетям, текущим как бы в противоположных направлениях и наложенных друг на друга. Предложение «я люблю машинное обучение» будет в первой сети выглядеть как «я», «люблю», «машинное», «обучение» а во второй — как «обучение», «машинное», «люблю», «я». Это обеспечивает более полный контекст, хоть и воспринимается как некое мошенничество.
Мы, проще говоря, разместим слова так, чтобы похожие слова были сгруппированы вместе:
class RNN(nn.Module): def __init__(self, word_limit, dimension_embedding, dimension_hidden, dimension_output, num_layers, bidirectional, dropout, pad_idx): super().__init__() self.embedding = nn.Embedding(word_limit, dimension_embedding, padding_idx=pad_idx) self.rnn = nn.LSTM(dimension_embedding, dimension_hidden, num_layers=num_layers, bidirectional=bidirectional, dropout=dropout) self.fc = nn.Linear(dimension_hidden * 2, dimension_output) self.dropout = nn.Dropout(dropout) def forward(self, text, len_txt): embedded = self.dropout(self.embedding(text)) packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, len_txt.to('cpu')) packed_output, (hidden, cell) = self.rnn(packed_embedded) output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output) hidden = self.dropout(torch.cat((hidden[-2. ], hidden[-1. ]), dim = 1)) return self.fc(hidden)Мы определяем параметры для модели и передаем их экземпляру класса RNN , который мы только что определили. Определяется количество входных параметров, скрытого слоя и выходного измерения, а также пропускной способности и логического значения двунаправленности. Мы также передаем индекс маркера площадки из словаря, который мы создали ранее.
Теперь мы зададим явно некоторые настройки нашей модели:
dimension_input = len(txt.vocab) dimension_embedding = 100 dimension_hddn = 256 dimension_out = 1 layers = 2 bidirectional = True droupout = 0.5 idx_pad = txt.vocab.stoi[txt.pad_token] model = RNN(dimension_input, dimension_embedding, dimension_hddn, dimension_out, layers, bidirectional, droupout, idx_pad)Затем мы получаем предварительно обученные веса вложений и копируем их в нашу модель, чтобы ей не нужно было изучать вложения, и мы могли напрямую сосредоточиться на текущей работе по изучению настроений, связанных с этими вложениями:
def count_parameters(model): return sum(p.numel() for p in model.parameters() if p.requires_grad) print(f'Модель обладает тренируемыми параметрами')>>> Модель обладает 4,810,857 тренируемыми параметрамиПредварительно обученные встраивающие веса размещаются вместо исходных:
pretrained_embeddings = txt.vocab.vectors print(pretrained_embeddings.shape)>>> torch.Size([25002, 100])model.embedding.weight.data.copy_(pretrained_embeddings)>>> tensor([[ 1.9269, 1.4873, 0.9007, . 0.1233, 0.3499, 0.6173], [ 0.7262, 0.0912, -0.3891, . 0.0821, 0.4440, -0.7240], [-0.0382, -0.2449, 0.7281, . -0.1459, 0.8278, 0.2706], . [ 0.2735, -0.1130, 0.2871, . -0.8155, -0.0639, 0.9330], [-1.1777, -0.1115, -0.1409, . 0.8815, 0.1093, 1.1222], [-0.8087, 0.4473, 0.0443, . -1.2134, 0.4822, 0.0481]])unique_id = txt.vocab.stoi[txt.unk_token] model.embedding.weight.data[unique_id] = torch.zeros(dimension_embedding) model.embedding.weight.data[idx_pad] = torch.zeros(dimension_embedding) print(model.embedding.weight.data)>>> tensor([[ 0.0000, 0.0000, 0.0000, . 0.0000, 0.0000, 0.0000], [ 0.0000, 0.0000, 0.0000, . 0.0000, 0.0000, 0.0000], [-0.0382, -0.2449, 0.7281, . -0.1459, 0.8278, 0.2706], . [ 0.2735, -0.1130, 0.2871, . -0.8155, -0.0639, 0.9330], [-1.1777, -0.1115, -0.1409, . 0.8815, 0.1093, 1.1222], [-0.8087, 0.4473, 0.0443, . -1.2134, 0.4822, 0.0481]])Теперь мы определяем некоторые параметры модели, то есть Оптимизатор (Optimizer), который мы собираемся использовать, и критерий Функции потери (Loss Function), который нам подходит. Мы выбрали Адаптивную оценку момента (Adam) для быстрой Сходимости (Convergence) модели, то есть сокращения ошибок. Размещаем модель и критерий на Графическом процессоре (GPU):
optimizer = optim.Adam(model.parameters())Теперь мы приступаем к необходимым функциям для обучения и оценки модели анализа настроений.
criterion = nn.BCEWithLogitsLoss() model = model.to(device) criterion = criterion.to(device)def bin_acc(preds, y): predictions = torch.round(torch.sigmoid(preds)) correct = (predictions == y).float() acc = correct.sum() / len(correct) return accbin_acc — это функция двоичной точности, которую мы будем использовать для получения точности модели каждый раз.
def train(model, itr, optimizer, criterion): epoch_loss = 0 epoch_acc = 0 model.train() for i in itr: optimizer.zero_grad() text, len_txt = i.text predictions = model(text, len_txt).squeeze(1) loss = criterion(predictions, i.label) acc = bin_acc(predictions, i.label) loss.backward() optimizer.step() epoch_loss += loss.item() epoch_acc += acc.item() return epoch_loss / len(itr), epoch_acc / len(itr)Определим функцию train для обучения и оценки моделей. Мы начинаем с циклического перебора количества Эпох (Epoch). Число итераций в каждой эпохе зависит от размера пакета, который мы задали равным 64. Мы передаем текст в модель, получаем от нее прогнозы, вычисляем потери для каждой итерации, а затем используем Метод обратного распространения ошибки (Backpropagation).
Единственное существенное изменение в функции оценки по сравнению с функцией обучения заключается в том, что мы не распространяем потери в обратном направлении по модели и используем torch.nograd, что в основном означает отсутствие Градиентного спуска (Gradient Descent) при оценке.
def evaluate(model, itr, criterion): epoch_loss = 0 epoch_acc = 0 model.eval() with torch.no_grad(): for i in itr: text, len_txt = i.text predictions = model(text, len_txt).squeeze(1) loss = criterion(predictions, i.label) acc = bin_acc(predictions, i.label) epoch_loss += loss.item() epoch_acc += acc.item() return epoch_loss / len(itr), epoch_acc / len(itr)def epoch_time(start_time, end_time): used_time = end_time - start_time used_mins = int(used_time / 60) used_secs = int(used_time - (used_mins * 60)) return used_mins, used_secsМы создаем вспомогательную функцию epoch_time для расчета времени, которое требуется каждой эпохе для завершения своего запуска и печати.
num_epochs = 5 best_valid_loss = float('inf') for epoch in range(num_epochs): start_time = time.time() train_loss, train_acc = train(model, train_itr, optimizer, criterion) valid_loss, valid_acc = evaluate(model, valid_itr, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) if valid_loss < best_valid_loss: best_valid_loss = valid_loss torch.save(model.state_dict(), 'tut2-model.pt') print(f'Эпоха: | Время на эпоху: m s') print(f'\tТренировочные потери: | Тренировочная точность: %') print(f'\t Валидационные потери: | Валидационная точность: %')Мы устанавливаем количество эпох равным 5, а затем начинаем наше обучение. Отобразим потери при обучении и проверке на каждом этапе, если нам нужно понять или построить кривую обучения на более позднем этапе. Мы сохраняем ту модель, которая имеет наименьшие потери при Валидации (Validation).
>>> Эпоха: 01 | Время на эпоху: 0m 35s Тренировочные потери: 0.649 | Тренировочная точность: 61.34% Валидационные потери: 0.583 | Валидационная точность: 72.39% Эпоха: 02 | Время на эпоху: 0m 36s Тренировочные потери: 0.561 | Тренировочная точность: 71.81% Валидационные потери: 0.460 | Валидационная точность: 79.26% Эпоха: 03 | Время на эпоху: 0m 38s Тренировочные потери: 0.549 | Тренировочная точность: 71.97% Валидационные потери: 0.358 | Валидационная точность: 84.73% Эпоха: 04 | Время на эпоху: 0m 38s Тренировочные потери: 0.432 | Тренировочная точность: 80.96% Валидационные потери: 0.353 | Валидационная точность: 85.52% Эпоха: 05 | Время на эпоху: 0m 38s Тренировочные потери: 0.313 | Тренировочная точность: 87.03% Валидационные потери: 0.299 | Валидационная точность: 87.52%Загружаем сохраненную контрольную точку модели и тестируем ее на созданном ранее тестовом наборе:
model.load_state_dict(torch.load('tut2-model.pt')) test_loss, test_acc = evaluate(model, test_itr, criterion) print(f'Тестовые потери: | Тестовая точность: %')Во время пробного запуска модели анализа настроений Python мы достигли приличной оценки точности 87.42%:
>>> Тестовые потери: 0.301 | Тестовая точность: 87.42%Мы также можем проверить модель на наших данных. Он обучен классифицировать обзоры фильмов на положительные, отрицательные и нейтральные, поэтому мы будем передавать ему соответствующие данные для проверки:
nlp = spacy.load('en_core_web_sm') def pred(model, sentence): model.eval() tokenized = [tok.text for tok in nlp.tokenizer(sentence)] indexed = [txt.vocab.stoi[t] for t in tokenized] length = [len(indexed)] tensor = torch.LongTensor(indexed).to(device) tensor = tensor.unsqueeze(1) length_tensor = torch.LongTensor(length) prediction = torch.sigmoid(model(tensor, length_tensor)) return prediction.item()Мы загружаем англоязычный модуль spacy для токенизации данных, которые нам нужно передать модели. Вначале мы использовали встроенный torch.text , но здесь мы не используем пакеты, и предварительная обработка, которую нам нужно сделать, может быть выполнена библиотекой spacy . Для этого мы определяем функцию pred прогнозирования тональности. После предварительной обработки мы конвертируем данные в Тензоры (Tensor) и готовим их к передаче в модель.
Мы определяем еще одну вспомогательную функцию, которая будет печатать тональность комментария на основе оценки, предоставленной моделью:
sent = ["Положительный", "Нейтральный", "Отрицательный"] def print_sent(x): if (x < 0.3): print(sent[0]) elif (x >0.3 and x < 0.7): print(sent[1]) else: print(sent[2])Теперь мы просто передаем любые данные и проверяем, что об этом думает модель:
print_sent(pred(model, "This film was average")) print_sent(pred(model, "This film is horrible")) print_sent(pred(model, "This film was great")) print_sent(pred(model, "This was the best movie i have seen in a while. The cast was great and the script was awesome, and the direction just blew my mind"))>>> Нейтральный Отрицательный Положительный ПоложительныйМы успешно разработали модель анализа тональности Python, основанную на LSTM, которая является довольно надежной и очень точной.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: data-flair.training
Статьи об ML / DL с примерами кода
Что такое Squeeze page на сайте? (Подсказка: эта страница поможет вам мгновенно превратить посетителей сайта в покупателей)
Обычные значения конверсии на сайтах зависают где-то в районе однозначных чисел. Это означает, что большинство посетителей вашего сайта закроют его и никогда не вернутся.
В довершение, у вас есть только 17 миллисекунд на то, чтобы произвести на посетителя первое впечатление, пока он не решит, уйти с сайта или остаться.
Но вы можете их повысить, используя сквиз пейдж (squeeze page) - дополнительную страницу на сайте, которая собирает всю важную информацию о покупателе, давая вам возможность связаться с ним после того, как он покинет сайт.
Давайте изучим принцип работы таких страниц, как выглядят лучшие из них и как начать их использовать на своем сайте, чтобы увеличить конверсию.

Как работают сквиз пейджи?
Целевая страница (лендинг пейдж, Landing page) - это любая страница в интернете, имеющая одну конкретную цель. Такие страницы содержат довольно общую информацию, от простого содержимого до перенаправления посетителя на страницу с оплатой. Но что же такое сквиз пейдж?
Это подвид целевой страницы, у которых одна цель: собрать информацию о посетителе. Например, она помогает вам получить адрес электронной почты посетителя, чтобы вы могли позже поддерживать с ним связь, пока он не будет готов что-то купить.
Но зачем вам нужна сквиз пейдж? Почему бы просто не попробовать сразу совершить продажу?
Сегодня 50% отношений с покупателями - как путешествия с разными событиями, по многим каналам. Это значит, что люди, скорее всего, посетят ваш сайт несколько раз, переходя на него по разным маркетинговым каналам, до того как купят что-то или подпишутся на рассылку и станут лидами.
И в этом есть смысл, потому что люди должны сперва привыкнуть к сайту и начать ему доверять, прежде чем они достанут свою кредитку.
В онлайн-бизнесе это называется путешествием покупателя, у него есть несколько стадий, и на каждой человек ищет что-то свое.
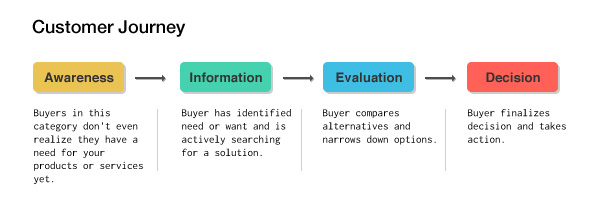
- Осведомленность: Люди в этой категории пока даже не осознают, что им нужны ваши товары или услуги. Но они начинают осознавать, что в их жизни есть пробел или проблема, для которой нужно решение.
- Информация: Теперь, когда люди поняли, что в их жизни есть подобная проблема, они начинают искать пути ее решения. Они начинают с поиска в интернете и других местах либо просматривают такие платформы, как Yelp.
- Оценка: После того как люди сравнили несколько вариантов, они сужают перечень товаров, услуг или брендов, которые им подходят.
- Решение: Когда приходит время, люди начинают интересоваться более подробной информацией и стоимостью, чтобы наконец принять решение и действовать.
В идеале для каждой и этих стадий нужно иметь по одной целевой странице и сквиз пейдж, помогая людям найти то, что они ищут, и продвигая их по поти совершения покупки.
Данные подтверждают этот подход. Согласно HubSpot, которые проанализировали более 7 000 малых бизнесов, когда компании увеличивают количество своих целевых страниц и сквиз пейджей до 10-15, они получают на 55% больше лидов.
Сквиз пейджи - основная составляющая этого подхода, особенно в самом начале “пути”, на стадиях осведомленности и размышления, потому что они дают вам возможность предложить посетителю что-то ценное, что решит его проблему, в обмен на возможность помочь ему в будущем.
Теперь, когда вы знаете, что такое сквиз пейджи и почему они важны, давайте посмотрим, как они выглядят.
3 самых важных элемента сквиз пейдж
Самые лучшие сквиз пейджи простые, аккуратные и не перегруженные в плане дизайна. Это помогает сосредоточить внимание на том, что вы предлагаете, и посетителям легко понять, что им нужно сделать, чтобы получить это предложение.
Но до того как увидеть законченный продукт, давайте изучим три элемента, на которые нужно обратить особое внимание.
1. Заголовки, на которые непреодолимо хочется кликнуть
Заголовки на сквиз пейджах - это ваше ценностное предложение вкратце. Они рассказывают в нескольких простых и эффектных словах о том, чем вы отличаетесь от других и какого ваше ценностное предложение.
Как вы можете представить, это не так просто.
Один из лучших способов научиться писать лучшие заголовки (или подытожить то, чем вы занимаетесь, в одном эффектном прдложении) - изучить мастеров своего дела. Удивительно, но онлайн - это Buzzfeed, которые ежедневно публикуют огромное количество невероятных заголовков.
Пример ниже ставит в центр и на первый ряд важную проблему (родительство), а дальше - их предложение (бесплатная новостная рассылка).
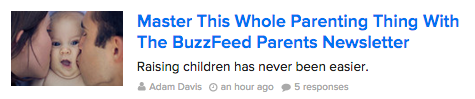
Подзаголовок также подчеркивает изначальную проблему и поясняет, почему их решение поможет.
Порядок очень важен, потому что он удерживает внимание на решении основной проблемы (а не на технических свойствах или характеристиках товаров и услуг).
2. Визуальные образы, которые выделяют ваше “геройское” предложение
В этот момент людям может быть все равно, кто вы. Вместо этого им интересно, что они получат взамен.
Это особенно касается изображений на каждой странице.
В идеале то, что вы будете использовать, должно напоминать то, что посетитель получит в обмен на информацию о себе.
Ниже - отличный пример от AdEspresso. Простой дизайн сосредотачивает все внимание на предложении. То место, куда нужно ввести свою информацию, выделено визуально.
А картинка на странице - книга - ясно показывает людям, что они получат (в конкретной, материальной форме).
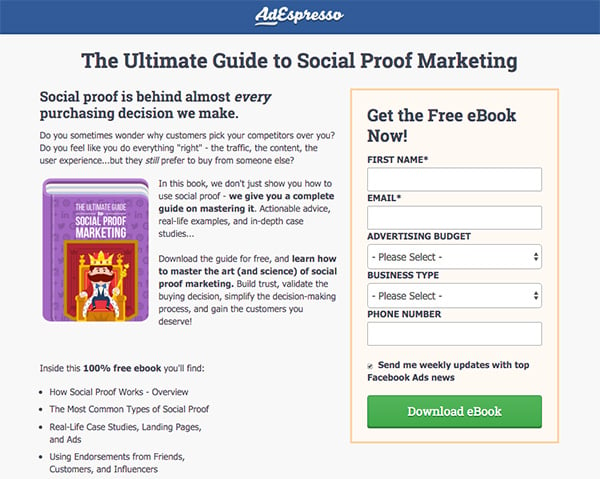
Основное изображение на сквиз пейдж также часто называют “геройским”, потому что оно помогает посетителям проецировать на себя то, какой их жизнь будет после решения проблемы (с вашей помощью).
Подумайте о том, как товары для фитнеса и потери веса показывают изображения “до” и “после”. Это действенный способ сравнить, какой чья-то жизнь была до использования продукта и какой она может стать после подписки на вас.
Эффектные изображения на сквиз пейджах демонстрируют эти изменения и помогают посетителям увидеть возможный результат.
3. Призыв к действию, оптимизированный для конверсий
Третий ключевой элемент сквиз пейдж, на который стоит обратить особое внимание, - призыв к действию.
Опять же, вся суть в простоте и минимализме. Везде, где это возможно, уберите всю лишнюю информацию и поля, не столь необходимые для конверсии.
Например, вам правда нужно знать чью-то должность для простой интернет-рассылки? Конечно нет. И людям вряд ли захочется заполнять десяток полей для чего-то настолько простого.
Эффективные призывы к действию также подчеркивают то, что посетитель получит или от чего избавится. Для конверсии важен язык, побуждающий действовать, чтобы показать, чего ждать, и убрать завесу тайны с процесса.
Например, домашняя страница SumoMe - это одна большая сквиз пейдж, когда посетитель начинает регистрироваться. На этом сайте используется призыв к действию под названием “лайтбокс”, когда после нажатия нужной кнопки остальная часть домашней страницы затемняется и все внимание пользователя сосредотачивается на регистрации.
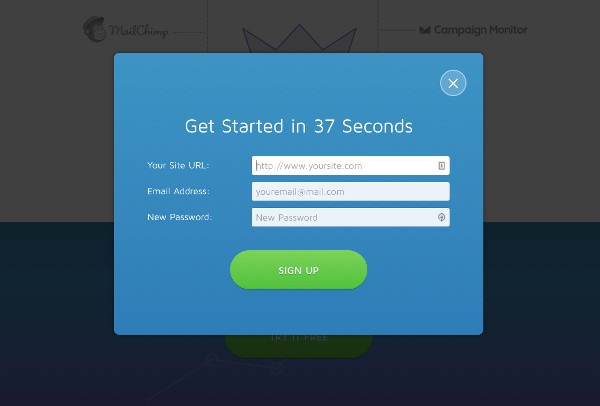
В этом примере для привлечения внимания используются слова “начните” и “37 секунд”, чтобы объяснить, насколько быстро люди могут зарегистрироваться и начать пользоваться продуктом (т.е. они быстрее решат свою проблему).
Здесь минимальное количество полей для заполнения, в которых запрашивается только основная информация для конверсии. Позже всегда можно будет получить больше информации с помощью различных техник.
А на кнопке - подходящий призыв к действию, который подчеркивает то, что люди делают на этом сайте.
Простая проверка
Сквиз пейджи созданы для сбора важной информации о посетителе.
Если вам нужны конверсии, стоит проверить, какая из них работает лучше других.
Выбрав простой и не перегруженный дизайн, проверьте свои заголовки, изображения и призывы к действию, чтобы увидеть, что больше всего влияет на конверсию.
В следующем разделе мы поговорим о некоторых программах и инструментах для более серьезной проверки, но начните с этих элементов.
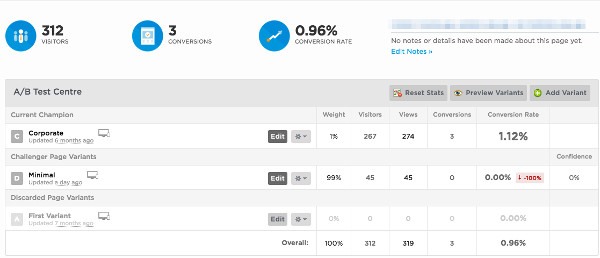
Например, можно просто продублировать первоначальную сквиз пейдж и поиграть с элементами на них. Дальше вы можете “взвесить” каждую страницу по-своему, поделив траффик (некоторые инструменты делают это автоматически).
Самое главное - вскоре вы начнете замечать закономерности (какие заголовки или изображения работают лучше всего) и сможете применять эти знания при общей работе с сайтом.
Как создавать сквиз пейджи, управлять ими и оптимизировать их
Раньше создавать сквиз пейджи с нуля было долго и муторно.
К счастью, больше это не так.
Существует ряд программ и инструментов, от простых и дешевых до тех, что посложнее, для создания, публикации сквиз пейджей и управления ими, и на это уйдет не несколько дней, а всего несколько часов.
Unbounce
Unbounce - это один из вариантов посложнее, с этой программой вы сможете по своему желанию создавать целевые страницы и проводить анализ, чтобы увеличить конверсию.
После регистрации вы получите отличные и необычные шаблоны. А мощный редактор страниц поможет вам полностью настроить страницу под себя.
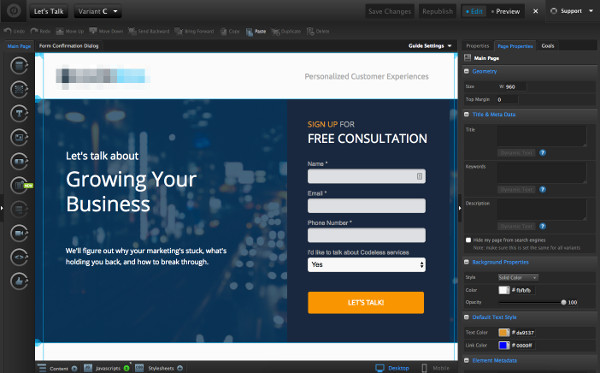
Вы также можете загрузить свои собственные целевые страницы, созданные с нуля, если у вас есть технические навыки.
Если вам нужен индивидуальный, безупречный дизайн, но не хватает навыков в дизайне, на ThemeForest вы можете найти и загрузить высококачественные шаблоны для целевых страниц Unbounce.
По умолчанию, они отображаются по времени появления на сайте. В поле “Sort by” (“отсортировать по”) можно выбрать “Best Sellers” (“бестселлеры”), и вы найдете отличные недавно загруженные шаблоны с высокими рейтингами и хорошими отзывами.
Например, в многофункциональном шаблоне FlatPack есть множество макетов целевых страниц и сквиз пейджей. Вот одна из них:

Чтобы что-то изменить в этом шаблоне, нужно просто перетащить определенный элемент. В нем 13 мокапов в формате PSD на любой вкус.
Вот еще один прекрасный шаблон целевой страницы Unbounce для стартапов. В нем современный дизайн, который выглядит самобытно и дорого.
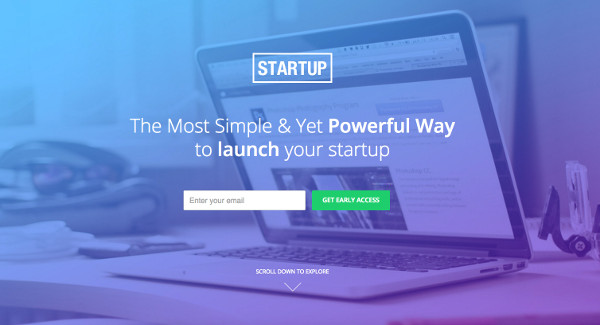
Существует даже больше шаблонов для конкретных сфер деятельности, например, Condio для работы с недвижимостью или Law Online для юридических фирм.
LeadPages
LeadPages - это еще один популярный вариант создания сквиз пейджей, которые помогают конверсии.
Можно просто перетаскивать нужные элементы на свою страницу (не заботясь о внешнем виде и удобстве использования).
Например, скажем, вам нужно добавить обратный отсчет, чтобы подчеркнуть срочность или ограниченность товара. Просто перетащите нужный элемент!
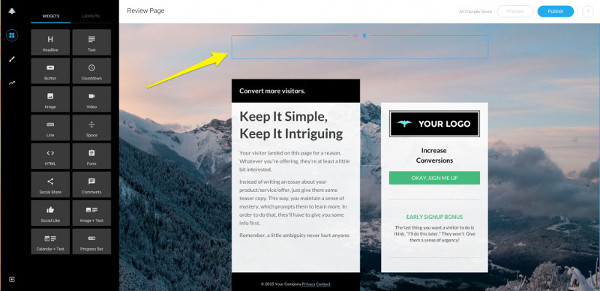
Leadpages заботятся о форматировании вместо вас, так что вам не нужно беспокоиться о том, как изменить размер элементов, чтобы они подходили цветам и бренду в общем.
Вероятно, Leadpages - это самый простой способ для создания и публикации целевых страниц. Как вы увидели, для этого не нужно уметь работать с кодом или дизайном. Все элементы зафиксированы в определенном положении, так что вы ничего не можете испортить!
Но у этой простоты использования есть и несколько недостатков. А именно - не все можно настроить так, как вам хочется. Например, нельзя изменить полностью все настройки или загрузить свою собственную страницу, как в случае с Unbounce.
WordPress
Технически и Unbounce, и LeadPages можно использовать или встраивать на сайты WordPress.
Но если вы не хотите пользоваться дополнительными программами, можно просто использовать плагин от WordPress.
В библиотеке Code Canyon - более 4 200 плагинов для WordPress, из которых можно выбрать то, что нужно вам.
Например, конструктор целевых страниц Parallax Gravity, который поможет вам создать столько целевых страниц, сколько вам необходимо. В нем есть основные функции настройки (как добавление разделов или новых изображений на страницу). А с помощью коротких кодов можно еще больше увеличить функциональность каждой страницы.
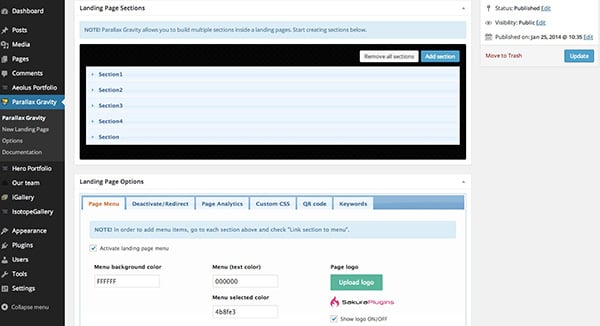
Еще одна интересная разновидность сквиз пейджей - те, которые позволяют мельком взглянуть на содержимое, показывая его образец, а чтобы увидеть больше, посетитель должен зарегистрироваться.
Плагин Opt-In Panda для WordPress упрощает этот процесс. Например, можно закрыть доступ к основному контенту (спрятав или полностью размыв его), пока посетитель не захочет его увидеть.
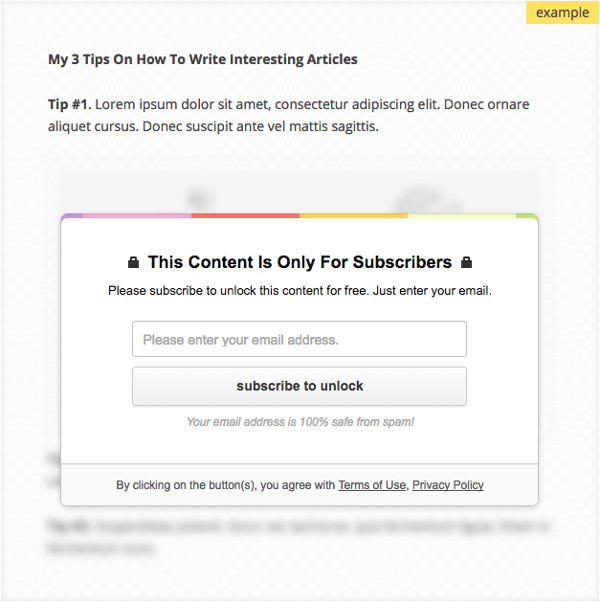
Это мощная техника, потому что вы предлагаете посетителю взглянуть на то, что он получит, а потом ограничиваете ему доступ к основной части, пока он не предоставит вам нужную информацию.
Работа со сквиз пейджами
Сквиз пейджи - это специальные целевые страницы, которые помогают вам превратить лиды в покупателей.
Вы работаете с конкретной стадией Путешествия покупателя, предлагая ему конкретное решение проблемы и направляя его в нужном направлении в нужное время.
Дизайн, не отвлекающий внимание, заголовок, изображения, призыв к действию - все это можно проанализировать, чтобы увеличить конверсию.
Можно дополнительно использовать такие инструменты, как Unbounce, LeadPages или разнообразные плагины для WordPress, чтобы быстро создать и запустить сквиз-пейдж. И это хорошо, потому что, согласно статистике, прямо сейчас ваш сайт теряет посетителей.
Сквиз пейдже помогут вам взять контроль в свои руки. Зайдите на Envato Market, чтобы найти еще больше отличных шаблонов для сквиз пейджей и начать работать с ними.
IDLE automatically squeezes large amount of lines
I've been working on a chatbot in IDLE using python. On my laptop everything works fine but on my desktop IDLE automatically squeezes the text ����♂️ This is what it looks like in IDLE. �� The text that's being squeezed are just empty lines. I've embedded the code I used to print out the empty lines below. print("\n" * 150) ���� Does anyone know how to disable it? ��
asked Jan 8, 2019 at 5:50
21 1 1 gold badge 1 1 silver badge 2 2 bronze badges
2 Answers 2
This is a new feature, still being refined. To disable, go to Options => Configure IDLE => General tab => Shell preferences => Auto-Squeeze min lines [50] and change 50 to a large count.
Double click the label to expand in place. Right click for other options.
answered Jan 8, 2019 at 19:33
Terry Jan Reedy Terry Jan Reedy
18.6k 3 3 gold badges 41 41 silver badges 54 54 bronze badges
Would be nice to disable with -1 instead of entering large count. I don't like this feature, personal opinion.
IDLE
IDLE — это интегрированная среда разработки и обучения Python.
У IDLE следующие особенности:
- реализован на 100% чистом Python с использованием набора инструментов графического интерфейса пользователя tkinter
- кросс-платформенный: работает практически одинаково в Windows, Unix и macOS
- окно оболочки Python (интерактивный интерпретатор) с раскрашиванием ввода, вывода кода и сообщений об ошибках
- многооконный текстовый редактор с несколькими отменами, раскрашиванием Python, интеллектуальным отступом, подсказками при вызове, автозавершением и другими функциями
- поиск в любом окне, замена в окнах редактора и поиск в нескольких файлах (grep)
- отладчик с постоянными точками останова, пошаговым выполнением и просмотром глобальных и локальных пространств имён
- настройки, браузеры и другие диалоги
Меню
У IDLE два основных типа окон: окно оболочки и окно редактора. Одновременно можно создать несколько окон редактора. В Windows и Linux у каждого есть собственное верхнее меню. Каждое меню, задокументированное ниже, указывает, с каким типом окна оно связано.
Окна вывода, такие как Edit => Find в файлах, являются подтипом окна редактора. В настоящее время они имеют одно и то же верхнее меню, но другой заголовок по умолчанию и контекстное меню.
В macOS есть одно меню приложений. Он динамически изменяется в соответствии с выбранным в данный момент окном. В нем есть меню IDLE, а некоторые описанные ниже элементы, перемещены в соответствии с рекомендациями Apple.
Меню «File» (оболочка и редактор)
New File Создаёт новое окно редактирования файла. Open… Открывает существующий файл с помощью диалогового окна «Open». Recent Files Открывает список последних файлов. Нажмите один раз, чтобы открыть его. Open Module… Открывает существующий модуль (ищет sys.path). Class Browser Показывает функции, классы и методы в текущем файле редактора в формате древовидной структуры. В оболочке сначала открыть модуль. Path Browser Показывает каталоги, модули, функции, классы и методы sys.path в виде древовидной структуры. Save Сохраняет текущее окно в связанный файл, если он есть. Измененные окна с момента открытия или последнего сохранения, содержат * перед и после заголовка окна. Если нет связанного файла, вместо него выполняет «Save As». Save As… Сохраняет текущее окно с помощью диалогового окна «Save As». Сохраненный файл становится новым связанным файлом для окна. Save Copy As… Сохраняет текущее окно в другой файл без изменения связанного файла. Print Window Распечатывает текущее окно на принтере по умолчанию. Close Закрывает текущее окно (предложит сохранить, если оно не сохранено). Exit Закрывает все окна и выходит из IDLE (предложит сохранить несохраненные окна).
Меню «Edit» (Оболочка и Редактор)
Undo Отменяет последнее изменение в текущем окне. Максимально может быть отменено 1000 изменений. Redo Повторяет последнее отмененное изменение в текущем окне. Cut Копирует выделение в общесистемный буфер обмена; затем удаляет выделение. Copy Копирует выделение в общесистемный буфер обмена. Paste Вставляет содержимое общесистемного буфера обмена в текущее окно.
Функции буфера обмена также доступны в контекстных меню.
Select All Выделяет все содержимое текущего окна. Find… Открывает диалоговое окно поиска с множеством параметров Find Again Повторяет последний поиск, если он есть. Find Selection Поиск текущей выбранной строки, если она есть. Find in Files… Открывает диалоговое окно поиска файлов. Помещает результаты в новое окно вывода. Replace… Открывает диалоговое окно поиска и замены. Go to Line Перемещает курсор в начало запрошенной строки, и выполняет отображение строки. Запрос после конца файла перемещается в конец. Снимает выделение, и обновляет статус строки и столбца. Show Completions Открывает прокручиваемый список, позволяющий выбрать существующие имена. См. Завершения в разделе «Редактирование и навигация» ниже. Expand Word Расширяет введенный вами префикс, чтобы он соответствовал полному слову в том же окне; повторяет, чтобы получить другое расширение. Show call tip После незакрытой скобки для функции открывает маленькое окно с подсказками параметров функции. См. Подсказки по вызову в разделе редактирования и навигации ниже. Show surrounding parens Подсвечивает окружающие скобки.
Меню «Format» (только окно редактора)
Indent Region Сдвигает выделенные строки вправо на ширину отступа (по умолчанию 4 пробела). Dedent Region Сдвигает выделенные строки влево на ширину отступа (по умолчанию 4 пробела). Comment Out Region Вставляет ## перед выделенными строками. Uncomment Region Удалить ведущие # или ## из выбранных строк. Tabify Region Превращает ведущие пробелы в табы. (Примечание: мы рекомендуем использовать 4 пробела для отступа кода Python.) Untabify Region Превращает все табы в правильное количество пробелов. Toggle Tabs Открывает диалоговое окно для переключения между отступами с пробелами и табуляциями. New Indent Width Открывает диалоговое окно для изменения ширины отступа. По умолчанию в Python сообществе принято 4 пробела. Format Paragraph Переформатирует текущий абзац, разделенный пустой строкой, в блоке комментариев или многострочной строки или выделенной строки в строке. Все строки в абзаце будут отформатированы так, чтобы было меньше N столбцов, где N по умолчанию равно 72. Strip trailing whitespace Удаляет завершающий пробел и другие пробельные символы после последнего непробельного символа строки, применяя str.rstrip к каждой строке включая строки в многострочных строках. За исключением окон оболочки удаляет лишние символы новой строки в конце файла.
Меню «Run» (только окно редактора)
Run Module Выполняет Проверку модуля . Если ошибки нет, перезапускает оболочку, чтобы очистить среду, затем запускает модуль. Вывод отображается в Shell окне. Обратите внимание, что для вывода требуется использование print или write . Когда выполнение завершено, оболочка сохраняет фокус и отображает подсказку. На этом этапе можно в интерактивном режиме исследовать результат выполнения. Это похоже на выполнение файла с python -i file из командной строки. Run… Customized То же, что и Запуск модуля , но запускает модуль с измененными настройками. Аргументы командной строки расширяют sys.argv , как если бы он был передан в командной строке. Модуль можно запустить в Shell без перезагрузки. Check Module Переформатирует синтаксис модуля, открытого в данный момент в окне Editor. Если модуль не был сохранен IDLE либо предложит пользователю сохранить, либо автосохранение, выбранное на вкладке «General» диалогового окна «Settings». Если есть синтаксическая ошибка, примерное местонахождение указано в Editor окне. Python Shell Открывает или активирует Python окно Shell.
Меню «Shell» (только окно оболочки)
View Last Restart Прокручивает окно оболочки до последнего перезапуска Shell. Restart Shell Перезапускает оболочку, чтобы очистить среду и сбросить отображение и обработку исключений. Previous History Циклический просмотр более ранних команд в истории, которые соответствуют текущей записи. Next History Циклический просмотр более поздних команд в истории, которые соответствуют текущей записи. Interrupt Execution Останавливает работающую программу.
Меню «Debug» (только окно оболочки)
Go to File/Line Перейти на текущую строку с курсором и строку выше для имени файла и номера строки. Если он найден, открывает файл, если он ещё не открыт, далее отображает строку. Используйте для просмотра исходных строк, на которые есть ссылки в трассировке исключений и строки, найденные функцией «Find in Files». Также доступно в контекстном меню окна Shell и окна Output. Debugger (toggle) При активации будет выполняться код, введенный в оболочке или запущенный из редактора под отладчиком. В редакторе точки останова могут быть установлены с учётом контекста меню. Данная функция все ещё не завершена и несколько экспериментальна. Stack Viewer Показывает трассировку стека последнего исключения в виджете дерева, с доступом к локальным и глобальным. Stack Viewer Включает автоматическое открытие средства просмотра стека при необработанном исключении.
Меню «Options» (оболочка и редактор)
Configure IDLE Открывает диалоговое окно конфигурации и изменяет настройки для следующего: шрифты, отступы, сочетания клавиш, цветовые темы текста, окна запуска и размер, дополнительные источники справки и расширения. В macOS открывает файл диалоговое окно Preferences, выбрав Preferences в приложении меню. Подробнее см. Настройку предпочтений в разделе «Справка и настройки».
Большинство параметров конфигурации применяются ко всем окнам или ко всем будущим окнам. Пункты опций ниже применимы только к активному окну.
Show/Hide Code Context (Editor Window only) Открывает панель в верхней части окна редактирования, показывающая контекст блока кода, который прокручивается над верхней частью окна. См. Контекст кода в разделе «Редактирование и навигация» далее. Show/Hide Line Numbers (Editor Window only) Открывает столбец слева от окна редактирования, в котором отображается число каждой строки текста. По умолчанию выключено, это можно изменить в файле предпочтения (см. Настройка предпочтений ). Zoom/Restore Height Переключает окно между нормальным размером и максимальной высотой. Начальный размер по умолчанию 40 строк по 80 символов, если не изменено на вкладке «General» Configure диалогового окна IDLE. Максимальная высота экрана определяется мгновенное развертывание окна при первом увеличении экрана. Изменение настроек экрана может сделать сохраненную высоту недействительной. Данный переключатель имеет никакого эффекта, когда окно развернуто.
Меню «Window» (оболочка и редактор)
Перечисляет имена всех открытых окон; выбрать один, чтобы вывести его на передний план (при необходимости деиконизируя его).
Меню «Help» (Shell и Editor)
About IDLE Показывает версию, авторские права, лицензию, благодарности и многое другое. IDLE Help Показывает данный документ IDLE с подробным описанием опций меню, базового редактирования, навигации и другие советы. Python Docs Предоставляет доступ к локальной документации Python, если она установлена, или запускает браузер открыв сайт с актуальной документацией по Python. Turtle Demo Запускает демонстрационный модуль черепахи с примером кода Python и рисунками черепахи.
Здесь можно добавить дополнительные источники справки с помощью диалогового окна «Configure IDLE» на вкладке «General». Дополнительные сведения о пунктах меню «Help» см. в подразделе Справка ниже.
Контекстные меню
Открывает контекстное меню, щелкнув правой кнопкой мыши в окне (удерживая нажатой клавишу Control в macOS). У контекстного меню есть стандартные функции буфера обмена и в меню «Edit».
Cut Копирует выделение в общесистемный буфер обмена; затем удаляет выделение. Copy Копирует выделение в общесистемный буфер обмена. Paste Вставляет содержимое общесистемного буфера обмена в текущем окне.
У окон редактора также есть функции точек останова. Строки с установленной точкой останова помечаются специальным образом. Точки останова действуют только при работе под отладчиком. Точки останова для файла сохраняются в пользовательском каталоге .idlerc .
Set Breakpoint Устанавливает точку останова на текущей строке. Clear Breakpoint Очищает точку останова на данной строке.
Окна Shell и Output также содержат следующее:
Go to file/line То же, что и в меню отладки.
Окно Shell также содержит средство сжатия вывода, рассмотренное в подразделе Окно оболочки Python далее.
Squeeze Если курсор находится над строкой вывода, вставляет весь вывод между кодом выше и подсказкой ниже до метки «Squeezed text».
Редактирование и навигация
Окна редактора
IDLE может открывать окна редактора при запуске, в зависимости от настроек и способа запуска IDLE. После этого используйте меню «File». Для данного файла может быть только одно открытое окно редактора.
Строка заголовка содержит имя файла, полный путь и версию Python и IDLE, в которых запущено окно. Строка состояния содержит номер строки («Ln») и номер столбца («Col»). Номера строк начинаются с 1; номера столбцов с 0.
IDLE предполагает, что файлы с известным расширением .py* содержат код Python, а другие файлы — нет. Выполняет код Python с помощью меню «Run».
Привязки клавиш
В этом разделе «C» относится к клавише Control в Windows и Unix и клавише Command в macOS.
- Backspace удаляет слева; Del удаляет вправо
- C-Backspace удаляет слово слева; C-Del удаляет слово справа
- Клавиши со стрелками и Page Up / Page Down для перемещения
- C-LeftArrow и C-RightArrow перемещаются по словам
- Home / End переходит к началу/концу строки
- C-Home / C-End переходит к началу/концу файла
- Некоторые полезные привязки Emacs унаследованы от Tcl/Tk:
- C-a начало строки
- C-e конец строки
- Строка уничтожения C-k (но не помещается в буфер обмена)
- C-l центральное окно вокруг точки вставки
- C-b переходит на один символ назад без удаления (обычно для этого также можно использовать клавишу курсора)
- C-f переходит на один символ вперед без удаления (обычно для этого также можно использовать клавишу курсора)
- C-p переходит на одну строку вверх (обычно для этого также можно использовать клавишу курсора)
- C-d удаляет следующий символ
Стандартные сочетания клавиш (например, C-c для копирования и C-v для вставки) могут работать. Привязки клавиш выбираются в диалоговом окне «Configure IDLE».
Автоматический отступ
После оператора открытия блока следующая строка имеет отступ в 4 пробела (в окне Python Shell на один таб). После определённых ключевых слов (break, return и т. д.) следующая строка содержит отступ. В начальном отступе Backspace удаляет до 4 пробелов, если они есть. Tab вставляет пробелы (в окне Python Shell один таб), количество зависит от ширины отступа. В настоящее время табы ограничены четырьмя пробелами из-за ограничений Tcl/Tk.
См. также команды indent/dedent области на странице Меню форматирования .
Завершения
Завершения предоставляются, когда они запрошены и доступны для имён модулей, атрибутов классов, функций или имён файлов. Каждый запрашиваемый метод отображает поле завершения с существующими именами. (Исключение см. ниже для заполнения табов.) Для любого поля изменяет заполняемое имя и элемент, выделенный в поле, введя и удалив символы; нажав клавиши Up , Down , PageUp , PageDown , Home и End ; и одним щелчком внутри поля. Закрывает окно клавишами Escape , Enter и двойными клавишами Tab или щелчками за пределами поля. Двойной щелчок внутри поля выбирает и закрывает.
Один из способов открыть поле — ввести ключевой символ и подождать заранее заданный интервал. По умолчанию — 2 секунды; настройте его в диалоге настроек. (Чтобы предотвратить автоматические всплывающие окна, устанавливает задержку на большое количество миллисекунд, например 100000000.) Для импортированных имён модулей или атрибутов класса или функции введите «.». Для имён файлов в корневом каталоге введите os.sep или os.altsep сразу после открывающей кавычки. (В Windows можно сначала указать диск.) Переходит в подкаталоги, введя имя каталога и разделитель.
Вместо того чтобы ждать или после закрытия окна, немедленно открывает окно завершения с помощью команды «Show Completions» в меню «Edit». Горячая клавиша по умолчанию — C-space . Если перед открытием коробки ввести префикс для нужного имени, первое совпадение или близкое совпадение становится видимым. Результат такой же, как если бы кто-то ввел префикс после отображения окна. Показывает завершения после того, как кавычка завершает имена файлов в текущем каталоге, а не в корневом каталоге.
Нажатие Tab после префикса обычно имеет тот же эффект, что и «Show Completions». (Без префикса он — отступ.) Однако, если есть только одно совпадение с префиксом, это совпадение немедленно добавляется в текст редактора, не открывая поле.
Вызов «Show Completions» или нажатие Tab после префикса вне строки и без предшествующего «.». открывает поле с ключевыми словами, встроенными именами и доступными именами на уровне модуля.
При редактировании кода в редакторе (в отличие от Shell) увеличивает доступные имена на уровне модулей, запустив свой код и не перезапуская Shell после него. Это особенно полезно после добавления импорта в начало файла. Это также увеличивает количество возможных завершений атрибутов.
Поля завершения изначально исключают имена, начинающиеся с «_» или, для модулей, не включенные в «__all__». Доступ к скрытым именам можно получить, набрав «_» после «.» либо до, либо после открытия поля.
Подсказки
Подсказка отображается автоматически при вводе ( после имени доступной функции. Выражение имени функции может включать точки и нижние индексы. Подсказка остаётся до тех пор, пока по ней не будет нажат щелчок, курсор не будет перемещен за пределы области аргумента или не будет введено ) . Всякий раз, когда курсор находится в части аргумента определения, выберите «Edit» и «Show Call Tip» в меню или введите его ярлык, чтобы отобразить подсказку.
Подсказка состоит из сигнатуры функции и строки документации до первой пустой строки последней или до пятой непустой строки. (Некоторые встроенные функции не имеют доступной сигнатуры.) «/» или «*» в сигнатуре указывает, что предшествующие или последующие аргументы передаются только по положению или имени (ключевому слову). Детали могут быть изменены.
В Shell доступные функции зависят от того, какие модули были импортированы в пользовательский процесс, в том числе импортированные самим Idle, и какие определения были запущены с момента последнего перезапуска.
Например, перезапустите Shell и введите itertools.count( . Подсказка появляется, потому что Idle импортирует itertools в пользовательский процесс для собственного использования. (Это может измениться.) Введите turtle.write( , и ничего не появится. Простой сам по себе не импортирует turtle. Вход в меню и ярлык тоже ничего не делают. Введите import turtle . После этого turtle.write( отобразит всплывающую подсказку.
В редакторе операторы импорта не действуют до тех пор, пока файл не будет запущен. Может потребоваться запустить файл после написания операторов импорта, после добавления определений функций или после открытия существующего файла.
Контекст кода
В окне содержащем код Python редактора, можно переключать контекст кода, чтобы отобразить или скрыть панель в верхней части окна. При отображении данная панель замораживает начальные строки для блочного кода, например начинающиеся с ключевых слов class , def или if , которые в противном случае прокручивались бы вне поля зрения. Размер панели будет увеличиваться и уменьшаться по мере необходимости, чтобы отображать все текущие уровни контекста, вплоть до максимального количества строк, определённого в диалоговом окне «Configure IDLE» (которое по умолчанию равно 15). Если текущих строк контекста нет, а функция включена, будет отображаться одна пустая строка. Щелчок по строке в контекстной панели переместит эту строку в верхнюю часть редактора.
Цвета текста и фона контекстной панели можно настроить на вкладке «Highlights» в диалоговом окне «Configure IDLE».
Окно Shell Python
С оболочкой IDLE можно вводить, редактировать и вызывать завершенные операторы. Большинство консолей и терминалов одновременно работают только с одной физической строкой.
Когда кто-то вставляет код в Shell, он не компилируется и, возможно, не выполняется до тех пор, пока не будет найден Return . Сначала можно отредактировать вставленный код. Если вставить в Shell более одного оператора, результатом будет SyntaxError , когда несколько операторов скомпилированы, как если бы они были одним.
Функции редактирования, описанные в предыдущих подразделах, работают при интерактивном вводе кода. Окно оболочки IDLE также реагирует на следующие клавиши.
- C-c прерывает выполнение команды
- C-d отправляет конец файла; закрывает окно, если введено в приглашении >>>
- Alt-/ (Расширенное слово) также удобен для сокращения набора текста История команд
- Alt-p извлекает предыдущую команду, соответствующую тому, что вы набрали. В macOS используйте C-p .
- Alt-n получает следующее. В macOS используйте C-n .
- Return во время любой предыдущей команды извлекает эту команду.
Цвета текста
В Idle по умолчанию текст отображается черным цветом на белом фоне, но при этом текст окрашивается в специальные цвета. Для оболочки это вывод оболочки, ошибка оболочки, вывод пользователя и ошибка пользователя. Для кода Python в командной строке или в редакторе это ключевые слова, имена встроенных классов и функций, имена после class и def , строки и комментарии. Для любого текстового окна это курсор (если присутствует), найденный текст (если возможно) и выделенный текст.
Раскрашивание текста выполняется в фоновом режиме, поэтому иногда виден неокрашенный текст. Чтобы изменить цветовую схему, используйте вкладку Highlighting диалогового окна Configure IDLE. Отметка строк точки останова отладчика в редакторе и текста во всплывающих окнах и диалогах не настраивается пользователем.
Запуск и выполнение кода
При запуске с параметром -s IDLE выполнит файл, на который ссылаются переменные среды IDLESTARTUP или PYTHONSTARTUP . IDLE сначала проверяет IDLESTARTUP ; если присутствует IDLESTARTUP , запускается указанный файл. Если IDLESTARTUP отсутствует, IDLE проверяет наличие PYTHONSTARTUP . Файлы, на которые ссылаются данные переменные среды, являются удобными местами для хранения часто используемых из оболочки IDLE функций, или для выполнения операторов импорта для импорта общих модулей.
Кроме того, Tk также загружает файл запуска, если он присутствует. Обратите внимание, что файл Tk загружается безоговорочно. Данный дополнительный файл имеет номер .Idle.py и ищется в домашнем каталоге пользователя. Операторы в этом файле будут выполняться в пространстве имён Tk, поэтому данный файл не подходит для импорта функций, которые будут использоваться из оболочки Python IDLE.
Использование командной строки
idle.py [-c command] [-d] [-e] [-h] [-i] [-r file] [-s] [-t title] [-] [arg] . -c command запустить команду в окне оболочки -d включить отладчик и открыть окно оболочки -e открыть окно редактора -h распечатать справочное сообщение с допустимыми комбинациями и выйти -i открыть окно оболочки -r file запустить файл в окне оболочки -s сначала запустится $IDLESTARTUP или $PYTHONSTARTUP в окне оболочки -t title установить заголовок окна оболочки - запустить stdin в оболочке (- должен быть последним параметром перед аргументами)
Если есть аргументы:
- Если используется - , -c или r , все аргументы помещаются в sys.argv[1. ] , а sys.argv[0] устанавливается в '' , '-c' или '-r' . Окно редактора не открывается, даже если это установлено по умолчанию в диалоговом окне «Options».
- В противном случае аргументы — это файлы, открытые для редактирования, а sys.argv отражает аргументы, переданные самой IDLE.
Ошибка запуска
IDLE использует сокет для связи между процессом пользовательского интерфейса IDLE и процессом выполнения пользовательского кода. Соединение должно устанавливаться при каждом запуске или перезапуске Shell. (Последнее обозначено разделительной линией с надписью «RESTART»). Если пользовательскому процессу не удается подключиться к процессу пользовательского интерфейса, он отображает окно ошибки Tk с сообщением «невозможно подключиться (cannot connect)», которое направляет пользователя сюда. Затем он выходит.
Распространенной причиной сбоя является написанный пользователем файл с тем же именем, что и у модуля стандартной библиотеки, например random.py и tkinter.py. Когда такой файл находится в том же каталоге, что и файл, который должен быть запущен, IDLE не может импортировать файл stdlib. Текущее исправление заключается в переименовании файла пользователя.
Хотя реже, чем в прошлом, антивирусная программа или брандмауэр могут прервать соединение. Если программу нельзя научить разрешать соединение, то для работы IDLE её необходимо отключить. Безопасно разрешать это внутреннее соединение, потому что никакие данные не видны на внешних портах. Аналогичной проблемой является неправильная конфигурация сети, которая блокирует соединения.
Проблемы с установкой Python иногда останавливают IDLE: несколько версий могут конфликтовать, или для одной установки может потребоваться доступ администратора. Если кто-то отменяет конфликт или не может или не хочет работать от имени администратора, проще всего полностью удалить Python и начать заново.
Зомби процесс pythonw.exe может быть проблемой. В Windows используйте диспетчер задач, чтобы проверить его и остановить, если он есть. Иногда перезагрузка, инициированная сбоем программы или прерыванием клавиатуры (control-C), может не подключиться. Закрытие окна ошибки или использование «Restart Shell» в меню «Shell» может решить временную проблему.
При первом запуске IDLE пытается прочитать файлы конфигурации пользователя в ~/.idlerc/ (~ — домашний каталог). В случае возникновения проблемы должно появиться сообщение об ошибке. Не говоря уже о случайных сбоях диска, этого можно избежать, никогда не редактируйте файлы вручную. Вместо этого используйте диалоговое окно конфигурации в разделе «Options». Если в файле конфигурации пользователя есть ошибка, лучшим решением может быть его удаление и запуск диалога настроек заново.
Если IDLE завершается без сообщения и не был запущен из консоли, попробуйте запустить его из консоли или терминала ( python -m idlelib ) и посмотрите, не приведёт ли это к появлению сообщения об ошибке.
Запуск пользовательского кода
За редкими исключениями, результат выполнения кода Python с помощью IDLE должен быть таким же, как и при выполнении того же кода методом по умолчанию, непосредственно с помощью Python в текстовой системной консоли или окне терминала. Однако другой интерфейс и работа иногда влияют на видимые результаты. Например, sys.modules начинается с большего количества записей, а threading.activeCount() возвращает 2 вместо 1.
По умолчанию IDLE запускает пользовательский код в отдельном процессе ОС, а не в процессе пользовательского интерфейса, который запускает оболочку и редактор. В процессе выполнения он заменяет sys.stdin , sys.stdout и sys.stderr объектами, которые получают ввод и отправляют вывод в окно Shell. Исходные значения, хранящиеся в sys.__stdin__ , sys.__stdout__ и sys.__stderr__ , не изменяются, но могут быть None .
Когда Shell получает фокус, он управляет клавиатурой и экраном. Обычно это прозрачно, но обращающиеся напрямую к клавиатуре и экрану функции, работать не будут. К ним относятся специфичные для системы функции, которые определяют, была ли нажата клавиша, и если да, то какая.
Стандартные замены потоков IDLE не наследуются подпроцессами, созданными в процессе выполнения, будь то непосредственно пользовательский код или модули, такие как multiprocessing. Если такой подпроцесс использует input из sys.stdin или print или write в sys.stdout или sys.stderr, IDLE следует запустить в окне командной строки. Затем вторичный подпроцесс будет присоединен к этому окну для ввода и вывода.
Код IDLE, работающий в процессе выполнения, добавляет фреймы в стек вызовов, которых в противном случае там не было бы. IDLE переносит sys.getrecursionlimit и sys.setrecursionlimit , чтобы уменьшить влияние дополнительных фреймов стека.
Если sys сбрасывается кодом пользователя, например, importlib.reload(sys) , изменения IDLE теряются, а ввод с клавиатуры и вывод на экран не будут работать правильно.
Когда пользовательский код вызывает SystemExit либо напрямую, либо путём вызова sys.exit, IDLE вместо выхода возвращается к приглашению оболочки.
Пользовательский вывод в Shell
Когда программа выводит текст, результат определяется соответствующим устройством вывода. Когда IDLE выполняет пользовательский код, sys.stdout и sys.stderr подключаются к области отображения оболочки IDLE. Некоторые из его функций унаследованы от базового виджета Tk Text. Другие являются запрограммированными дополнениями. Там, где это важно, Shell предназначена для разработки, а не для производственного запуска.
Например, Shell никогда не выбрасывает выходные данные. Программа, которая отправляет неограниченный вывод в Shell, в конечном итоге заполнит память, что приведёт к ошибке памяти. Напротив, некоторые системные текстовые окна сохраняют только последние n строк вывода. Консоль Windows, например, сохраняет настраиваемое пользователем от 1 до 9999 строк, по умолчанию 300.
Виджет Tk Text и, следовательно, оболочка IDLE отображает символы (кодовые точки) в подмножестве Юникод BMP (Basic Multilingual Plane). Какие символы отображаются с правильным глифом, а какие с замещающим полем, зависит от операционной системы и установленных шрифтов. Символы табуляции заставляют следующий текст начинаться после следующей позиции табуляции. (Они встречаются каждые 8 «символов»). Символы новой строки заставляют следующий текст появляться на новой строке. Другие управляющие символы игнорируются или отображаются как пробел, прямоугольник или что-то ещё, в зависимости от операционной системы и шрифта. (Перемещение текстового курсора по такому выводу с помощью клавиш со стрелками может привести к неожиданному поведению пробелов.)
>>> s = 'a\tb\a\x02>\r>\bc\nd' # Ввод 22 символа. >>> len(s) 14 >>> s # Показывает repr(s) 'a\tb\x07\x08c\nd' >>> print(s, end='') # Показывает как есть # Результат зависит от операционной системы и шрифта. Проверьте это.
Функция repr используется для интерактивного отображения значений выражений. Она возвращает измененную версию входной строки, в которой управляющие коды, некоторые кодовые точки BMP и все кодовые точки, отличные от BMP, заменены управляющими кодами. Как показано выше, она позволяет идентифицировать символы в строке независимо от того, как они отображаются.
Нормальный вывод и вывод ошибок обычно хранятся отдельно (в отдельных строках) от ввода кода и друг от друга. Каждый из них получает разные цвета подсветки.
Для трассировки SyntaxError обычная отметка «^» в месте обнаружения ошибки заменяется выделением текста цветом ошибки. Когда запускаемый из файла код, вызывает другие исключения, можно щелкнуть правой кнопкой мыши строку трассировки, чтобы перейти к соответствующей строке в IDLE редакторе. Файл будет открыт при необходимости.
В Shell есть специальное средство для сжатия строк вывода до метки «Squeezed text». Это делается автоматически для вывода на N строк (N = 50 по умолчанию). N можно изменить в разделе PyShell на странице «General» диалогового окна «Settings». Вывод с меньшим количеством строк можно сжать, щелкнув правой кнопкой мыши на выводе. Это могут быть полезные строки, достаточно длинные, чтобы замедлить прокрутку.
Сжатый вывод расширяется на месте двойным щелчком метки. Его также можно отправить в буфер обмена или отдельное окно просмотра, щелкнув метку правой кнопкой мыши.
Разработка tkinter приложений
IDLE намеренно отличается от стандартного Python, чтобы облегчить разработку программ tkinter. Введите import tkinter as tk; root = tk.Tk() в стандартном Python, и ничего не появится. Введите то же самое в IDLE, и появится окно tk. В стандартном Python нужно также ввести root.update() , чтобы увидеть окно. IDLE делает то же самое в фоновом режиме примерно 20 раз в секунду, т. е. примерно каждые 50 миллисекунд. Затем наберите b = tk.Button(root, text='button'); b.pack() . Опять же, в стандартном Python ничего не меняется, пока не будет root.update() .
Большинство программ tkinter запускают root.mainloop() , который обычно не возвращается, пока приложение tk не будет уничтожено. Если программа запускается с python -i или из редактора IDLE, приглашение оболочки >>> не появляется до тех пор, пока не вернется mainloop() , после чего взаимодействовать не с чем.
При запуске tkinter программы из редактора IDLE можно закомментировать вызов mainloop. Затем вы сразу же получаете приглашение оболочки и можете взаимодействовать с живым приложением. Просто нужно не забыть снова включить вызов mainloop при работе в стандартном Python.
Запуск без подпроцесса
По умолчанию IDLE выполняет пользовательский код в отдельном подпроцессе через сокет, который использует внутренний петлевой (loopback) интерфейс. Это соединение не видно извне, и данные не отправляются и не принимаются из Интернета. Если программное обеспечение брандмауэра все равно жалуется, вы можете игнорировать его.
Если попытка установить подключение к сокету не удалась, Idle уведомит вас об этом. Такие сбои иногда носят временный характер, но если они сохраняются, проблема может заключаться либо в брандмауэре, блокирующем соединение, либо в неправильной настройке системы. Пока проблема не устранена, можно запускать Idle с опцией командной строки -n .
Если IDLE запущен с параметром командной строки -n , он будет работать в одном процессе и не будет создавать подпроцесс, который запускает сервер выполнения RPC Python. Это может быть полезно, если Python не может создать подпроцесс или RPC интерфейс сокета на вашей платформе. Однако в этом режиме пользовательский код не изолирован от самого IDLE. Кроме того, среда не перезапускается, когда выбрано «Run/Run Module» (F5). Если ваш код был изменён, вы должны reload() затронутые модули и повторно импортировать любые определённые элементы (например, из foo import baz), чтобы изменения вступили в силу. По этим причинам предпочтительнее запускать IDLE с подпроцессом по умолчанию, если это вообще возможно.
Не рекомендуется, начиная с версии 3.4.
Помощь и предпочтения
Источники помощи
Пункт меню «Help» «IDLE Help» отображает отформатированную html-версию главы IDLE Справочника по библиотеке. Результат в текстовом окне tkinter, доступном только для чтения, близок к тому, что можно увидеть в браузере. Перемещайтесь по тексту с помощью колесика мыши, полосы прокрутки или клавиш со стрелками вверх и вниз, удерживая их нажатыми. Или нажмите кнопку TOC (Оглавление) и выбрать заголовок раздела в открывшемся окне.
Пункт меню справки «Python Docs» открывает обширные источники справки, включая учебные пособия, доступные по адресу docs.python.org/x.y , где «x.y» — это текущая версия Python. Если в вашей системе есть автономная копия документов (это может быть вариант установки), вместо этого будет открыта она.
Выбранные URL-адреса могут быть добавлены или удалены из меню справки в любое время с помощью табы «General» диалогового окна «Configure IDLE».
Установка предпочтений
Параметры шрифта, подсветка, клавиши и общие параметры можно изменить с помощью пункта «Configure IDLE» в меню «Option». Пользовательские настройки, отличные от настроек по умолчанию, сохраняются в каталоге .idlerc в домашнем каталоге пользователя. Проблемы, вызванные плохими файлами конфигурации пользователя, решаются путём редактирования или удаления одного или нескольких файлов в .idlerc .
На вкладке «Font» см. пример текста, в котором показано влияние начертания и размера шрифта на несколько символов на разных языках. Отредактируйте образец, чтобы добавить других символов, представляющих личный интерес. Используйте образец для выбора моноширинных шрифтов. Если у определённых символов есть проблемы в Shell или редакторе, добавьте их в начало образца и попробуйте изменить сначала размер, а затем шрифт.
На вкладке «Highlights and Keys» выберите встроенную или пользовательскую цветовую тему и множество клавиш. Чтобы использовать более новую встроенную цветовую тему или набор клавиш со старыми IDLE, сохранить их как новую пользовательскую тему или набор клавиш, и они будут доступны для более старых IDLE.
IDLE на macOS
В разделе «System Preferences: Dock» можно установить «Prefer tabs when opening documents» на «Always». Данный параметр несовместим с инфраструктурой графического интерфейса пользователя tk/tkinter, используемой IDLE, и нарушает некоторые функции IDLE.
Расширения
IDLE содержит средство расширения. Настройки для расширений можно изменить на вкладке «Extensions» диалогового окна настроек. Дополнительную информацию смотрите в начале файла config-extensions.def в каталоге idlelib. Единственным текущим расширением по умолчанию является zzdummy, пример также используется для тестирования.